 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning for Cross-modal Artist Retrieval
Aug 12, 2023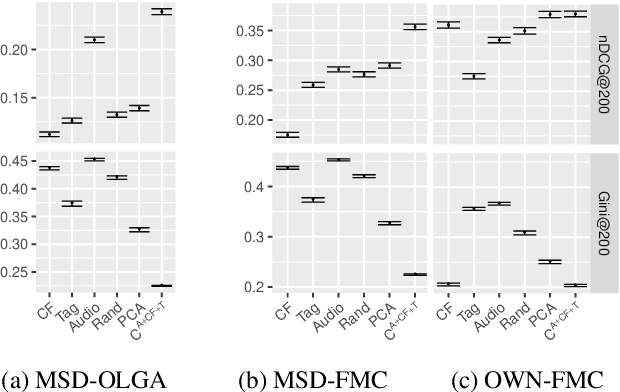



Music retrieval and recommendation applications often rely on content features encoded as embeddings, which provide vector representations of items in a music dataset. Numerous complementary embeddings can be derived from processing items originally represented in several modalities, e.g., audio signals, user interaction data, or editorial data. However, data of any given modality might not be available for all items in any music dataset. In this work, we propose a method based on contrastive learning to combine embeddings from multiple modalities and explore the impact of the presence or absence of embeddings from diverse modalities in an artist similarity task. Experiments on two datasets suggest that our contrastive method outperforms single-modality embeddings and baseline algorithms for combining modalities, both in terms of artist retrieval accuracy and coverage. Improvements with respect to other methods are particularly significant for less popular query artists. We demonstrate our method successfully combines complementary information from diverse modalities, and is more robust to missing modality data (i.e., it better handles the retrieval of artists with different modality embeddings than the query artist's).
A Novel 1D State Space for Efficient Music Rhythmic Analysis
Nov 01, 2021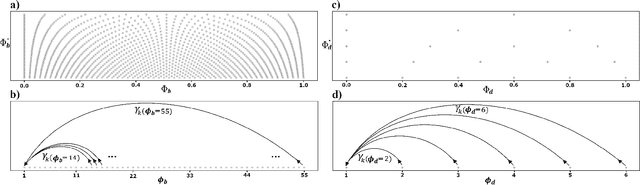
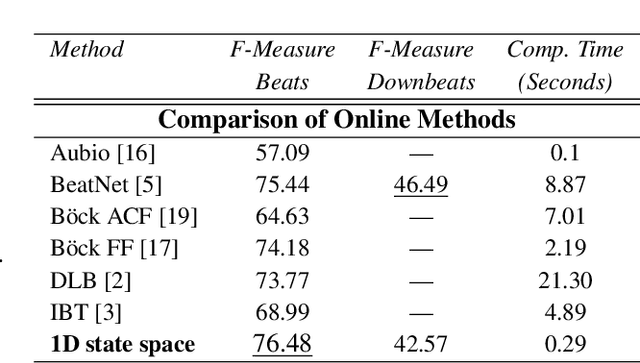
Inferring music time structures has a broad range of applications in music production, processing and analysis. Scholars have proposed various methods to analyze different aspects of time structures, including beat, downbeat, tempo and meter. Many of the state-of-the-art methods, however, are computationally expensive. This makes them inapplicable in real-world industrial settings where the scale of the music collections can be millions. This paper proposes a new state space approach for music time structure analysis. The proposed approach collapses the commonly used 2D state spaces into 1D through a jump-back reward strategy. This reduces the state space size drastically. We then utilize the proposed method for casual, joint beat, downbeat, tempo, and meter tracking, and compare it against several previous beat and downbeat tracking methods. The proposed method delivers comparable performance with the state-of-the-art joint casual models with a much smaller state space and a more than 30 times speedup.
End-to-end learning for music audio tagging at scale
Jun 15, 2018
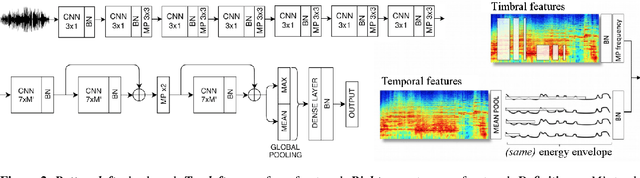

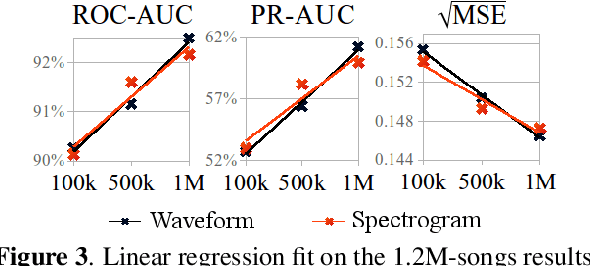
The lack of data tends to limit the outcomes of deep learning research, particularly when dealing with end-to-end learning stacks processing raw data such as waveforms. In this study, 1.2M tracks annotated with musical labels are available to train our end-to-end models. This large amount of data allows us to unrestrictedly explore two different design paradigms for music auto-tagging: assumption-free models - using waveforms as input with very small convolutional filters; and models that rely on domain knowledge - log-mel spectrograms with a convolutional neural network designed to learn timbral and temporal features. Our work focuses on studying how these two types of deep architectures perform when datasets of variable size are available for training: the MagnaTagATune (25k songs), the Million Song Dataset (240k songs), and a private dataset of 1.2M songs. Our experiments suggest that music domain assumptions are relevant when not enough training data are available, thus showing how waveform-based models outperform spectrogram-based ones in large-scale data scenarios.