 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end learning for music audio tagging at scale
Jun 15, 2018
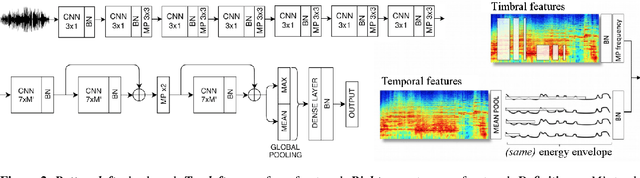

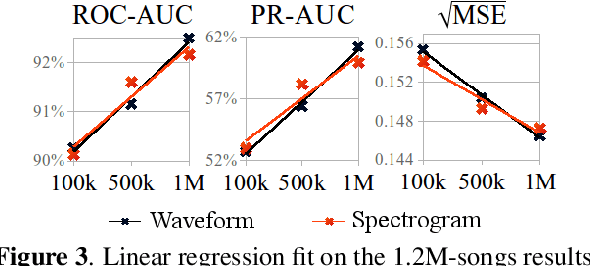
The lack of data tends to limit the outcomes of deep learning research, particularly when dealing with end-to-end learning stacks processing raw data such as waveforms. In this study, 1.2M tracks annotated with musical labels are available to train our end-to-end models. This large amount of data allows us to unrestrictedly explore two different design paradigms for music auto-tagging: assumption-free models - using waveforms as input with very small convolutional filters; and models that rely on domain knowledge - log-mel spectrograms with a convolutional neural network designed to learn timbral and temporal features. Our work focuses on studying how these two types of deep architectures perform when datasets of variable size are available for training: the MagnaTagATune (25k songs), the Million Song Dataset (240k songs), and a private dataset of 1.2M songs. Our experiments suggest that music domain assumptions are relevant when not enough training data are available, thus showing how waveform-based models outperform spectrogram-based ones in large-scale data scenarios.
Predicting Audio Advertisement Quality
Feb 09, 2018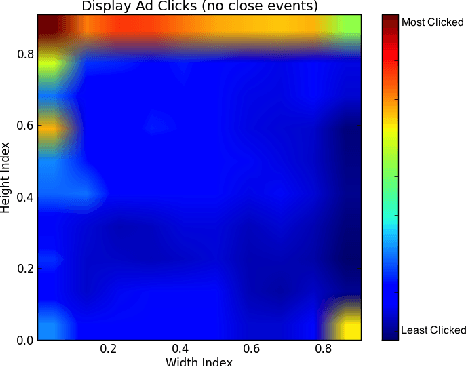
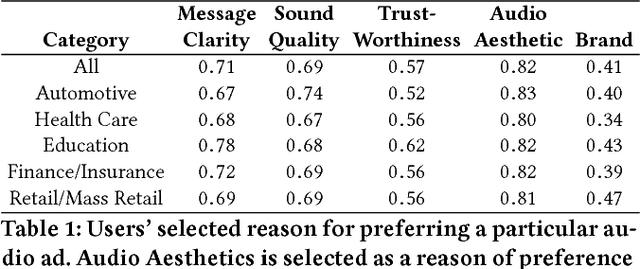

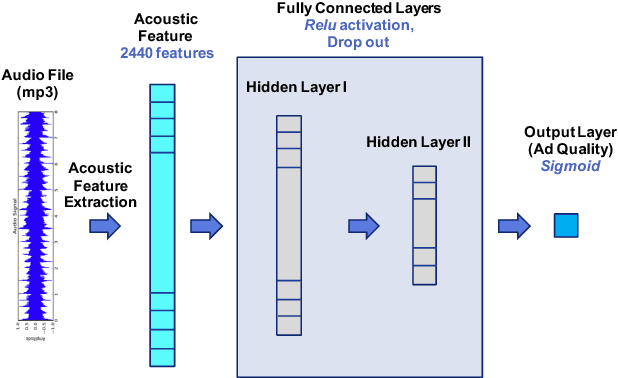
Online audio advertising is a particular form of advertising used abundantly in online music streaming services. In these platforms, which tend to host tens of thousands of unique audio advertisements (ads), providing high quality ads ensures a better user experience and results in longer user engagement. Therefore, the automatic assessment of these ads is an important step toward audio ads ranking and better audio ads creation. In this paper we propose one way to measure the quality of the audio ads using a proxy metric called Long Click Rate (LCR), which is defined by the amount of time a user engages with the follow-up display ad (that is shown while the audio ad is playing) divided by the impressions. We later focus on predicting the audio ad quality using only acoustic features such as harmony, rhythm, and timbre of the audio, extracted from the raw waveform. We discuss how the characteristics of the sound can be connected to concepts such as the clarity of the audio ad message, its trustworthiness, etc. Finally, we propose a new deep learning model for audio ad quality prediction, which outperforms the other discussed models trained on hand-crafted features. To the best of our knowledge, this is the first large-scale audio ad quality prediction study.
* WSDM '18 Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, 9 pages