 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Color Palette Modeling for Lossless Screen Content Compression
Paper and Code
Jan 09, 2024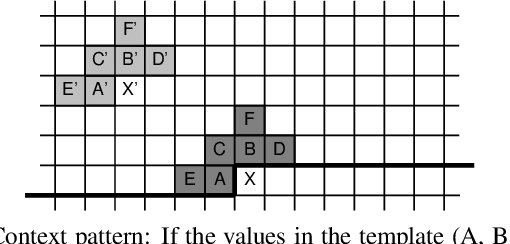
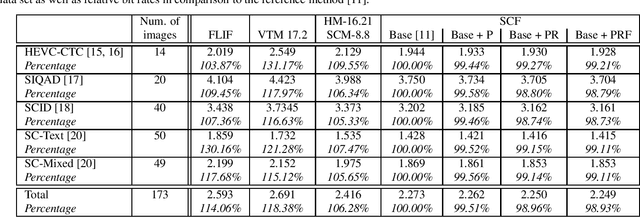
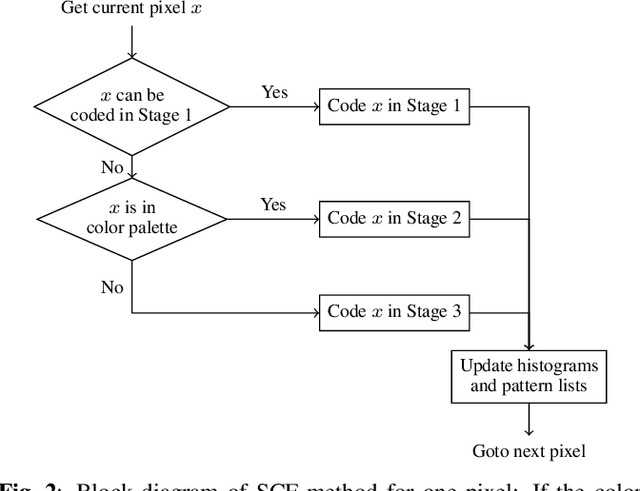
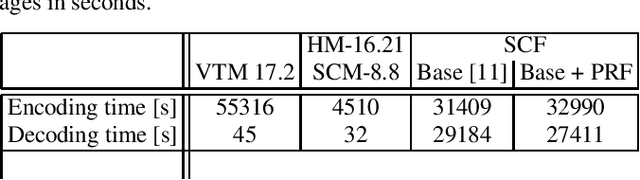
Soft context formation is a lossless image coding method for screen content. It encodes images pixel by pixel via arithmetic coding by collecting statistics for probability distribution estimation. Its main pipeline includes three stages, namely a context model based stage, a color palette stage and a residual coding stage. Each subsequent stage is only employed if the previous stage can not be applied since necessary statistics, e.g. colors or contexts, have not been learned yet. We propose the following enhancements: First, information from previous stages is used to remove redundant color palette entries and prediction errors in subsequent stages. Additionally, implicitly known stage decision signals are no longer explicitly transmitted. These enhancements lead to an average bit rate decrease of 1.07% on the evaluated data. Compared to VVC and HEVC, the proposed method needs roughly 0.44 and 0.17 bits per pixel less on average for 24-bit screen content images, respectively.