 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Multistream Data Analytics for Monitoring and Diagnostics in Manufacturing Systems
Dec 26, 2018
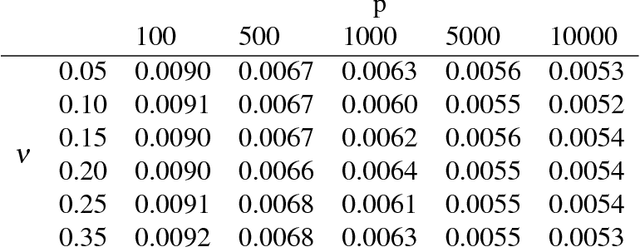
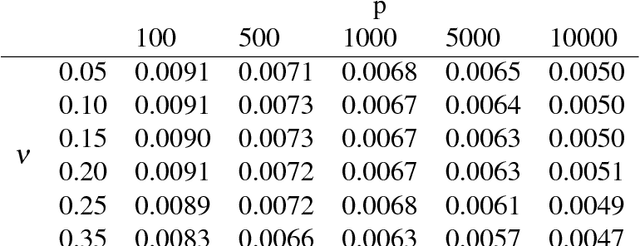
The high-dimensionality and volume of large scale multistream data has inhibited significant research progress in developing an integrated monitoring and diagnostics (M&D) approach. This data, also categorized as big data, is becoming common in manufacturing plants. In this paper, we propose an integrated M\&D approach for large scale streaming data. We developed a novel monitoring method named Adaptive Principal Component monitoring (APC) which adaptively chooses PCs that are most likely to vary due to the change for early detection. Importantly, we integrate a novel diagnostic approach, Principal Component Signal Recovery (PCSR), to enable a streamlined SPC. This diagnostics approach draws inspiration from Compressed Sensing and uses Adaptive Lasso for identifying the sparse change in the process. We theoretically motivate our approaches and do a performance evaluation of our integrated M&D method through simulations and case studies.
Predicting Audio Advertisement Quality
Feb 09, 2018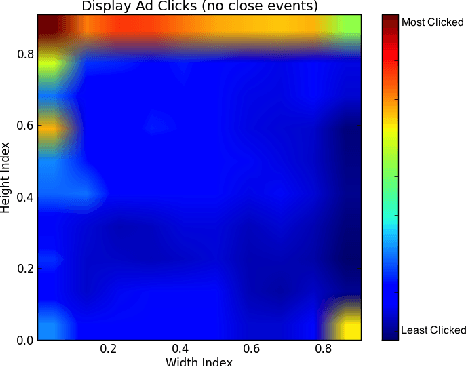
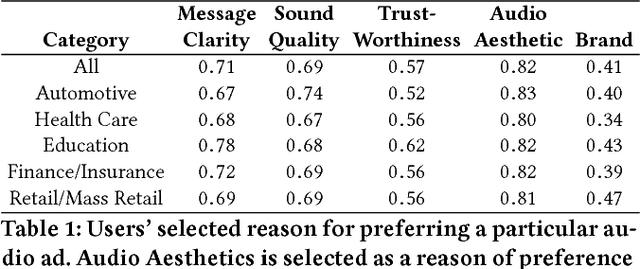

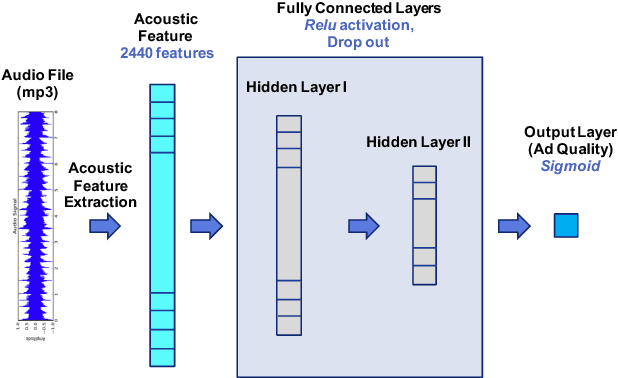
Online audio advertising is a particular form of advertising used abundantly in online music streaming services. In these platforms, which tend to host tens of thousands of unique audio advertisements (ads), providing high quality ads ensures a better user experience and results in longer user engagement. Therefore, the automatic assessment of these ads is an important step toward audio ads ranking and better audio ads creation. In this paper we propose one way to measure the quality of the audio ads using a proxy metric called Long Click Rate (LCR), which is defined by the amount of time a user engages with the follow-up display ad (that is shown while the audio ad is playing) divided by the impressions. We later focus on predicting the audio ad quality using only acoustic features such as harmony, rhythm, and timbre of the audio, extracted from the raw waveform. We discuss how the characteristics of the sound can be connected to concepts such as the clarity of the audio ad message, its trustworthiness, etc. Finally, we propose a new deep learning model for audio ad quality prediction, which outperforms the other discussed models trained on hand-crafted features. To the best of our knowledge, this is the first large-scale audio ad quality prediction study.
* WSDM '18 Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, 9 pages
Sequence Graph Transform (SGT): A Feature Extraction Function for Sequence Data Mining (Extended Version)
Apr 30, 2017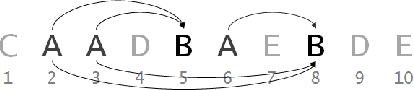
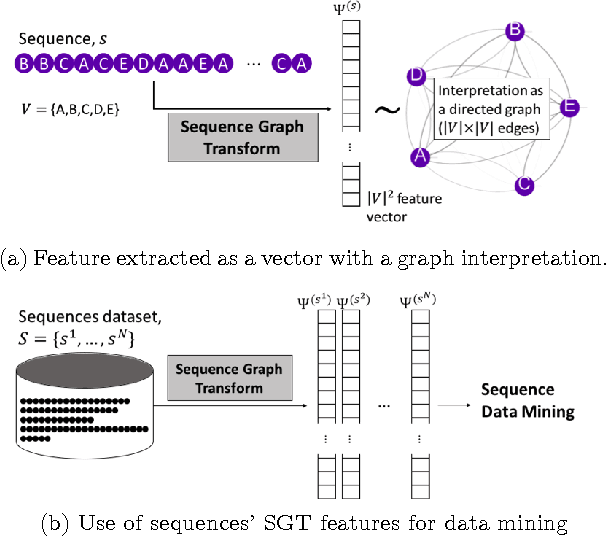
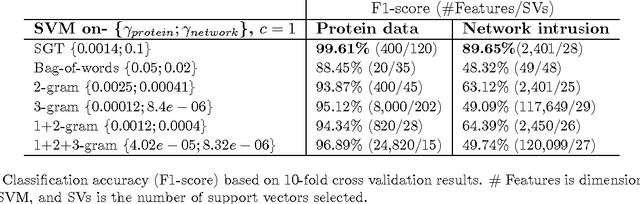
The ubiquitous presence of sequence data across fields such as the web, healthcare, bioinformatics, and text mining has made sequence mining a vital research area. However, sequence mining is particularly challenging because of difficulty in finding (dis)similarity/distance between sequences. This is because a distance measure between sequences is not obvious due to their unstructuredness---arbitrary strings of arbitrary length. Feature representations, such as n-grams, are often used but they either compromise on extracting both short- and long-term sequence patterns or have a high computation. We propose a new function, Sequence Graph Transform (SGT), that extracts the short- and long-term sequence features and embeds them in a finite-dimensional feature space. Importantly, SGT has low computation and can extract any amount of short- to long-term patterns without any increase in the computation, also proved theoretically in this paper. Due to this, SGT yields superior result with significantly higher accuracy and lower computation compared to the existing methods. We show it via several experimentation and SGT's real world application for clustering, classification, search and visualization as examples.
Inertial Regularization and Selection (IRS): Sequential Regression in High-Dimension and Sparsity
Jan 10, 2017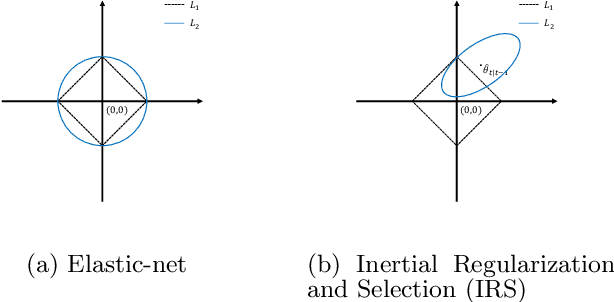
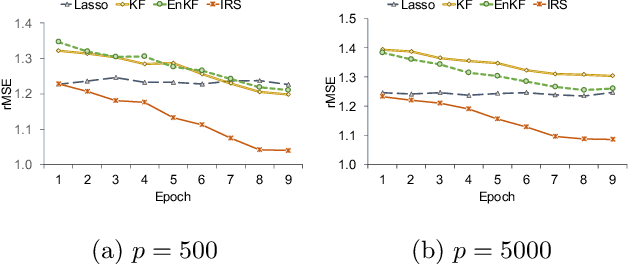
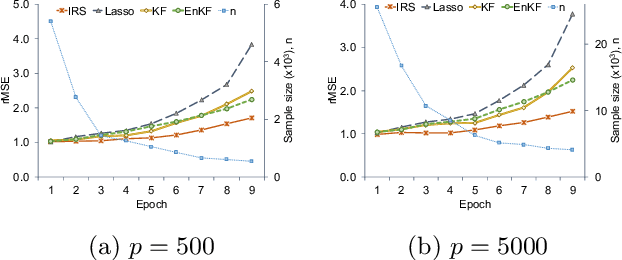
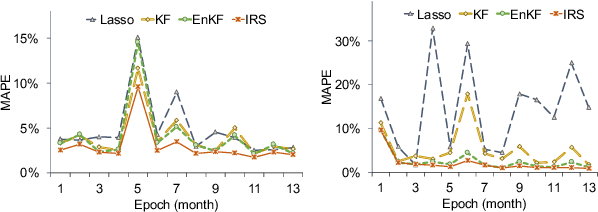
In this paper, we develop a new sequential regression modeling approach for data streams. Data streams are commonly found around us, e.g in a retail enterprise sales data is continuously collected every day. A demand forecasting model is an important outcome from the data that needs to be continuously updated with the new incoming data. The main challenge in such modeling arises when there is a) high dimensional and sparsity, b) need for an adaptive use of prior knowledge, and/or c) structural changes in the system. The proposed approach addresses these challenges by incorporating an adaptive L1-penalty and inertia terms in the loss function, and thus called Inertial Regularization and Selection (IRS). The former term performs model selection to handle the first challenge while the latter is shown to address the last two challenges. A recursive estimation algorithm is developed, and shown to outperform the commonly used state-space models, such as Kalman Filters, in experimental studies and real data.