 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple-Play Bandits in the Position-Based Model
Jun 08, 2016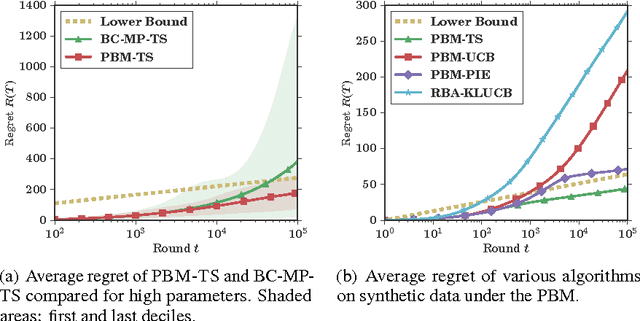
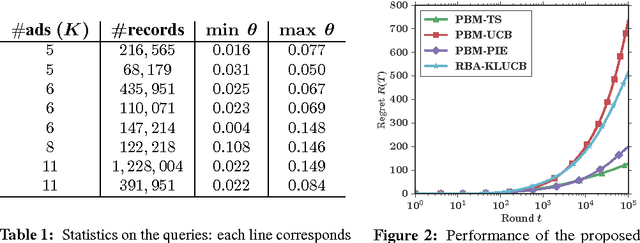
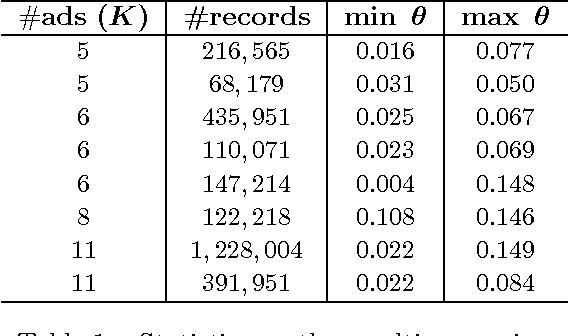
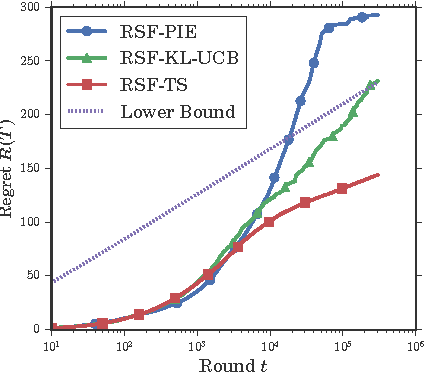
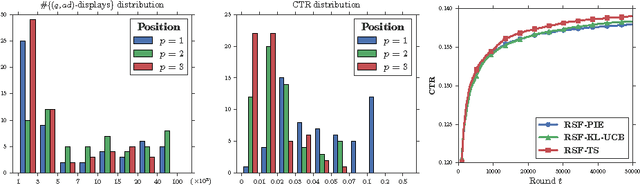
Sequentially learning to place items in multi-position displays or lists is a task that can be cast into the multiple-play semi-bandit setting. However, a major concern in this context is when the system cannot decide whether the user feedback for each item is actually exploitable. Indeed, much of the content may have been simply ignored by the user. The present work proposes to exploit available information regarding the display position bias under the so-called Position-based click model (PBM). We first discuss how this model differs from the Cascade model and its variants considered in several recent works on multiple-play bandits. We then provide a novel regret lower bound for this model as well as computationally efficient algorithms that display good empirical and theoretical performance.
Sequential ranking under random semi-bandit feedback
May 26, 2016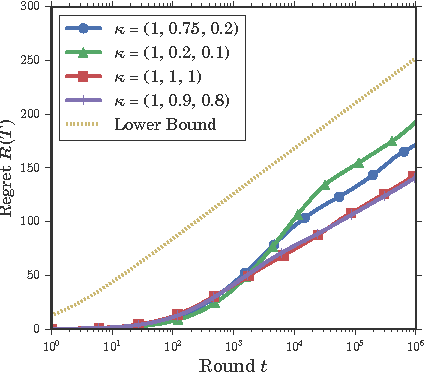
In many web applications, a recommendation is not a single item suggested to a user but a list of possibly interesting contents that may be ranked in some contexts. The combinatorial bandit problem has been studied quite extensively these last two years and many theoretical results now exist : lower bounds on the regret or asymptotically optimal algorithms. However, because of the variety of situations that can be considered, results are designed to solve the problem for a specific reward structure such as the Cascade Model. The present work focuses on the problem of ranking items when the user is allowed to click on several items while scanning the list from top to bottom.