 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Acoustic Audience Feedback in Large Virtual Events
Oct 27, 2023

The COVID-19 pandemic shifted many events in our daily lives into the virtual domain. While virtual conference systems provide an alternative to physical meetings, larger events require a muted audience to avoid an accumulation of background noise and distorted audio. However, performing artists strongly rely on the feedback of their audience. We propose a concept for a virtual audience framework which supports all participants with the ambience of a real audience. Audience feedback is collected locally, allowing users to express enthusiasm or discontent by selecting means such as clapping, whistling, booing, and laughter. This feedback is sent as abstract information to a virtual audience server. We broadcast the combined virtual audience feedback information to all participants, which can be synthesized as a single acoustic feedback by the client. The synthesis can be done by turning the collective audience feedback into a prompt that is fed to state-of-the-art models such as AudioGen. This way, each user hears a single acoustic feedback sound of the entire virtual event, without requiring to unmute or risk hearing distorted, unsynchronized feedback.
Dynamic Simplex: Balancing Safety and Performance in Autonomous Cyber Physical Systems
Feb 20, 2023



Learning Enabled Components (LEC) have greatly assisted cyber-physical systems in achieving higher levels of autonomy. However, LEC's susceptibility to dynamic and uncertain operating conditions is a critical challenge for the safety of these systems. Redundant controller architectures have been widely adopted for safety assurance in such contexts. These architectures augment LEC "performant" controllers that are difficult to verify with "safety" controllers and the decision logic to switch between them. While these architectures ensure safety, we point out two limitations. First, they are trained offline to learn a conservative policy of always selecting a controller that maintains the system's safety, which limits the system's adaptability to dynamic and non-stationary environments. Second, they do not support reverse switching from the safety controller to the performant controller, even when the threat to safety is no longer present. To address these limitations, we propose a dynamic simplex strategy with an online controller switching logic that allows two-way switching. We consider switching as a sequential decision-making problem and model it as a semi-Markov decision process. We leverage a combination of a myopic selector using surrogate models (for the forward switch) and a non-myopic planner (for the reverse switch) to balance safety and performance. We evaluate this approach using an autonomous vehicle case study in the CARLA simulator using different driving conditions, locations, and component failures. We show that the proposed approach results in fewer collisions and higher performance than state-of-the-art alternatives.
Evaluation of Video Coding for Machines without Ground Truth
May 13, 2022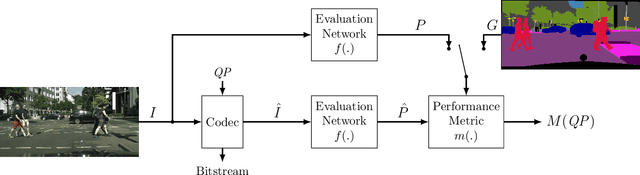



In the emerging field of video coding for machines, video datasets with pristine video quality and high-quality annotations are required for a comprehensive evaluation. However, existing video datasets with detailed annotations are severely limited in size and video quality. Thus, current methods have to either evaluate their codecs on still images or on already compressed data. To mitigate this problem, we propose an evaluation method based on pseudo ground-truth data from the field of semantic segmentation to the evaluation of video coding for machines. Through extensive evaluation, this paper shows that the proposed ground-truth-agnostic evaluation method results in an acceptable absolute measurement error below 0.7 percentage points on the Bjontegaard Delta Rate compared to using the true ground truth for mid-range bitrates. We evaluate on the three tasks of semantic segmentation, instance segmentation, and object detection. Lastly, we utilize the ground-truth-agnostic method to measure the coding performances of the VVC compared against HEVC on the Cityscapes sequences. This reveals that the coding position has a significant influence on the task performance.
* Originally submitted at IEEE ICASSP 2022