 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-source Few-shot Domain Adaptation
Sep 25, 2021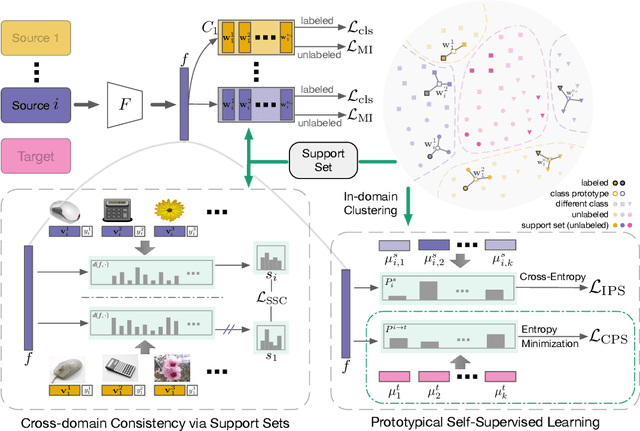
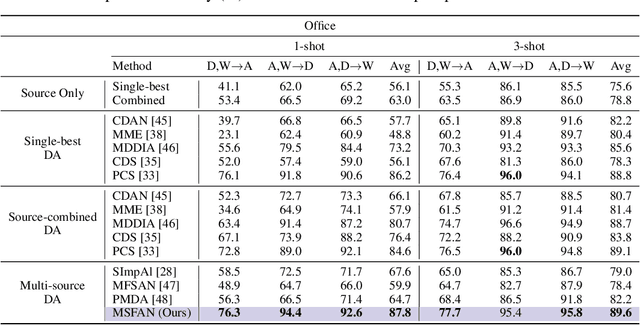
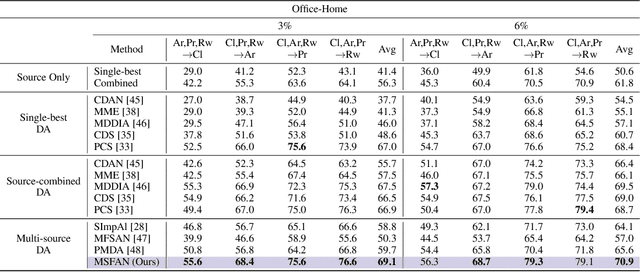

Multi-source Domain Adaptation (MDA) aims to transfer predictive models from multiple, fully-labeled source domains to an unlabeled target domain. However, in many applications, relevant labeled source datasets may not be available, and collecting source labels can be as expensive as labeling the target data itself. In this paper, we investigate Multi-source Few-shot Domain Adaptation (MFDA): a new domain adaptation scenario with limited multi-source labels and unlabeled target data. As we show, existing methods often fail to learn discriminative features for both source and target domains in the MFDA setting. Therefore, we propose a novel framework, termed Multi-Source Few-shot Adaptation Network (MSFAN), which can be trained end-to-end in a non-adversarial manner. MSFAN operates by first using a type of prototypical, multi-domain, self-supervised learning to learn features that are not only domain-invariant but also class-discriminative. Second, MSFAN uses a small, labeled support set to enforce feature consistency and domain invariance across domains. Finally, prototypes from multiple sources are leveraged to learn better classifiers. Compared with state-of-the-art MDA methods, MSFAN improves the mean classification accuracy over different domain pairs on MFDA by 20.2%, 9.4%, and 16.2% on Office, Office-Home, and DomainNet, respectively.
Scene-aware Learning Network for Radar Object Detection
Jul 03, 2021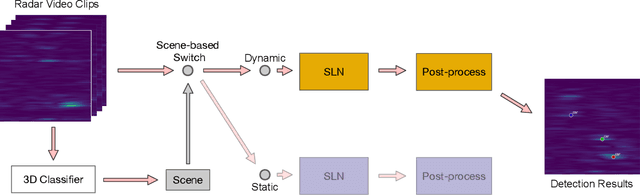
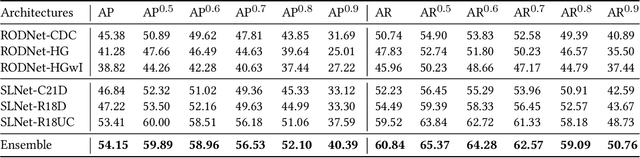
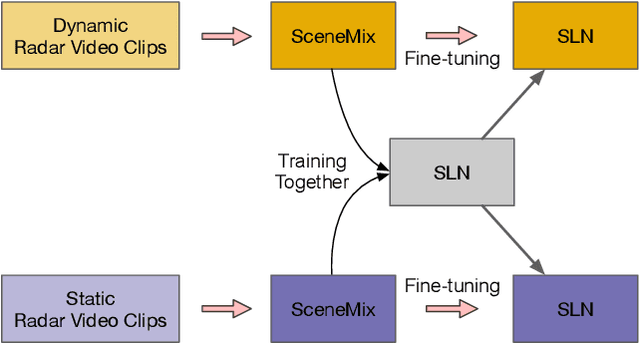

Object detection is essential to safe autonomous or assisted driving. Previous works usually utilize RGB images or LiDAR point clouds to identify and localize multiple objects in self-driving. However, cameras tend to fail in bad driving conditions, e.g. bad weather or weak lighting, while LiDAR scanners are too expensive to get widely deployed in commercial applications. Radar has been drawing more and more attention due to its robustness and low cost. In this paper, we propose a scene-aware radar learning framework for accurate and robust object detection. First, the learning framework contains branches conditioning on the scene category of the radar sequence; with each branch optimized for a specific type of scene. Second, three different 3D autoencoder-based architectures are proposed for radar object detection and ensemble learning is performed over the different architectures to further boost the final performance. Third, we propose novel scene-aware sequence mix augmentation (SceneMix) and scene-specific post-processing to generate more robust detection results. In the ROD2021 Challenge, we achieved a final result of average precision of 75.0% and an average recall of 81.0%. Moreover, in the parking lot scene, our framework ranks first with an average precision of 97.8% and an average recall of 98.6%, which demonstrates the effectiveness of our framework.
Prototypical Cross-domain Self-supervised Learning for Few-shot Unsupervised Domain Adaptation
Mar 31, 2021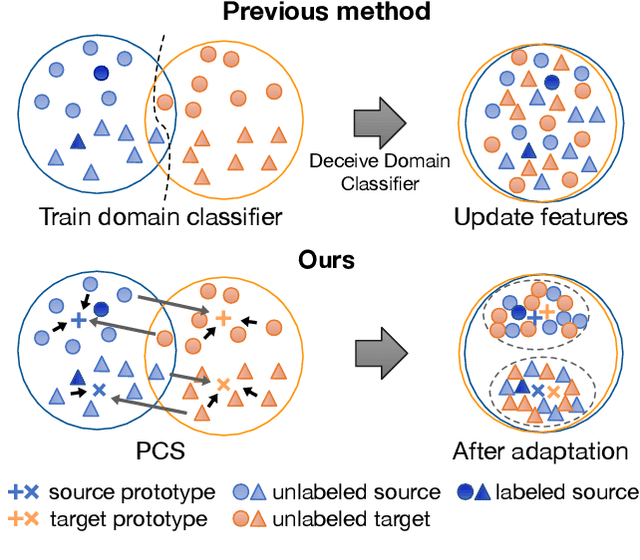

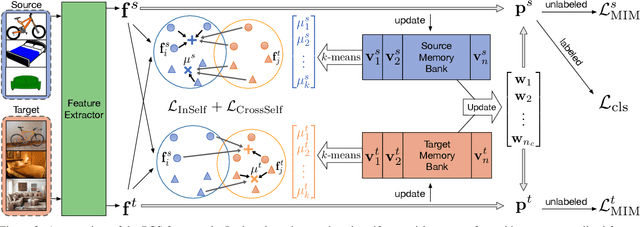
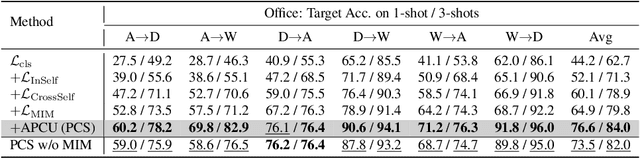
Unsupervised Domain Adaptation (UDA) transfers predictive models from a fully-labeled source domain to an unlabeled target domain. In some applications, however, it is expensive even to collect labels in the source domain, making most previous works impractical. To cope with this problem, recent work performed instance-wise cross-domain self-supervised learning, followed by an additional fine-tuning stage. However, the instance-wise self-supervised learning only learns and aligns low-level discriminative features. In this paper, we propose an end-to-end Prototypical Cross-domain Self-Supervised Learning (PCS) framework for Few-shot Unsupervised Domain Adaptation (FUDA). PCS not only performs cross-domain low-level feature alignment, but it also encodes and aligns semantic structures in the shared embedding space across domains. Our framework captures category-wise semantic structures of the data by in-domain prototypical contrastive learning; and performs feature alignment through cross-domain prototypical self-supervision. Compared with state-of-the-art methods, PCS improves the mean classification accuracy over different domain pairs on FUDA by 10.5%, 3.5%, 9.0%, and 13.2% on Office, Office-Home, VisDA-2017, and DomainNet, respectively. Our project page is at http://xyue.io/pcs-fuda/index.html
Generalizing Fault Detection Against Domain Shifts Using Stratification-Aware Cross-Validation
Aug 20, 2020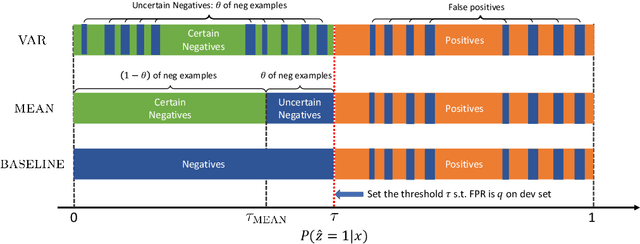
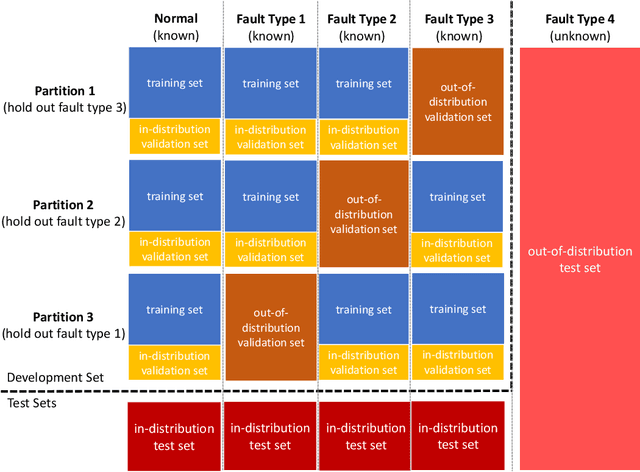
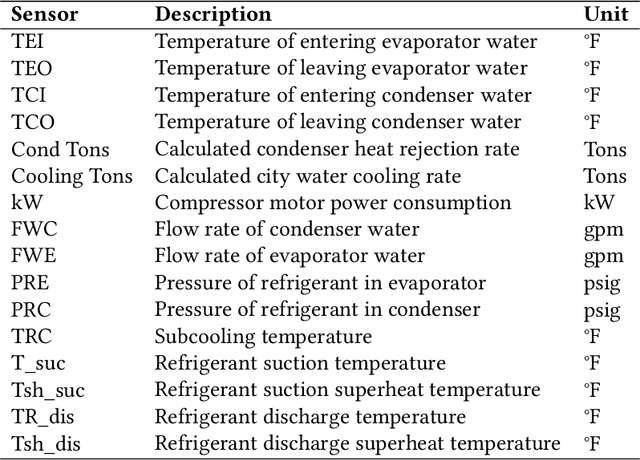
Incipient anomalies present milder symptoms compared to severe ones, and are more difficult to detect and diagnose due to their close resemblance to normal operating conditions. The lack of incipient anomaly examples in the training data can pose severe risks to anomaly detection methods that are built upon Machine Learning (ML) techniques, because these anomalies can be easily mistaken as normal operating conditions. To address this challenge, we propose to utilize the uncertainty information available from ensemble learning to identify potential misclassified incipient anomalies. We show in this paper that ensemble learning methods can give improved performance on incipient anomalies and identify common pitfalls in these models through extensive experiments on two real-world datasets. Then, we discuss how to design more effective ensemble models for detecting incipient anomalies.
Using Ensemble Classifiers to Detect Incipient Anomalies
Aug 20, 2020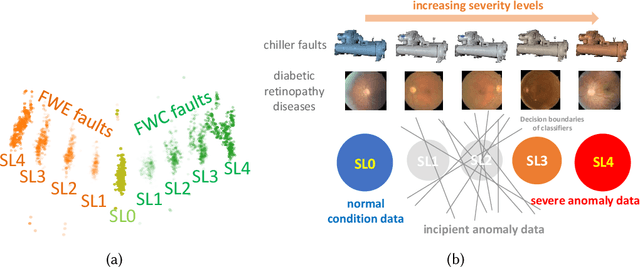

Incipient anomalies present milder symptoms compared to severe ones, and are more difficult to detect and diagnose due to their close resemblance to normal operating conditions. The lack of incipient anomaly examples in the training data can pose severe risks to anomaly detection methods that are built upon Machine Learning (ML) techniques, because these anomalies can be easily mistaken as normal operating conditions. To address this challenge, we propose to utilize the uncertainty information available from ensemble learning to identify potential misclassified incipient anomalies. We show in this paper that ensemble learning methods can give improved performance on incipient anomalies and identify common pitfalls in these models through extensive experiments on two real-world datasets. Then, we discuss how to design more effective ensemble models for detecting incipient anomalies.
Exploiting Uncertainties from Ensemble Learners to Improve Decision-Making in Healthcare AI
Jul 12, 2020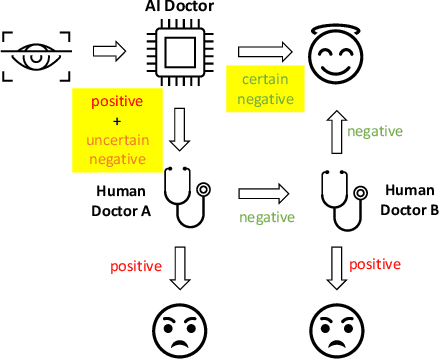
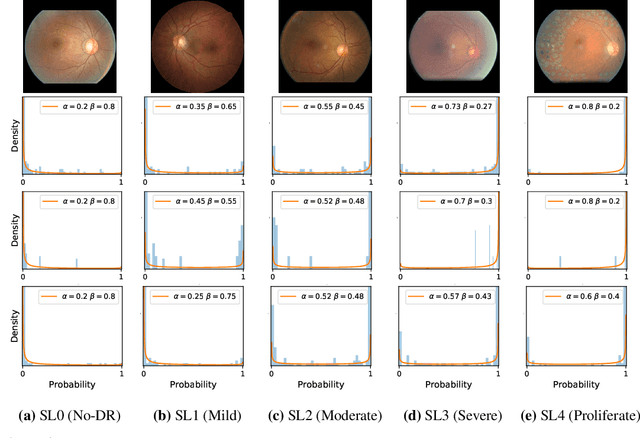
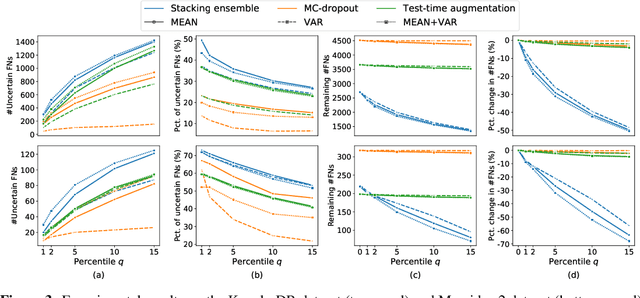
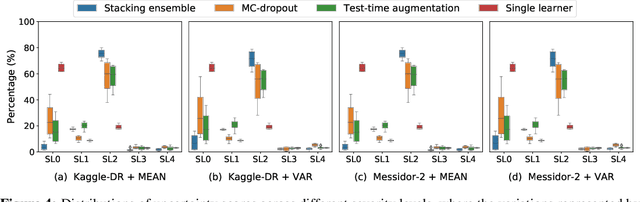
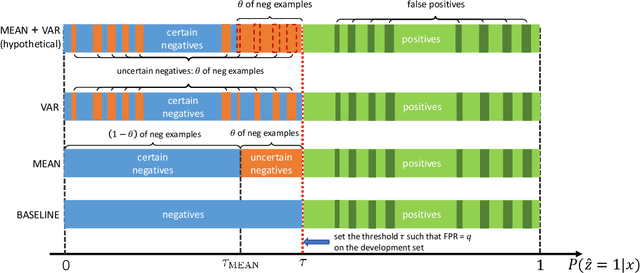
Ensemble learning is widely applied in Machine Learning (ML) to improve model performance and to mitigate decision risks. In this approach, predictions from a diverse set of learners are combined to obtain a joint decision. Recently, various methods have been explored in literature for estimating decision uncertainties using ensemble learning; however, determining which metrics are a better fit for certain decision-making applications remains a challenging task. In this paper, we study the following key research question in the selection of uncertainty metrics: when does an uncertainty metric outperforms another? We answer this question via a rigorous analysis of two commonly used uncertainty metrics in ensemble learning, namely ensemble mean and ensemble variance. We show that, under mild assumptions on the ensemble learners, ensemble mean is preferable with respect to ensemble variance as an uncertainty metric for decision making. We empirically validate our assumptions and theoretical results via an extensive case study: the diagnosis of referable diabetic retinopathy.
Are Ensemble Classifiers Powerful Enough for the Detection and Diagnosis of Intermediate-Severity Faults?
Jul 08, 2020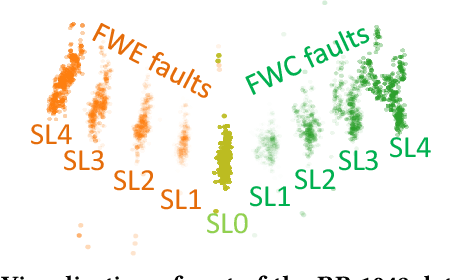

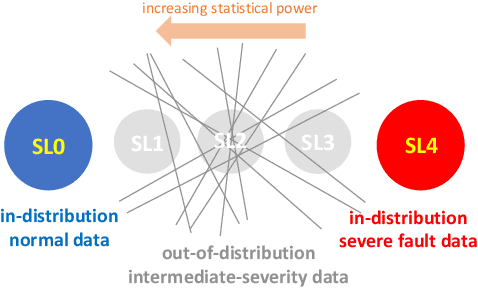
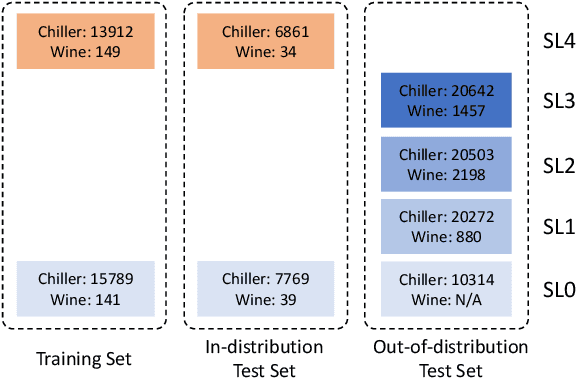
Intermediate-Severity (IS) faults present milder symptoms compared to severe faults, and are more difficult to detect and diagnose due to their close resemblance to normal operating conditions. The lack of IS fault examples in the training data can pose severe risks to Fault Detection and Diagnosis (FDD) methods that are built upon Machine Learning (ML) techniques, because these faults can be easily mistaken as normal operating conditions. Ensemble models are widely applied in ML and are considered promising methods for detecting out-of-distribution (OOD) data. We identify common pitfalls in these models through extensive experiments with several popular ensemble models on two real-world datasets. Then, we discuss how to design more effective ensemble models for detecting and diagnosing IS faults.
An Encoder-Decoder Based Approach for Anomaly Detection with Application in Additive Manufacturing
Jul 26, 2019
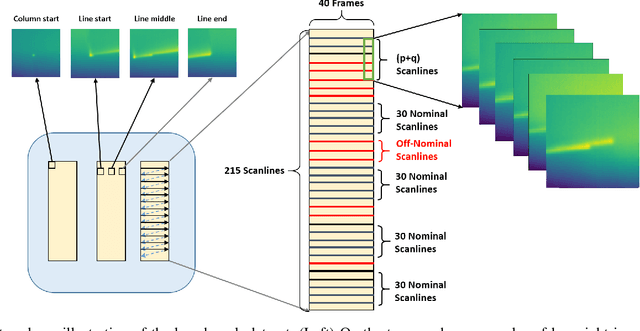
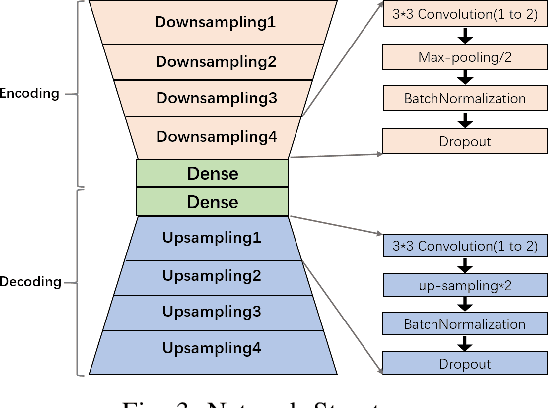
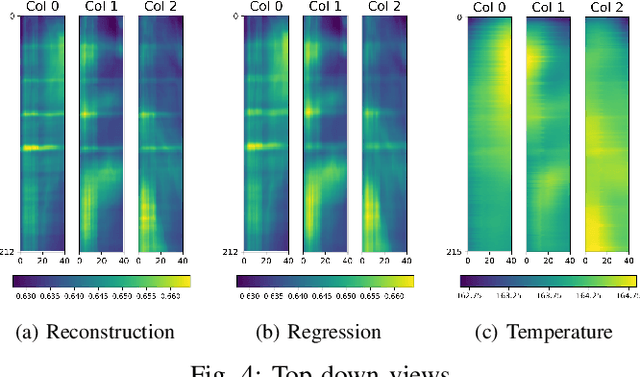
We present a novel unsupervised deep learning approach that utilizes the encoder-decoder architecture for detecting anomalies in sequential sensor data collected during industrial manufacturing. Our approach is designed not only to detect whether there exists an anomaly at a given time step, but also to predict what will happen next in the (sequential) process. We demonstrate our approach on a dataset collected from a real-world testbed. The dataset contains images collected under both normal conditions and synthetic anomalies. We show that the encoder-decoder model is able to identify the injected anomalies in a modern manufacturing process in an unsupervised fashion. In addition, it also gives hints about the temperature non-uniformity of the testbed during manufacturing, which is what we are not aware of before doing the experiment.