 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommVQ: Commutative Vector Quantization for KV Cache Compression
Jun 23, 2025Large Language Models (LLMs) are increasingly used in applications requiring long context lengths, but the key-value (KV) cache often becomes a memory bottleneck on GPUs as context grows. To address this, we propose Commutative Vector Quantization (CommVQ) to significantly reduce memory usage for long-context LLM inference. We first introduce additive quantization with a lightweight encoder and codebook to compress the KV cache, which can be decoded via simple matrix multiplication. To further reduce computational costs during decoding, we design the codebook to be commutative with Rotary Position Embedding (RoPE) and train it using an Expectation-Maximization (EM) algorithm. This enables efficient integration of decoding into the self-attention mechanism. Our approach achieves high accuracy with additive quantization and low overhead via the RoPE-commutative codebook. Experiments on long-context benchmarks and GSM8K show that our method reduces FP16 KV cache size by 87.5% with 2-bit quantization, while outperforming state-of-the-art KV cache quantization methods. Notably, it enables 1-bit KV cache quantization with minimal accuracy loss, allowing a LLaMA-3.1 8B model to run with a 128K context length on a single RTX 4090 GPU. The source code is available at: https://github.com/UMass-Embodied-AGI/CommVQ.
The Super Weight in Large Language Models
Nov 11, 2024
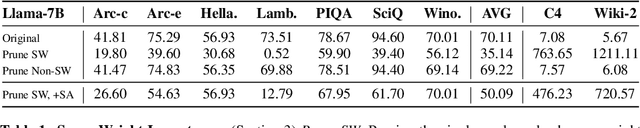
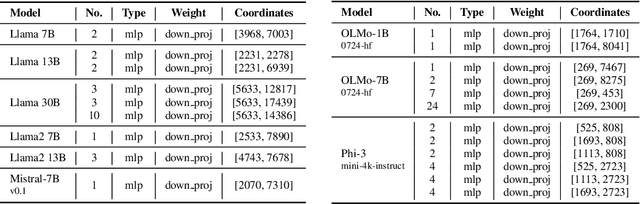

Recent works have shown a surprising result: a small fraction of Large Language Model (LLM) parameter outliers are disproportionately important to the quality of the model. LLMs contain billions of parameters, so these small fractions, such as 0.01%, translate to hundreds of thousands of parameters. In this work, we present an even more surprising finding: Pruning as few as a single parameter can destroy an LLM's ability to generate text -- increasing perplexity by 3 orders of magnitude and reducing zero-shot accuracy to guessing. We propose a data-free method for identifying such parameters, termed super weights, using a single forward pass through the model. We additionally find that these super weights induce correspondingly rare and large activation outliers, termed super activations. When preserved with high precision, super activations can improve simple round-to-nearest quantization to become competitive with state-of-the-art methods. For weight quantization, we similarly find that by preserving the super weight and clipping other weight outliers, round-to-nearest quantization can scale to much larger block sizes than previously considered. To facilitate further research into super weights, we provide an index of super weight coordinates for common, openly available LLMs.
Apple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
Prior Knowledge-Guided Attention in Self-Supervised Vision Transformers
Sep 07, 2022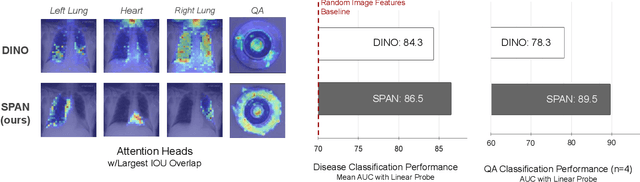
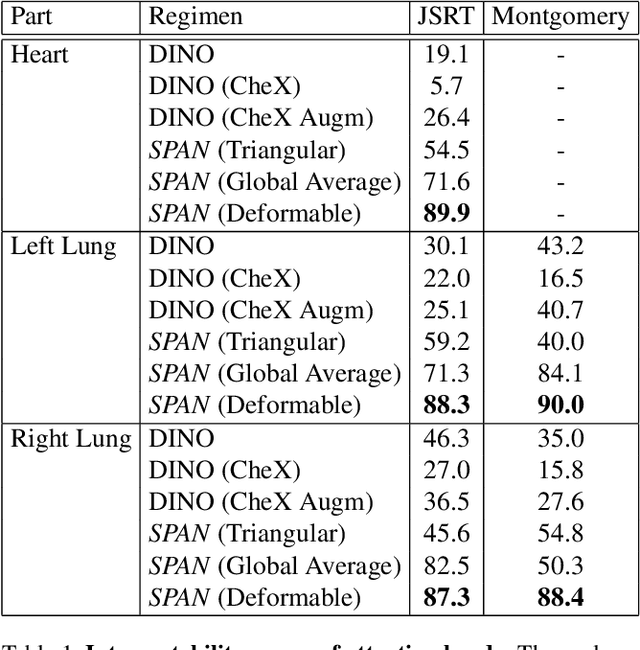
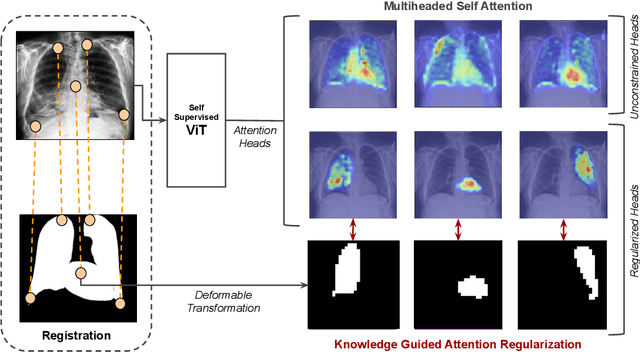

Recent trends in self-supervised representation learning have focused on removing inductive biases from training pipelines. However, inductive biases can be useful in settings when limited data are available or provide additional insight into the underlying data distribution. We present spatial prior attention (SPAN), a framework that takes advantage of consistent spatial and semantic structure in unlabeled image datasets to guide Vision Transformer attention. SPAN operates by regularizing attention masks from separate transformer heads to follow various priors over semantic regions. These priors can be derived from data statistics or a single labeled sample provided by a domain expert. We study SPAN through several detailed real-world scenarios, including medical image analysis and visual quality assurance. We find that the resulting attention masks are more interpretable than those derived from domain-agnostic pretraining. SPAN produces a 58.7 mAP improvement for lung and heart segmentation. We also find that our method yields a 2.2 mAUC improvement compared to domain-agnostic pretraining when transferring the pretrained model to a downstream chest disease classification task. Lastly, we show that SPAN pretraining leads to higher downstream classification performance in low-data regimes compared to domain-agnostic pretraining.
HyperionSolarNet: Solar Panel Detection from Aerial Images
Jan 06, 2022

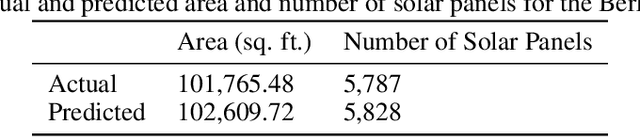
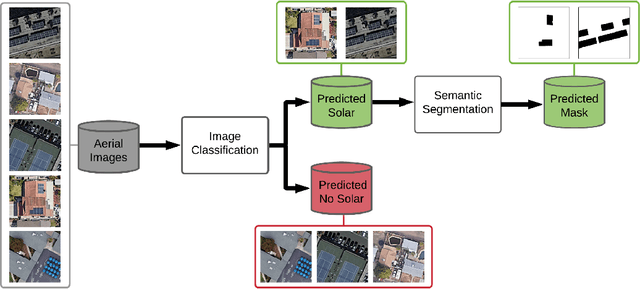
With the effects of global climate change impacting the world, collective efforts are needed to reduce greenhouse gas emissions. The energy sector is the single largest contributor to climate change and many efforts are focused on reducing dependence on carbon-emitting power plants and moving to renewable energy sources, such as solar power. A comprehensive database of the location of solar panels is important to assist analysts and policymakers in defining strategies for further expansion of solar energy. In this paper we focus on creating a world map of solar panels. We identify locations and total surface area of solar panels within a given geographic area. We use deep learning methods for automated detection of solar panel locations and their surface area using aerial imagery. The framework, which consists of a two-branch model using an image classifier in tandem with a semantic segmentation model, is trained on our created dataset of satellite images. Our work provides an efficient and scalable method for detecting solar panels, achieving an accuracy of 0.96 for classification and an IoU score of 0.82 for segmentation performance.
Multi-source Few-shot Domain Adaptation
Sep 25, 2021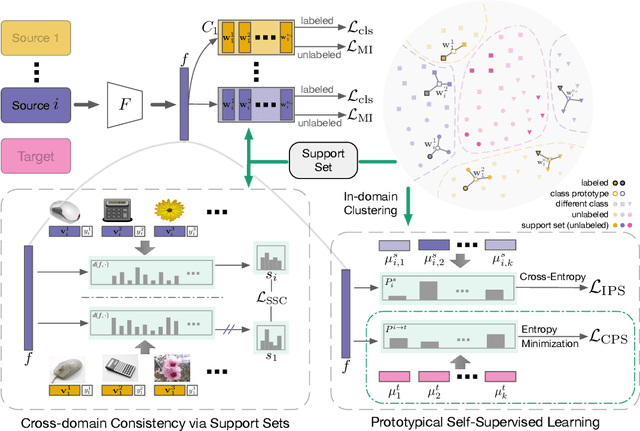
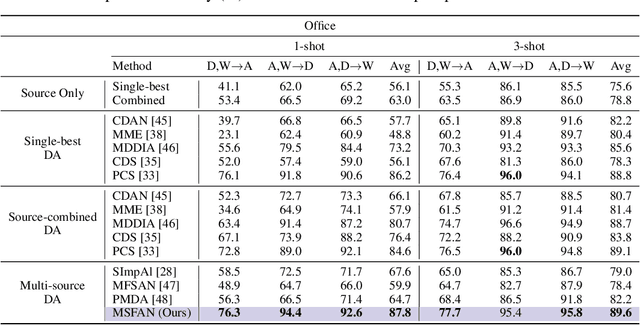
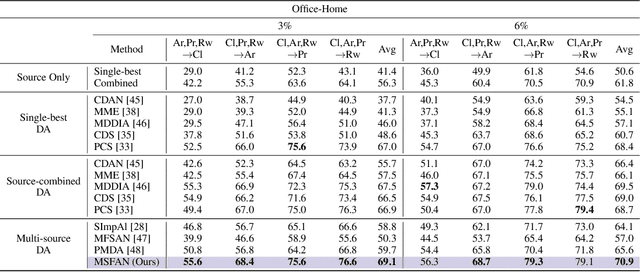

Multi-source Domain Adaptation (MDA) aims to transfer predictive models from multiple, fully-labeled source domains to an unlabeled target domain. However, in many applications, relevant labeled source datasets may not be available, and collecting source labels can be as expensive as labeling the target data itself. In this paper, we investigate Multi-source Few-shot Domain Adaptation (MFDA): a new domain adaptation scenario with limited multi-source labels and unlabeled target data. As we show, existing methods often fail to learn discriminative features for both source and target domains in the MFDA setting. Therefore, we propose a novel framework, termed Multi-Source Few-shot Adaptation Network (MSFAN), which can be trained end-to-end in a non-adversarial manner. MSFAN operates by first using a type of prototypical, multi-domain, self-supervised learning to learn features that are not only domain-invariant but also class-discriminative. Second, MSFAN uses a small, labeled support set to enforce feature consistency and domain invariance across domains. Finally, prototypes from multiple sources are leveraged to learn better classifiers. Compared with state-of-the-art MDA methods, MSFAN improves the mean classification accuracy over different domain pairs on MFDA by 20.2%, 9.4%, and 16.2% on Office, Office-Home, and DomainNet, respectively.
Self-supervised Contrastive Learning for Irrigation Detection in Satellite Imagery
Aug 12, 2021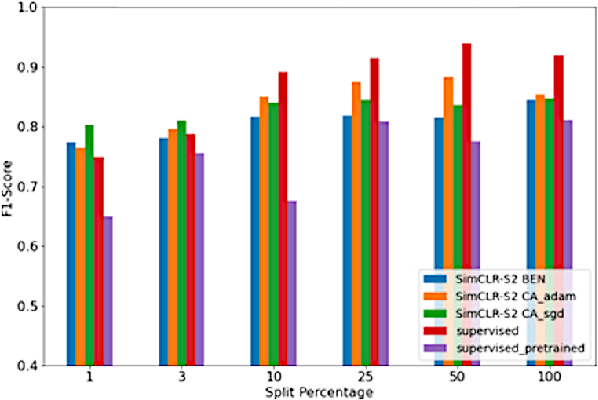
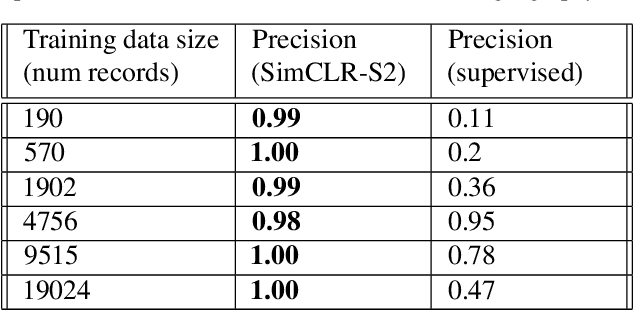
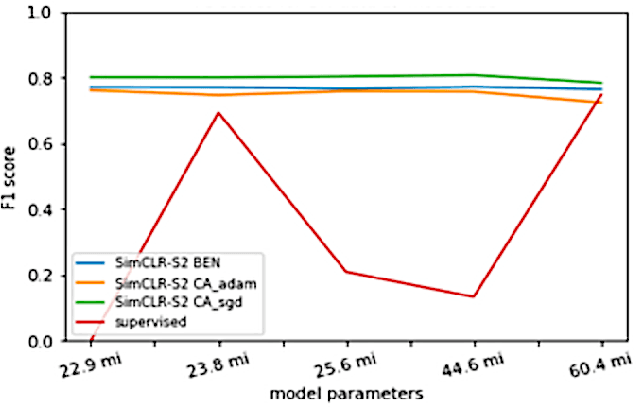
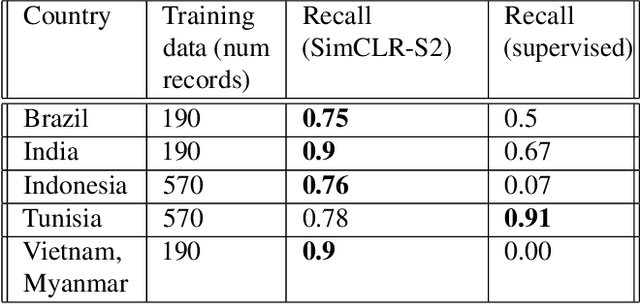
Climate change has caused reductions in river runoffs and aquifer recharge resulting in an increasingly unsustainable crop water demand from reduced freshwater availability. Achieving food security while deploying water in a sustainable manner will continue to be a major challenge necessitating careful monitoring and tracking of agricultural water usage. Historically, monitoring water usage has been a slow and expensive manual process with many imperfections and abuses. Ma-chine learning and remote sensing developments have increased the ability to automatically monitor irrigation patterns, but existing techniques often require curated and labelled irrigation data, which are expensive and time consuming to obtain and may not exist for impactful areas such as developing countries. In this paper, we explore an end-to-end real world application of irrigation detection with uncurated and unlabeled satellite imagery. We apply state-of-the-art self-supervised deep learning techniques to optical remote sensing data, and find that we are able to detect irrigation with up to nine times better precision, 90% better recall and 40% more generalization ability than the traditional supervised learning methods.
Evaluating Self-Supervised Pretraining Without Using Labels
Sep 16, 2020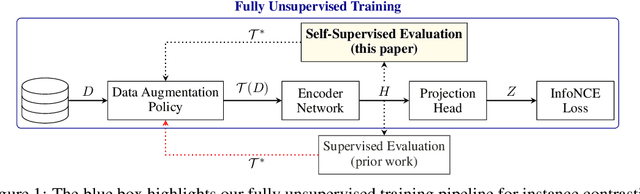
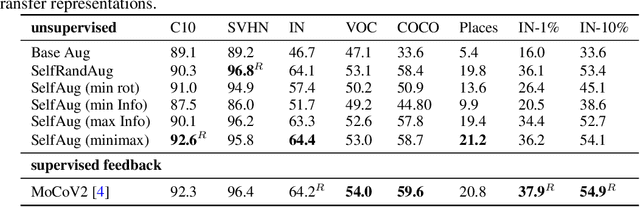
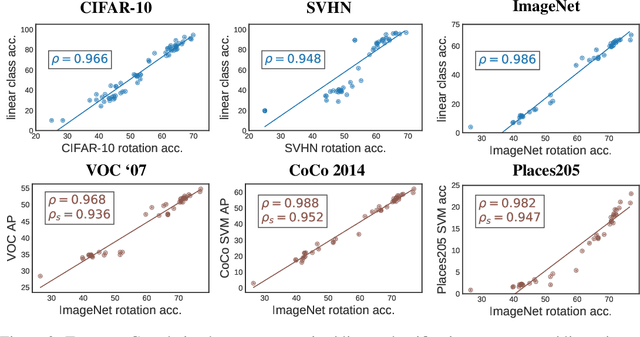
A common practice in unsupervised representation learning is to use labeled data to evaluate the learned representations - oftentimes using the labels from the "unlabeled" training dataset. This supervised evaluation is then used to guide the training process, e.g. to select augmentation policies. However, supervised evaluations may not be possible when labeled data is difficult to obtain (such as medical imaging) or ambiguous to label (such as fashion categorization). This raises the question: is it possible to evaluate unsupervised models without using labeled data? Furthermore, is it possible to use this evaluation to make decisions about the training process, such as which augmentation policies to use? In this work, we show that the simple self-supervised evaluation task of image rotation prediction is highly correlated with the supervised performance of standard visual recognition tasks and datasets (rank correlation > 0.94). We establish this correlation across hundreds of augmentation policies and training schedules and show how this evaluation criteria can be used to automatically select augmentation policies without using labels. Despite not using any labeled data, these policies perform comparably with policies that were determined using supervised downstream tasks. Importantly, this work explores the idea of using unsupervised evaluation criteria to help both researchers and practitioners make decisions when training without labeled data.
Multi-source Domain Adaptation in the Deep Learning Era: A Systematic Survey
Feb 26, 2020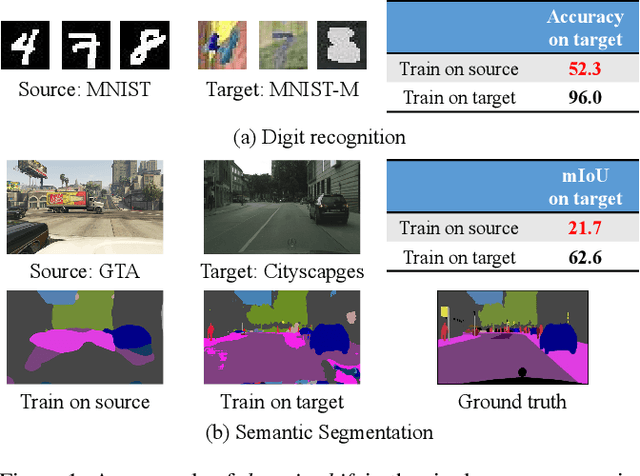


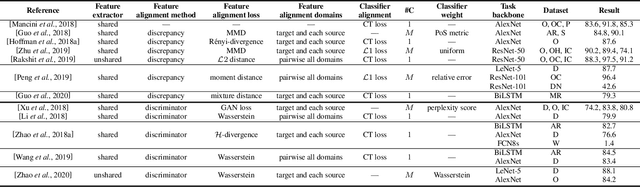
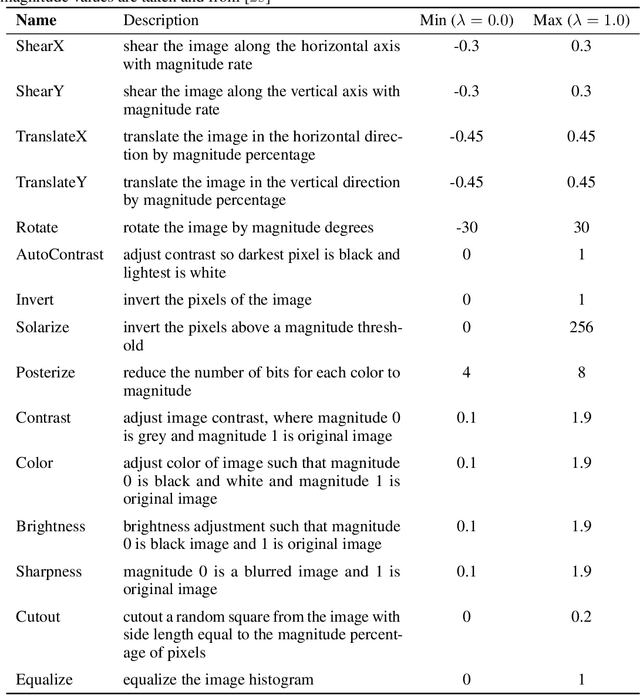
In many practical applications, it is often difficult and expensive to obtain enough large-scale labeled data to train deep neural networks to their full capability. Therefore, transferring the learned knowledge from a separate, labeled source domain to an unlabeled or sparsely labeled target domain becomes an appealing alternative. However, direct transfer often results in significant performance decay due to domain shift. Domain adaptation (DA) addresses this problem by minimizing the impact of domain shift between the source and target domains. Multi-source domain adaptation (MDA) is a powerful extension in which the labeled data may be collected from multiple sources with different distributions. Due to the success of DA methods and the prevalence of multi-source data, MDA has attracted increasing attention in both academia and industry. In this survey, we define various MDA strategies and summarize available datasets for evaluation. We also compare modern MDA methods in the deep learning era, including latent space transformation and intermediate domain generation. Finally, we discuss future research directions for MDA.
Scaling the Indian Buffet Process via Submodular Maximization
Jul 24, 2013
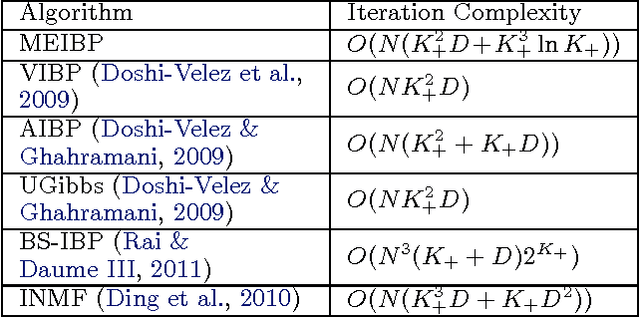

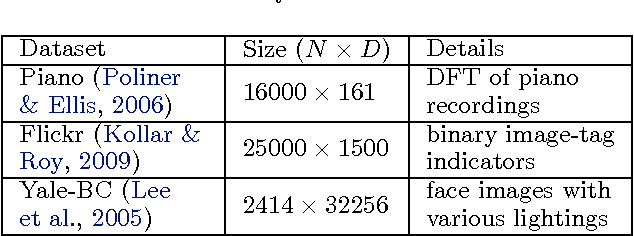
Inference for latent feature models is inherently difficult as the inference space grows exponentially with the size of the input data and number of latent features. In this work, we use Kurihara & Welling (2008)'s maximization-expectation framework to perform approximate MAP inference for linear-Gaussian latent feature models with an Indian Buffet Process (IBP) prior. This formulation yields a submodular function of the features that corresponds to a lower bound on the model evidence. By adding a constant to this function, we obtain a nonnegative submodular function that can be maximized via a greedy algorithm that obtains at least a one-third approximation to the optimal solution. Our inference method scales linearly with the size of the input data, and we show the efficacy of our method on the largest datasets currently analyzed using an IBP model.
* 13 pages, 8 figures