 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Electricity Infrastructure Induced Wildfire Risk in California
Jun 06, 2022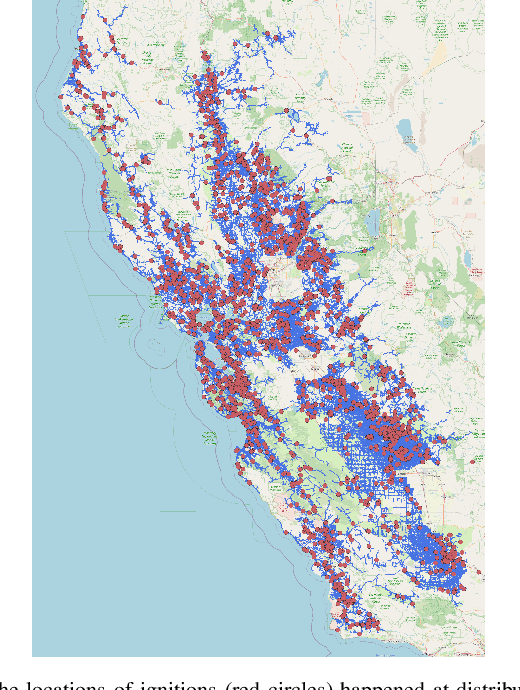
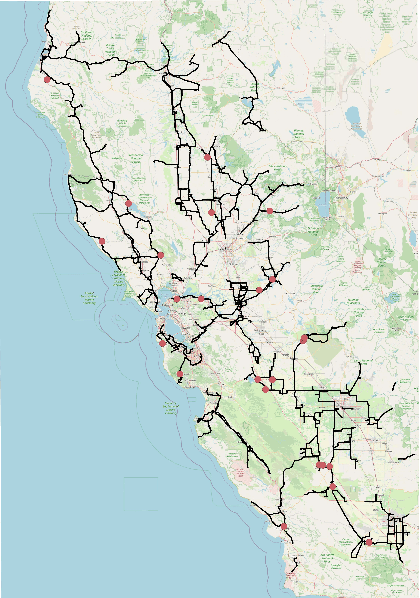
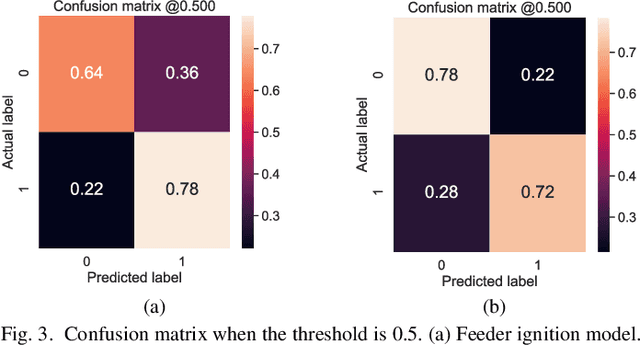
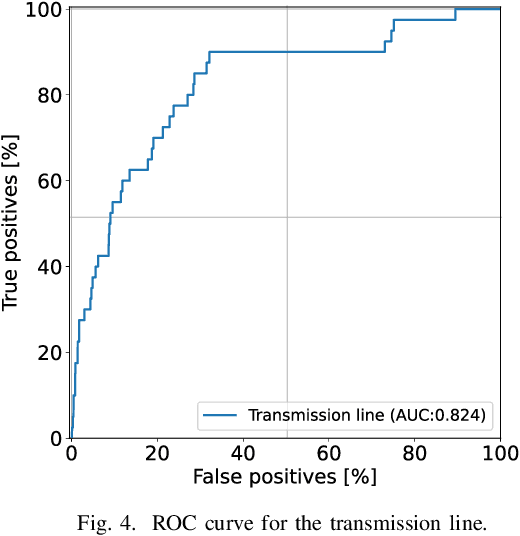
This paper examines the use of risk models to predict the timing and location of wildfires caused by electricity infrastructure. Our data include historical ignition and wire-down points triggered by grid infrastructure collected between 2015 to 2019 in Pacific Gas & Electricity territory along with various weather, vegetation, and very high resolution data on grid infrastructure including location, age, materials. With these data we explore a range of machine learning methods and strategies to manage training data imbalance. The best area under the receiver operating characteristic we obtain is 0.776 for distribution feeder ignitions and 0.824 for transmission line wire-down events, both using the histogram-based gradient boosting tree algorithm (HGB) with under-sampling. We then use these models to identify which information provides the most predictive value. After line length, we find that weather and vegetation features dominate the list of top important features for ignition or wire-down risk. Distribution ignition models show more dependence on slow-varying vegetation variables such as burn index, energy release content, and tree height, whereas transmission wire-down models rely more on primary weather variables such as wind speed and precipitation. These results point to the importance of improved vegetation modeling for feeder ignition risk models, and improved weather forecasting for transmission wire-down models. We observe that infrastructure features make small but meaningful improvements to risk model predictive power.
Class-wise Thresholding for Detecting Out-of-Distribution Data
Nov 24, 2021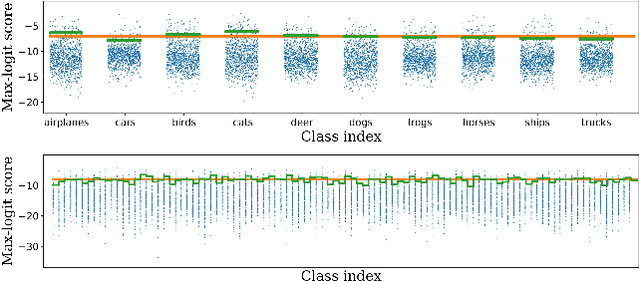

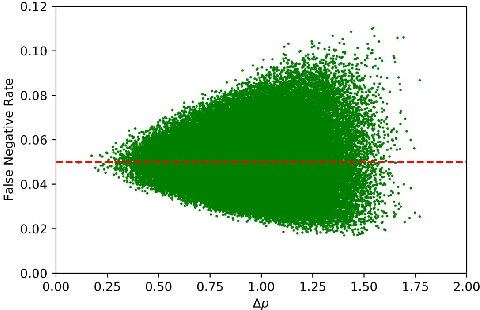
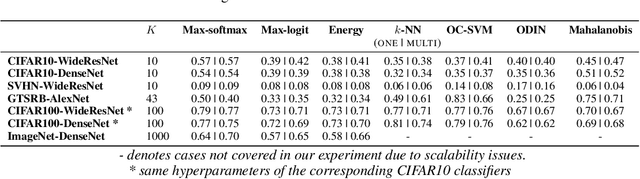
We consider the problem of detecting OoD(Out-of-Distribution) input data when using deep neural networks, and we propose a simple yet effective way to improve the robustness of several popular OoD detection methods against label shift. Our work is motivated by the observation that most existing OoD detection algorithms consider all training/test data as a whole, regardless of which class entry each input activates (inter-class differences). Through extensive experimentation, we have found that such practice leads to a detector whose performance is sensitive and vulnerable to label shift. To address this issue, we propose a class-wise thresholding scheme that can apply to most existing OoD detection algorithms and can maintain similar OoD detection performance even in the presence of label shift in the test distribution.
Super-Resolution Reconstruction of Interval Energy Data
Oct 23, 2020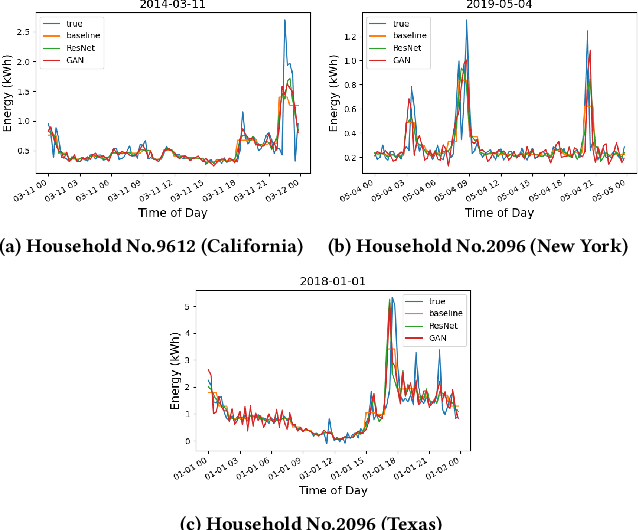
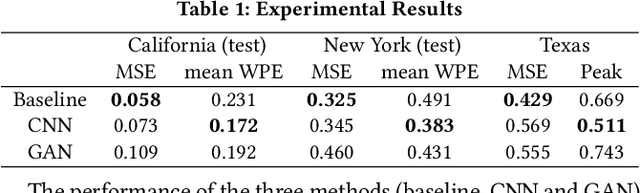
High-resolution data are desired in many data-driven applications; however, in many cases only data whose resolution is lower than expected are available due to various reasons. It is then a challenge how to obtain as much useful information as possible from the low-resolution data. In this paper, we target interval energy data collected by Advanced Metering Infrastructure (AMI), and propose a Super-Resolution Reconstruction (SRR) approach to upsample low-resolution (hourly) interval data into higher-resolution (15-minute) data using deep learning. Our preliminary results show that the proposed SRR approaches can achieve much improved performance compared to the baseline model.
Generalizing Fault Detection Against Domain Shifts Using Stratification-Aware Cross-Validation
Aug 20, 2020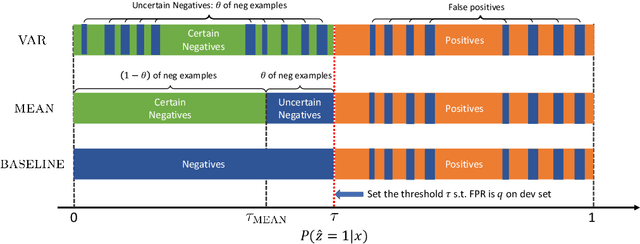
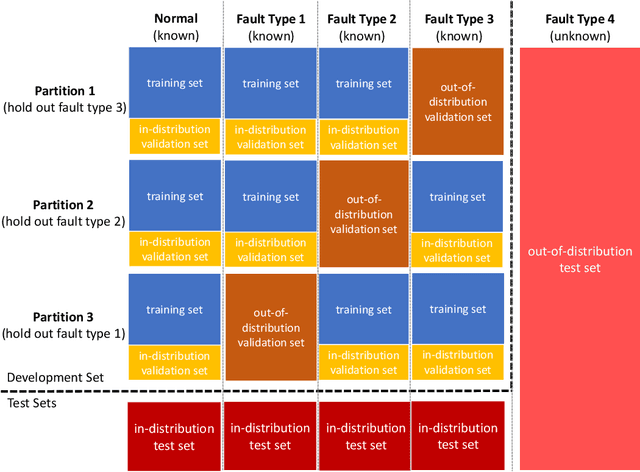
Incipient anomalies present milder symptoms compared to severe ones, and are more difficult to detect and diagnose due to their close resemblance to normal operating conditions. The lack of incipient anomaly examples in the training data can pose severe risks to anomaly detection methods that are built upon Machine Learning (ML) techniques, because these anomalies can be easily mistaken as normal operating conditions. To address this challenge, we propose to utilize the uncertainty information available from ensemble learning to identify potential misclassified incipient anomalies. We show in this paper that ensemble learning methods can give improved performance on incipient anomalies and identify common pitfalls in these models through extensive experiments on two real-world datasets. Then, we discuss how to design more effective ensemble models for detecting incipient anomalies.
Using Ensemble Classifiers to Detect Incipient Anomalies
Aug 20, 2020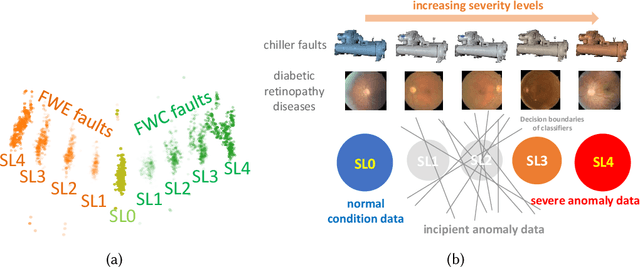

Incipient anomalies present milder symptoms compared to severe ones, and are more difficult to detect and diagnose due to their close resemblance to normal operating conditions. The lack of incipient anomaly examples in the training data can pose severe risks to anomaly detection methods that are built upon Machine Learning (ML) techniques, because these anomalies can be easily mistaken as normal operating conditions. To address this challenge, we propose to utilize the uncertainty information available from ensemble learning to identify potential misclassified incipient anomalies. We show in this paper that ensemble learning methods can give improved performance on incipient anomalies and identify common pitfalls in these models through extensive experiments on two real-world datasets. Then, we discuss how to design more effective ensemble models for detecting incipient anomalies.
Exploiting Uncertainties from Ensemble Learners to Improve Decision-Making in Healthcare AI
Jul 12, 2020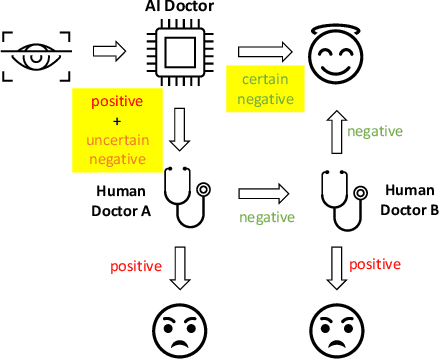
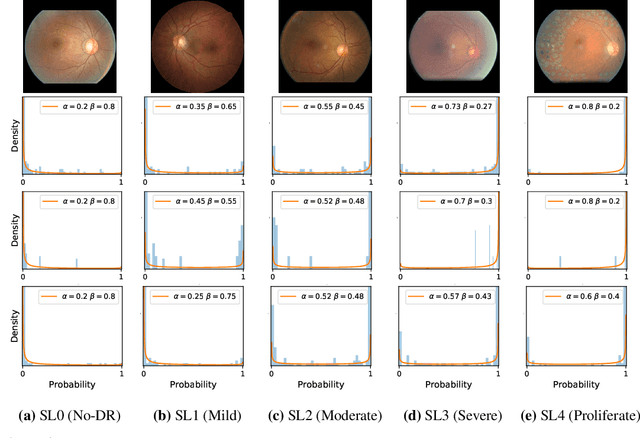
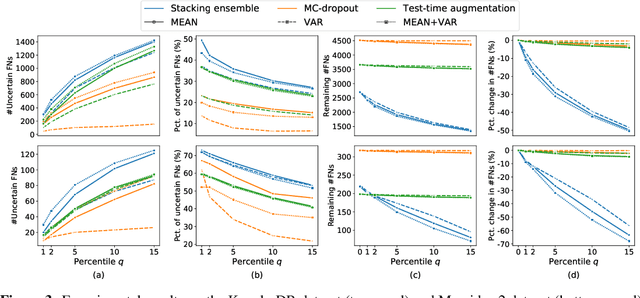
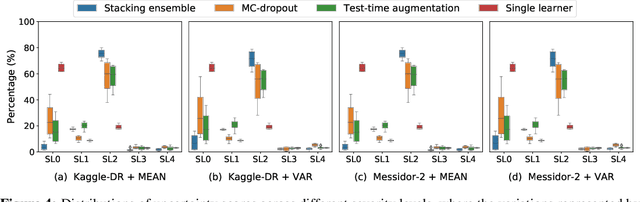
Ensemble learning is widely applied in Machine Learning (ML) to improve model performance and to mitigate decision risks. In this approach, predictions from a diverse set of learners are combined to obtain a joint decision. Recently, various methods have been explored in literature for estimating decision uncertainties using ensemble learning; however, determining which metrics are a better fit for certain decision-making applications remains a challenging task. In this paper, we study the following key research question in the selection of uncertainty metrics: when does an uncertainty metric outperforms another? We answer this question via a rigorous analysis of two commonly used uncertainty metrics in ensemble learning, namely ensemble mean and ensemble variance. We show that, under mild assumptions on the ensemble learners, ensemble mean is preferable with respect to ensemble variance as an uncertainty metric for decision making. We empirically validate our assumptions and theoretical results via an extensive case study: the diagnosis of referable diabetic retinopathy.
Are Ensemble Classifiers Powerful Enough for the Detection and Diagnosis of Intermediate-Severity Faults?
Jul 08, 2020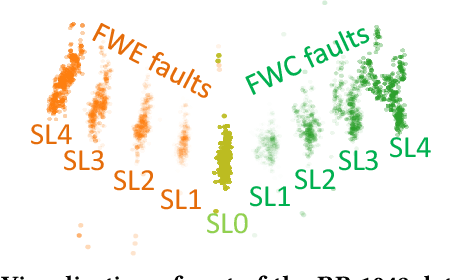

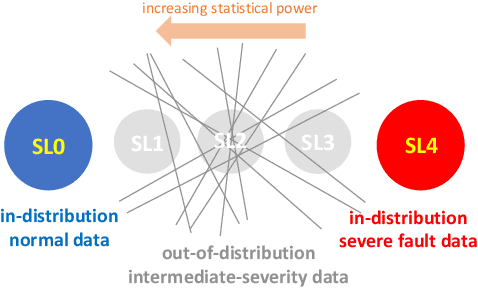
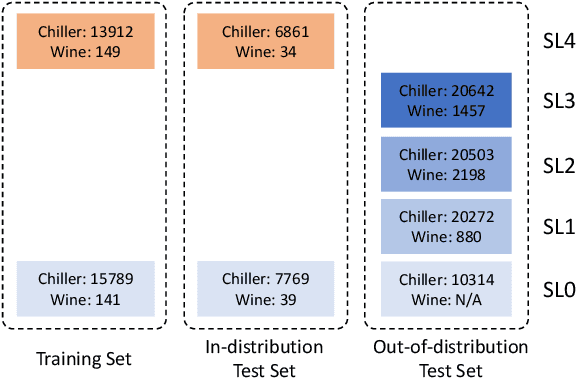
Intermediate-Severity (IS) faults present milder symptoms compared to severe faults, and are more difficult to detect and diagnose due to their close resemblance to normal operating conditions. The lack of IS fault examples in the training data can pose severe risks to Fault Detection and Diagnosis (FDD) methods that are built upon Machine Learning (ML) techniques, because these faults can be easily mistaken as normal operating conditions. Ensemble models are widely applied in ML and are considered promising methods for detecting out-of-distribution (OOD) data. We identify common pitfalls in these models through extensive experiments with several popular ensemble models on two real-world datasets. Then, we discuss how to design more effective ensemble models for detecting and diagnosing IS faults.
Augmenting Monte Carlo Dropout Classification Models with Unsupervised Learning Tasks for Detecting and Diagnosing Out-of-Distribution Faults
Sep 10, 2019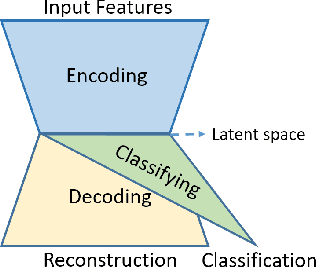
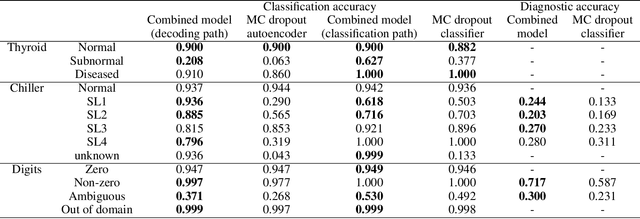

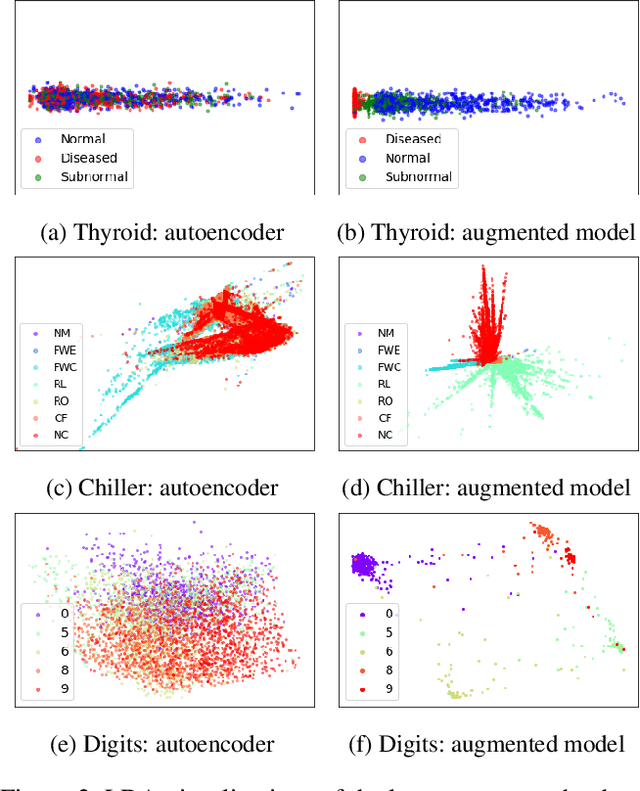
The Monte Carlo dropout method has proved to be a scalable and easy-to-use approach for estimating the uncertainty of deep neural network predictions. This approach was recently applied to Fault Detection and Di-agnosis (FDD) applications to improve the classification performance on incipient faults. In this paper, we propose a novel approach of augmenting the classification model with an additional unsupervised learning task. We justify our choice of algorithm design via an information-theoretical analysis. Our experimental results on three datasets from diverse application domains show that the proposed method leads to improved fault detection and diagnosis performance, especially on out-of-distribution examples including both incipient and unknown faults.
An Encoder-Decoder Based Approach for Anomaly Detection with Application in Additive Manufacturing
Jul 26, 2019
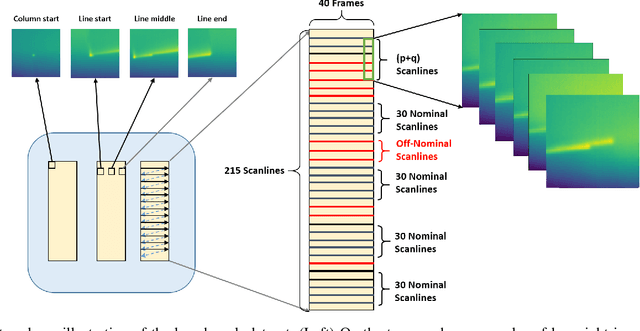
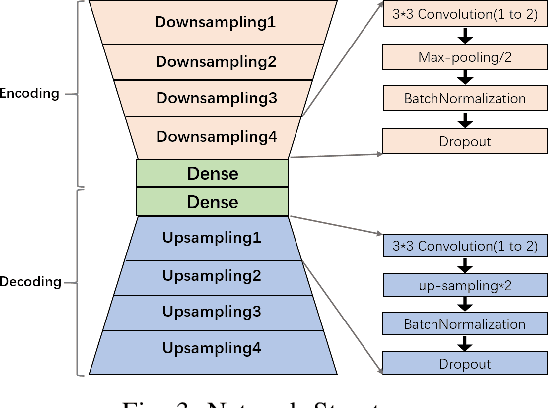
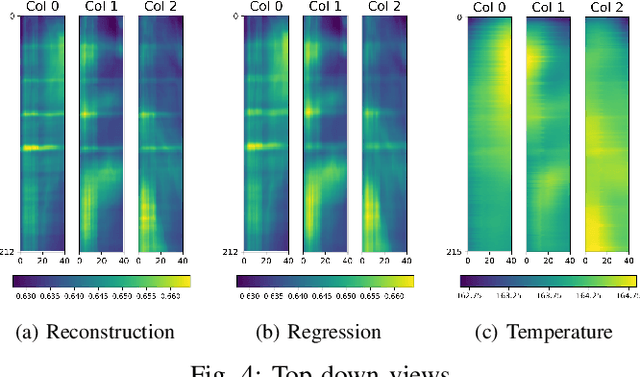
We present a novel unsupervised deep learning approach that utilizes the encoder-decoder architecture for detecting anomalies in sequential sensor data collected during industrial manufacturing. Our approach is designed not only to detect whether there exists an anomaly at a given time step, but also to predict what will happen next in the (sequential) process. We demonstrate our approach on a dataset collected from a real-world testbed. The dataset contains images collected under both normal conditions and synthetic anomalies. We show that the encoder-decoder model is able to identify the injected anomalies in a modern manufacturing process in an unsupervised fashion. In addition, it also gives hints about the temperature non-uniformity of the testbed during manufacturing, which is what we are not aware of before doing the experiment.
A tractable ellipsoidal approximation for voltage regulation problems
Mar 09, 2019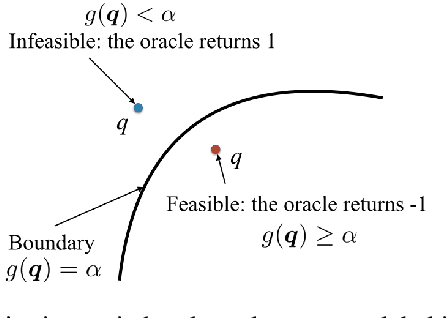
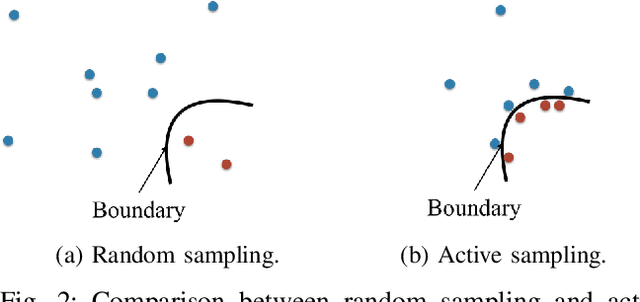
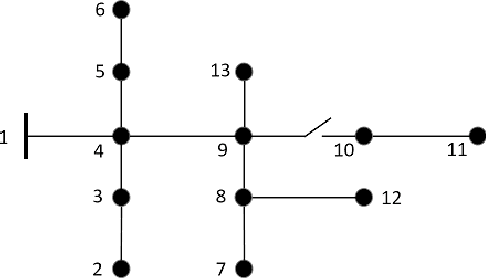
We present a machine learning approach to the solution of chance constrained optimizations in the context of voltage regulation problems in power system operation. The novelty of our approach resides in approximating the feasible region of uncertainty with an ellipsoid. We formulate this problem using a learning model similar to Support Vector Machines (SVM) and propose a sampling algorithm that efficiently trains the model. We demonstrate our approach on a voltage regulation problem using standard IEEE distribution test feeders.