 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatially-Adaptive Learning-Based Image Compression with Hierarchical Multi-Scale Latent Spaces
Jul 12, 2023



Adaptive block partitioning is responsible for large gains in current image and video compression systems. This method is able to compress large stationary image areas with only a few symbols, while maintaining a high level of quality in more detailed areas. Current state-of-the-art neural-network-based image compression systems however use only one scale to transmit the latent space. In previous publications, we proposed RDONet, a scheme to transmit the latent space in multiple spatial resolutions. Following this principle, we extend a state-of-the-art compression network by a second hierarchical latent-space level to enable multi-scale processing. We extend the existing rate variability capabilities of RDONet by a gain unit. With that we are able to outperform an equivalent traditional autoencoder by 7% rate savings. Furthermore, we show that even though we add an additional latent space, the complexity only increases marginally and the decoding time can potentially even be decreased.
Learning True Rate-Distortion-Optimization for End-To-End Image Compression
Jan 05, 2022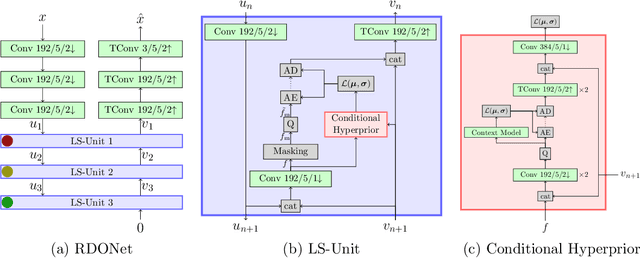
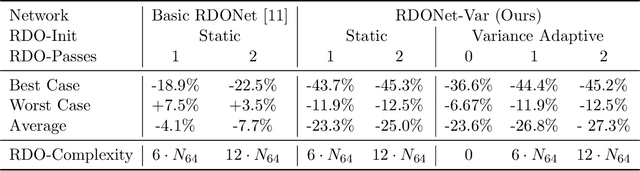


Even though rate-distortion optimization is a crucial part of traditional image and video compression, not many approaches exist which transfer this concept to end-to-end-trained image compression. Most frameworks contain static compression and decompression models which are fixed after training, so efficient rate-distortion optimization is not possible. In a previous work, we proposed RDONet, which enables an RDO approach comparable to adaptive block partitioning in HEVC. In this paper, we enhance the training by introducing low-complexity estimations of the RDO result into the training. Additionally, we propose fast and very fast RDO inference modes. With our novel training method, we achieve average rate savings of 19.6% in MS-SSIM over the previous RDONet model, which equals rate savings of 27.3% over a comparable conventional deep image coder.