 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfluence Maximization with Fairness at Scale (Extended Version)
Jun 06, 2023



In this paper, we revisit the problem of influence maximization with fairness, which aims to select k influential nodes to maximise the spread of information in a network, while ensuring that selected sensitive user attributes are fairly affected, i.e., are proportionally similar between the original network and the affected users. Recent studies on this problem focused only on extremely small networks, hence the challenge remains on how to achieve a scalable solution, applicable to networks with millions or billions of nodes. We propose an approach that is based on learning node representations for fair spread from diffusion cascades, instead of the social connectivity s.t. we can deal with very large graphs. We propose two data-driven approaches: (a) fairness-based participant sampling (FPS), and (b) fairness as context (FAC). Spread related user features, such as the probability of diffusing information to others, are derived from the historical information cascades, using a deep neural network. The extracted features are then used in selecting influencers that maximize the influence spread, while being also fair with respect to the chosen sensitive attributes. In FPS, fairness and cascade length information are considered independently in the decision-making process, while FAC considers these information facets jointly and considers correlations between them. The proposed algorithms are generic and represent the first policy-driven solutions that can be applied to arbitrary sets of sensitive attributes at scale. We evaluate the performance of our solutions on a real-world public dataset (Sina Weibo) and on a hybrid real-synthethic dataset (Digg), which exhibit all the facets that we exploit, namely diffusion network, diffusion traces, and user profiles. These experiments show that our methods outperform the state-the-art solutions in terms of spread, fairness, and scalability.
SunCast: Solar Irradiance Nowcasting from Geosynchronous Satellite Data
Jan 17, 2022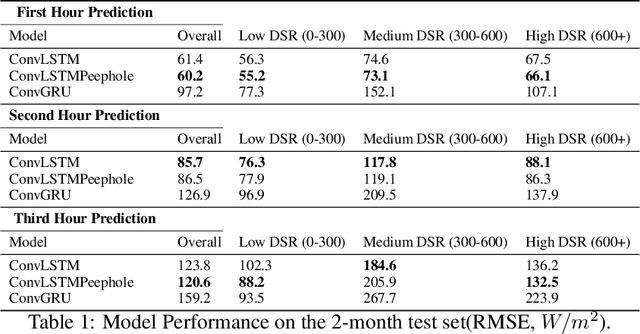
When cloud layers cover photovoltaic (PV) panels, the amount of power the panels produce fluctuates rapidly. Therefore, to maintain enough energy on a power grid to match demand, utilities companies rely on reserve power sources that typically come from fossil fuels and therefore pollute the environment. Accurate short-term PV power prediction enables operators to maximize the amount of power obtained from PV panels and safely reduce the reserve energy needed from fossil fuel sources. While several studies have developed machine learning models to predict solar irradiance at specific PV generation facilities, little work has been done to model short-term solar irradiance on a global scale. Furthermore, models that have been developed are proprietary and have architectures that are not publicly available or rely on computationally demanding Numerical Weather Prediction (NWP) models. Here, we propose a Convolutional Long Short-Term Memory Network model that treats solar nowcasting as a next frame prediction problem, is more efficient than NWP models and has a straightforward, reproducible architecture. Our models can predict solar irradiance for entire North America for up to 3 hours in under 60 seconds on a single machine without a GPU and has a RMSE of 120 W/m2 when evaluated on 2 months of data.
HyperionSolarNet: Solar Panel Detection from Aerial Images
Jan 06, 2022

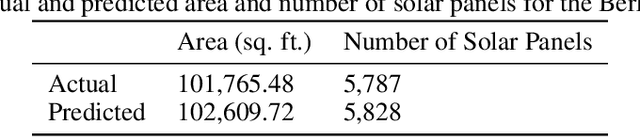
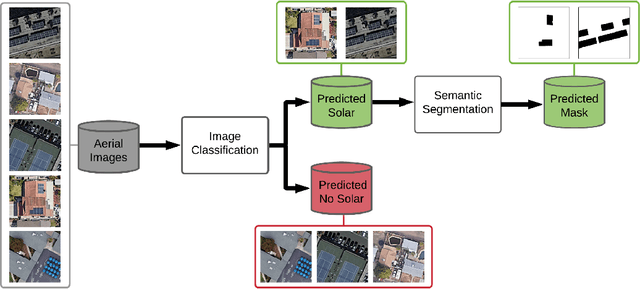
With the effects of global climate change impacting the world, collective efforts are needed to reduce greenhouse gas emissions. The energy sector is the single largest contributor to climate change and many efforts are focused on reducing dependence on carbon-emitting power plants and moving to renewable energy sources, such as solar power. A comprehensive database of the location of solar panels is important to assist analysts and policymakers in defining strategies for further expansion of solar energy. In this paper we focus on creating a world map of solar panels. We identify locations and total surface area of solar panels within a given geographic area. We use deep learning methods for automated detection of solar panel locations and their surface area using aerial imagery. The framework, which consists of a two-branch model using an image classifier in tandem with a semantic segmentation model, is trained on our created dataset of satellite images. Our work provides an efficient and scalable method for detecting solar panels, achieving an accuracy of 0.96 for classification and an IoU score of 0.82 for segmentation performance.
Self-supervised Contrastive Learning for Irrigation Detection in Satellite Imagery
Aug 12, 2021
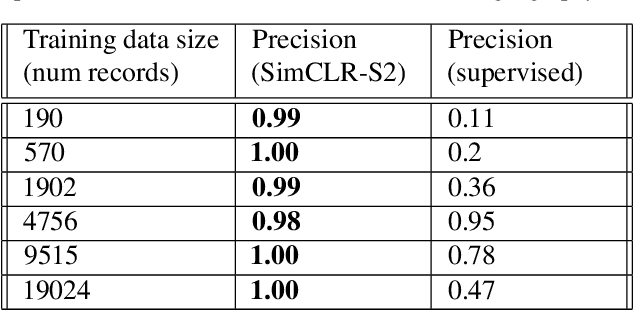
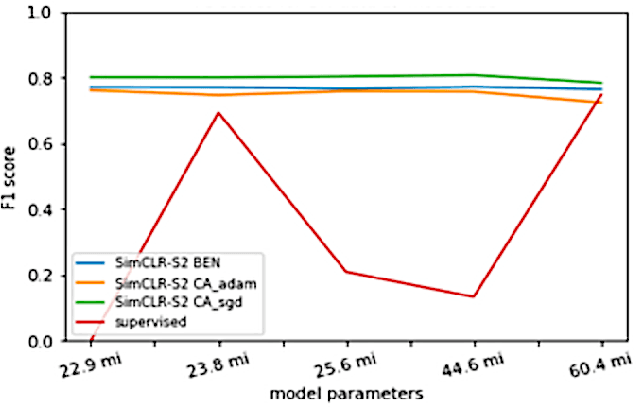
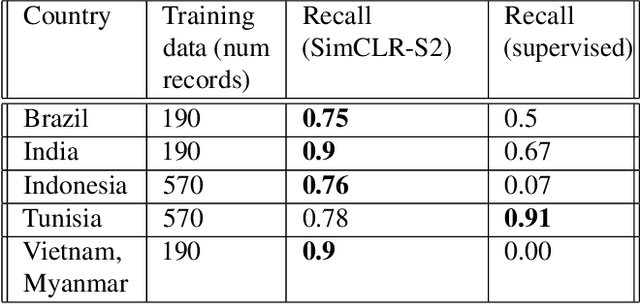
Climate change has caused reductions in river runoffs and aquifer recharge resulting in an increasingly unsustainable crop water demand from reduced freshwater availability. Achieving food security while deploying water in a sustainable manner will continue to be a major challenge necessitating careful monitoring and tracking of agricultural water usage. Historically, monitoring water usage has been a slow and expensive manual process with many imperfections and abuses. Ma-chine learning and remote sensing developments have increased the ability to automatically monitor irrigation patterns, but existing techniques often require curated and labelled irrigation data, which are expensive and time consuming to obtain and may not exist for impactful areas such as developing countries. In this paper, we explore an end-to-end real world application of irrigation detection with uncurated and unlabeled satellite imagery. We apply state-of-the-art self-supervised deep learning techniques to optical remote sensing data, and find that we are able to detect irrigation with up to nine times better precision, 90% better recall and 40% more generalization ability than the traditional supervised learning methods.
Revenue Maximization of Airbnb Marketplace using Search Results
Nov 16, 2019
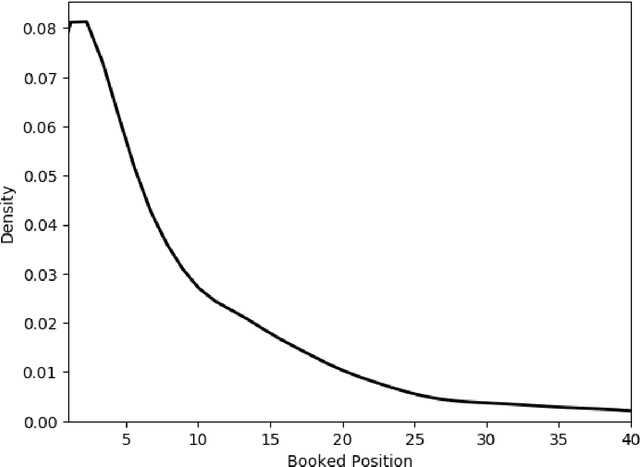

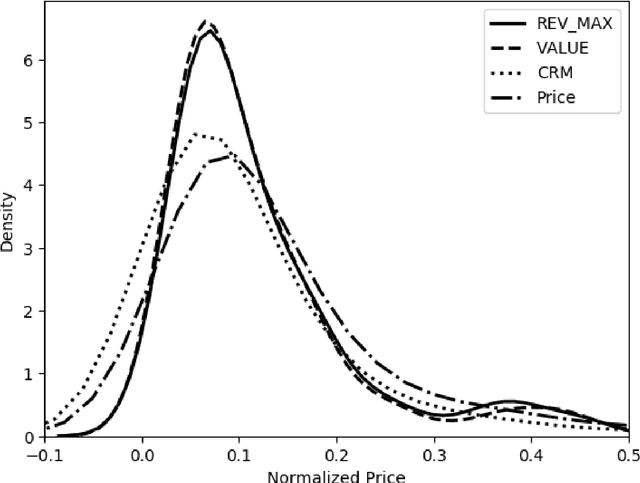
Correctly pricing products or services in an online marketplace presents a challenging problem and one of the critical factors for the success of the business. When users are looking to buy an item they typically search for it. Query relevance models are used at this stage to retrieve and rank the items on the search page from most relevant to least relevant. The presented items are naturally "competing" against each other for user purchases. We provide a practical two-stage model to price this set of retrieved items for which distributions of their values are learned. The initial output of the pricing strategy is a price vector for the top displayed items in one search event. We later aggregate these results over searches to provide the supplier with the optimal price for each item. We applied our solution to large-scale search data obtained from Airbnb Experiences marketplace. Offline evaluation results show that our strategy improves upon baseline pricing strategies on key metrics by at least +20% in terms of booking regret and +55% in terms of revenue potential.
Hierarchical Modeling and Shrinkage for User Session Length Prediction in Media Streaming
Jun 22, 2018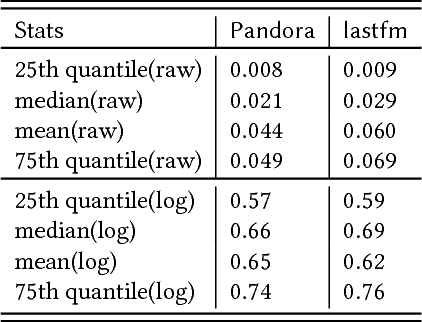
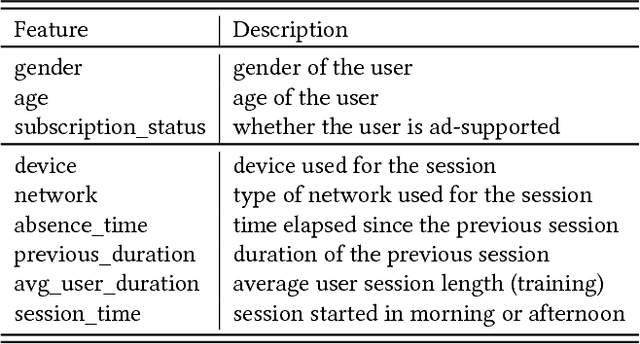
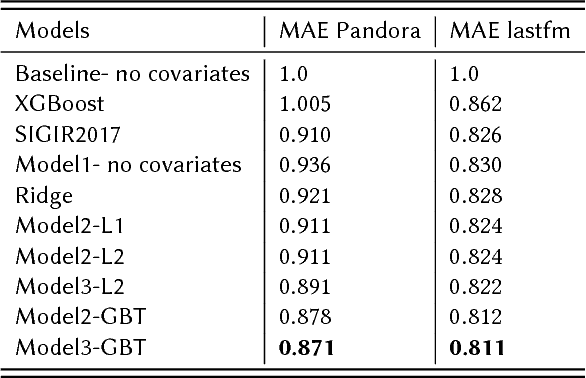
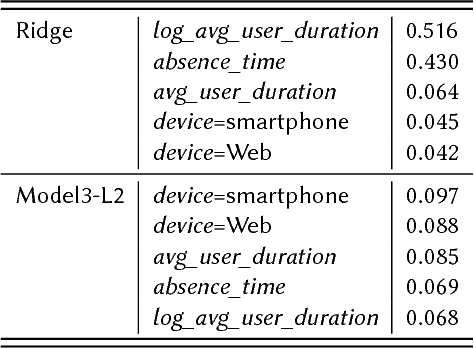
An important metric of users' satisfaction and engagement within on-line streaming services is the user session length, i.e. the amount of time they spend on a service continuously without interruption. Being able to predict this value directly benefits the recommendation and ad pacing contexts in music and video streaming services. Recent research has shown that predicting the exact amount of time spent is highly nontrivial due to many external factors for which a user can end a session, and the lack of predictive covariates. Most of the other related literature on duration based user engagement has focused on dwell time for websites, for search and display ads, mainly for post-click satisfaction prediction or ad ranking. In this work we present a novel framework inspired by hierarchical Bayesian modeling to predict, at the moment of login, the amount of time a user will spend in the streaming service. The time spent by a user on a platform depends upon user-specific latent variables which are learned via hierarchical shrinkage. Our framework enjoys theoretical guarantees and naturally incorporates flexible parametric/nonparametric models on the covariates, including models robust to outliers. Our proposal is found to outperform state-of- the-art estimators in terms of efficiency and predictive performance on real world public and private datasets.
Predicting Audio Advertisement Quality
Feb 09, 2018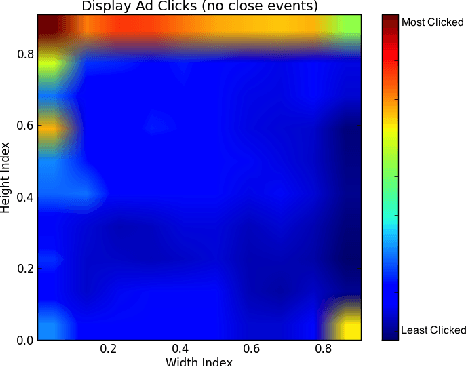
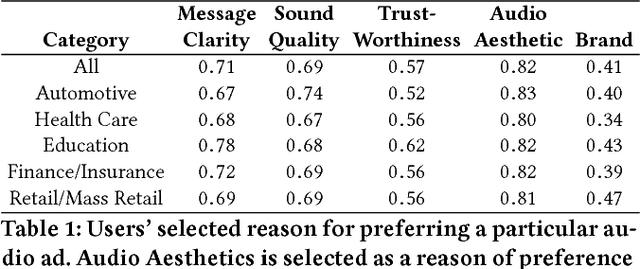

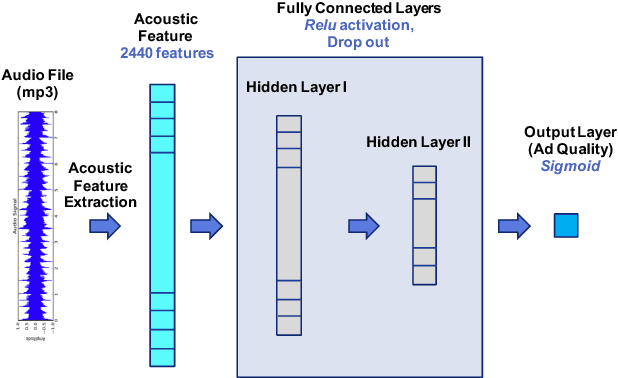
Online audio advertising is a particular form of advertising used abundantly in online music streaming services. In these platforms, which tend to host tens of thousands of unique audio advertisements (ads), providing high quality ads ensures a better user experience and results in longer user engagement. Therefore, the automatic assessment of these ads is an important step toward audio ads ranking and better audio ads creation. In this paper we propose one way to measure the quality of the audio ads using a proxy metric called Long Click Rate (LCR), which is defined by the amount of time a user engages with the follow-up display ad (that is shown while the audio ad is playing) divided by the impressions. We later focus on predicting the audio ad quality using only acoustic features such as harmony, rhythm, and timbre of the audio, extracted from the raw waveform. We discuss how the characteristics of the sound can be connected to concepts such as the clarity of the audio ad message, its trustworthiness, etc. Finally, we propose a new deep learning model for audio ad quality prediction, which outperforms the other discussed models trained on hand-crafted features. To the best of our knowledge, this is the first large-scale audio ad quality prediction study.
* WSDM '18 Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, 9 pages
Predicting Session Length in Media Streaming
Aug 01, 2017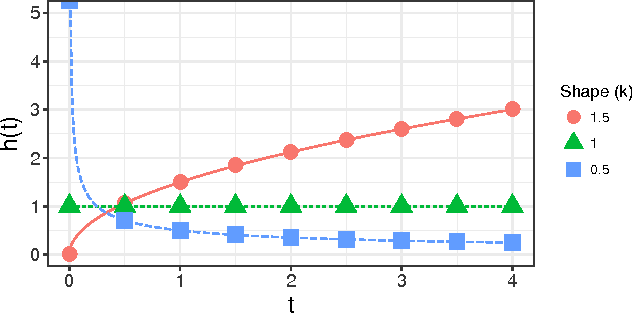

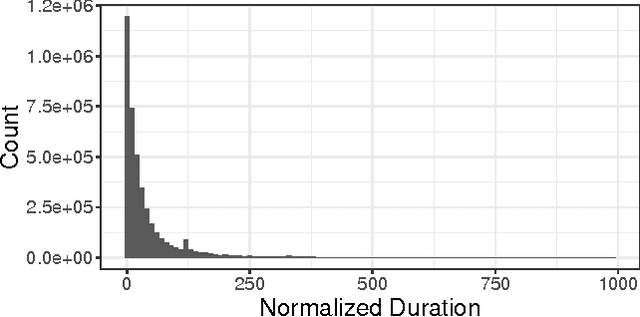
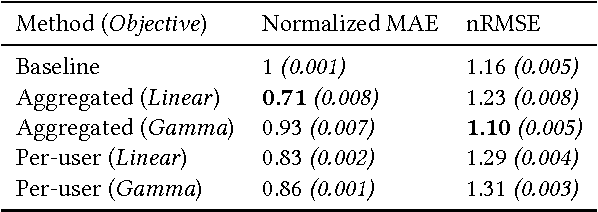
Session length is a very important aspect in determining a user's satisfaction with a media streaming service. Being able to predict how long a session will last can be of great use for various downstream tasks, such as recommendations and ad scheduling. Most of the related literature on user interaction duration has focused on dwell time for websites, usually in the context of approximating post-click satisfaction either in search results, or display ads. In this work we present the first analysis of session length in a mobile-focused online service, using a real world data-set from a major music streaming service. We use survival analysis techniques to show that the characteristics of the length distributions can differ significantly between users, and use gradient boosted trees with appropriate objectives to predict the length of a session using only information available at its beginning. Our evaluation on real world data illustrates that our proposed technique outperforms the considered baseline.
* 4 pages, 3 figures
Sequential ranking under random semi-bandit feedback
May 26, 2016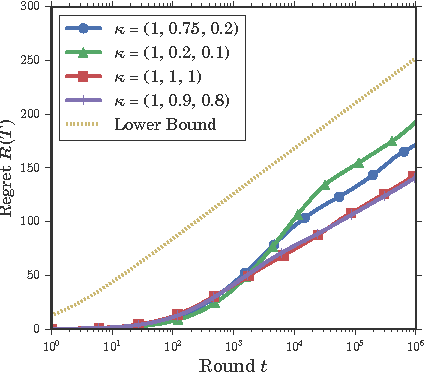
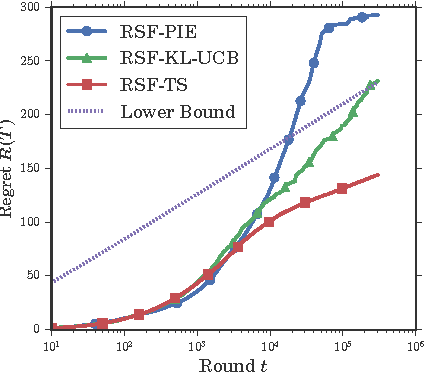
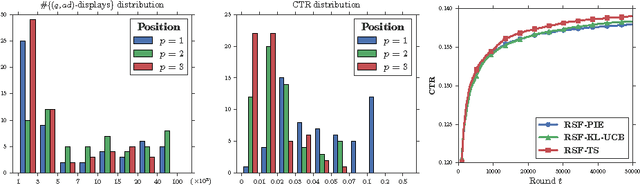
In many web applications, a recommendation is not a single item suggested to a user but a list of possibly interesting contents that may be ranked in some contexts. The combinatorial bandit problem has been studied quite extensively these last two years and many theoretical results now exist : lower bounds on the regret or asymptotically optimal algorithms. However, because of the variety of situations that can be considered, results are designed to solve the problem for a specific reward structure such as the Cascade Model. The present work focuses on the problem of ranking items when the user is allowed to click on several items while scanning the list from top to bottom.
A Hierarchical Recurrent Encoder-Decoder For Generative Context-Aware Query Suggestion
Jul 08, 2015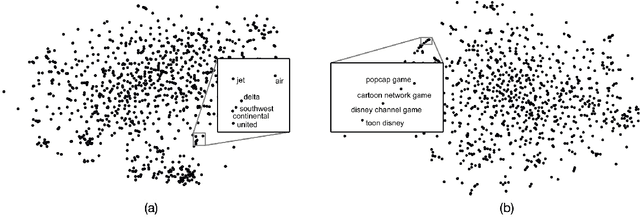
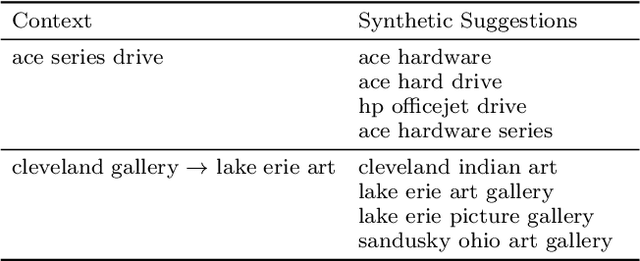
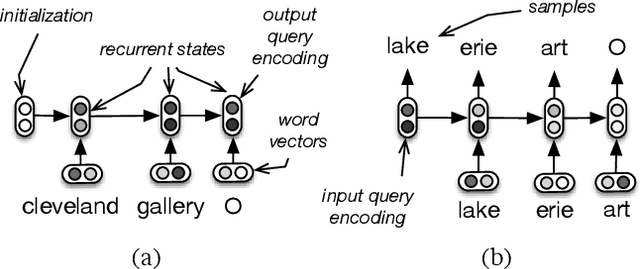
Users may strive to formulate an adequate textual query for their information need. Search engines assist the users by presenting query suggestions. To preserve the original search intent, suggestions should be context-aware and account for the previous queries issued by the user. Achieving context awareness is challenging due to data sparsity. We present a probabilistic suggestion model that is able to account for sequences of previous queries of arbitrary lengths. Our novel hierarchical recurrent encoder-decoder architecture allows the model to be sensitive to the order of queries in the context while avoiding data sparsity. Additionally, our model can suggest for rare, or long-tail, queries. The produced suggestions are synthetic and are sampled one word at a time, using computationally cheap decoding techniques. This is in contrast to current synthetic suggestion models relying upon machine learning pipelines and hand-engineered feature sets. Results show that it outperforms existing context-aware approaches in a next query prediction setting. In addition to query suggestion, our model is general enough to be used in a variety of other applications.