 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepurposing the scientific literature with vision-language models
Feb 26, 2025Research in AI for Science often focuses on using AI technologies to augment components of the scientific process, or in some cases, the entire scientific method; how about AI for scientific publications? Peer-reviewed journals are foundational repositories of specialized knowledge, written in discipline-specific language that differs from general Internet content used to train most large language models (LLMs) and vision-language models (VLMs). We hypothesized that by combining a family of scientific journals with generative AI models, we could invent novel tools for scientific communication, education, and clinical care. We converted 23,000 articles from Neurosurgery Publications into a multimodal database - NeuroPubs - of 134 million words and 78,000 image-caption pairs to develop six datasets for building AI models. We showed that the content of NeuroPubs uniquely represents neurosurgery-specific clinical contexts compared with broader datasets and PubMed. For publishing, we employed generalist VLMs to automatically generate graphical abstracts from articles. Editorial board members rated 70% of these as ready for publication without further edits. For education, we generated 89,587 test questions in the style of the ABNS written board exam, which trainee and faculty neurosurgeons found indistinguishable from genuine examples 54% of the time. We used these questions alongside a curriculum learning process to track knowledge acquisition while training our 34 billion-parameter VLM (CNS-Obsidian). In a blinded, randomized controlled trial, we demonstrated the non-inferiority of CNS-Obsidian to GPT-4o (p = 0.1154) as a diagnostic copilot for a neurosurgical service. Our findings lay a novel foundation for AI with Science and establish a framework to elevate scientific communication using state-of-the-art generative artificial intelligence while maintaining rigorous quality standards.
Samplable Anonymous Aggregation for Private Federated Data Analysis
Jul 27, 2023We revisit the problem of designing scalable protocols for private statistics and private federated learning when each device holds its private data. Our first contribution is to propose a simple primitive that allows for efficient implementation of several commonly used algorithms, and allows for privacy accounting that is close to that in the central setting without requiring the strong trust assumptions it entails. Second, we propose a system architecture that implements this primitive and perform a security analysis of the proposed system.
Using Ensemble Classifiers to Detect Incipient Anomalies
Aug 20, 2020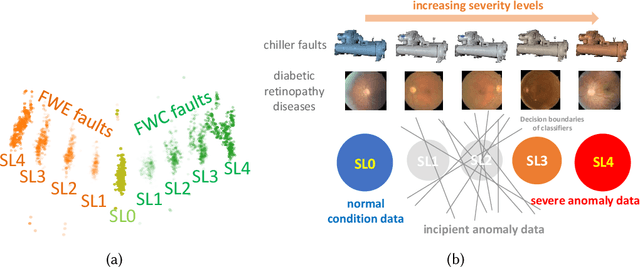
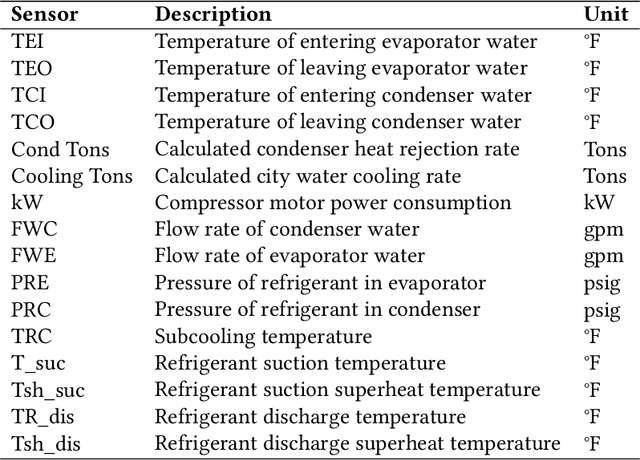
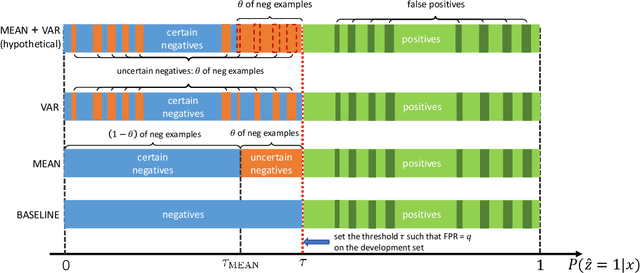

Incipient anomalies present milder symptoms compared to severe ones, and are more difficult to detect and diagnose due to their close resemblance to normal operating conditions. The lack of incipient anomaly examples in the training data can pose severe risks to anomaly detection methods that are built upon Machine Learning (ML) techniques, because these anomalies can be easily mistaken as normal operating conditions. To address this challenge, we propose to utilize the uncertainty information available from ensemble learning to identify potential misclassified incipient anomalies. We show in this paper that ensemble learning methods can give improved performance on incipient anomalies and identify common pitfalls in these models through extensive experiments on two real-world datasets. Then, we discuss how to design more effective ensemble models for detecting incipient anomalies.