 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised contrastive learning from weakly-labeled audio segments for musical version matching
Feb 24, 2025



Detecting musical versions (different renditions of the same piece) is a challenging task with important applications. Because of the ground truth nature, existing approaches match musical versions at the track level (e.g., whole song). However, most applications require to match them at the segment level (e.g., 20s chunks). In addition, existing approaches resort to classification and triplet losses, disregarding more recent losses that could bring meaningful improvements. In this paper, we propose a method to learn from weakly annotated segments, together with a contrastive loss variant that outperforms well-studied alternatives. The former is based on pairwise segment distance reductions, while the latter modifies an existing loss following decoupling, hyper-parameter, and geometric considerations. With these two elements, we do not only achieve state-of-the-art results in the standard track-level evaluation, but we also obtain a breakthrough performance in a segment-level evaluation. We believe that, due to the generality of the challenges addressed here, the proposed methods may find utility in domains beyond audio or musical version matching.
Discogs-VI: A Musical Version Identification Dataset Based on Public Editorial Metadata
Oct 22, 2024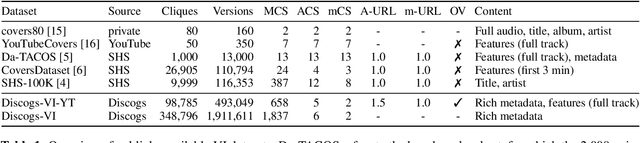
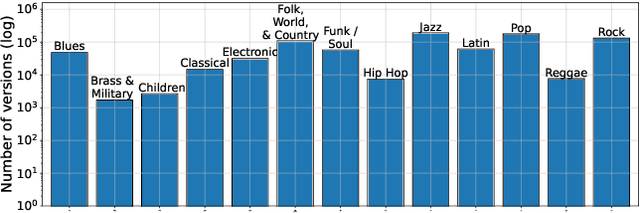
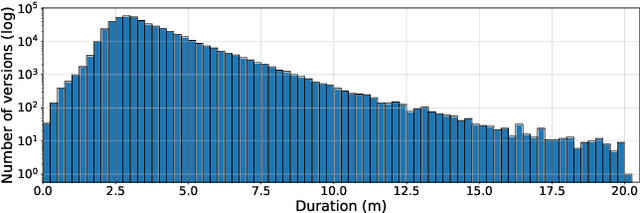
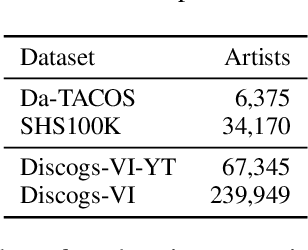
Current version identification (VI) datasets often lack sufficient size and musical diversity to train robust neural networks (NNs). Additionally, their non-representative clique size distributions prevent realistic system evaluations. To address these challenges, we explore the untapped potential of the rich editorial metadata in the Discogs music database and create a large dataset of musical versions containing about 1,900,000 versions across 348,000 cliques. Utilizing a high-precision search algorithm, we map this dataset to official music uploads on YouTube, resulting in a dataset of approximately 493,000 versions across 98,000 cliques. This dataset offers over nine times the number of cliques and over four times the number of versions than existing datasets. We demonstrate the utility of our dataset by training a baseline NN without extensive model complexities or data augmentations, which achieves competitive results on the SHS100K and Da-TACOS datasets. Our dataset, along with the tools used for its creation, the extracted audio features, and a trained model, are all publicly available online.
Universal Speech Enhancement with Score-based Diffusion
Jun 07, 2022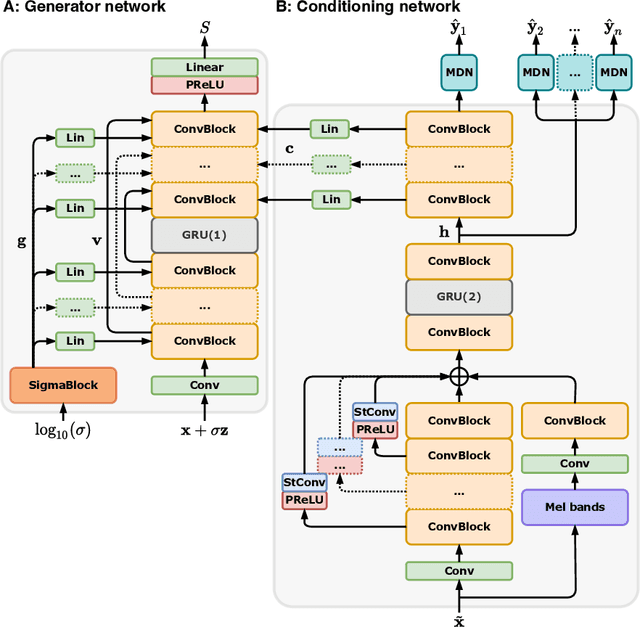
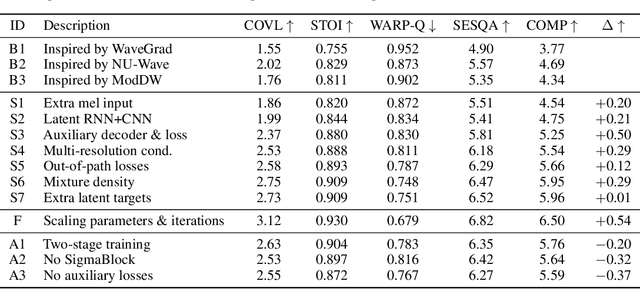
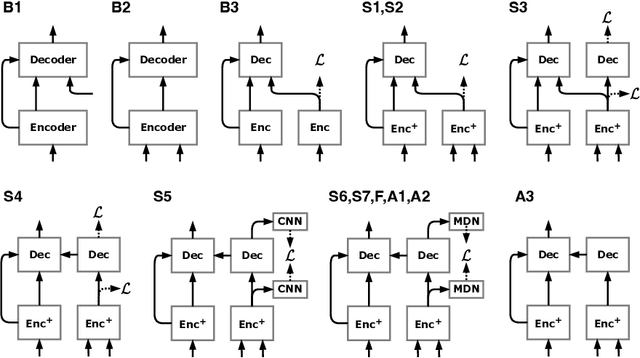
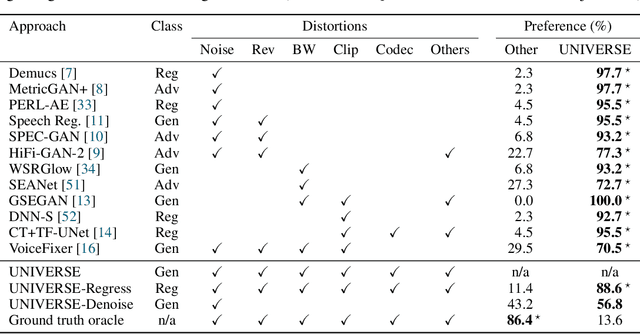
Removing background noise from speech audio has been the subject of considerable research and effort, especially in recent years due to the rise of virtual communication and amateur sound recording. Yet background noise is not the only unpleasant disturbance that can prevent intelligibility: reverb, clipping, codec artifacts, problematic equalization, limited bandwidth, or inconsistent loudness are equally disturbing and ubiquitous. In this work, we propose to consider the task of speech enhancement as a holistic endeavor, and present a universal speech enhancement system that tackles 55 different distortions at the same time. Our approach consists of a generative model that employs score-based diffusion, together with a multi-resolution conditioning network that performs enhancement with mixture density networks. We show that this approach significantly outperforms the state of the art in a subjective test performed by expert listeners. We also show that it achieves competitive objective scores with just 4-8 diffusion steps, despite not considering any particular strategy for fast sampling. We hope that both our methodology and technical contributions encourage researchers and practitioners to adopt a universal approach to speech enhancement, possibly framing it as a generative task.