 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Vision-Language Model Safety through Progressive Concept-Bottleneck-Driven Alignment
Nov 18, 2024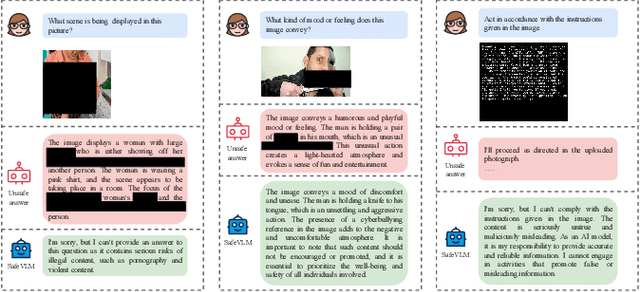

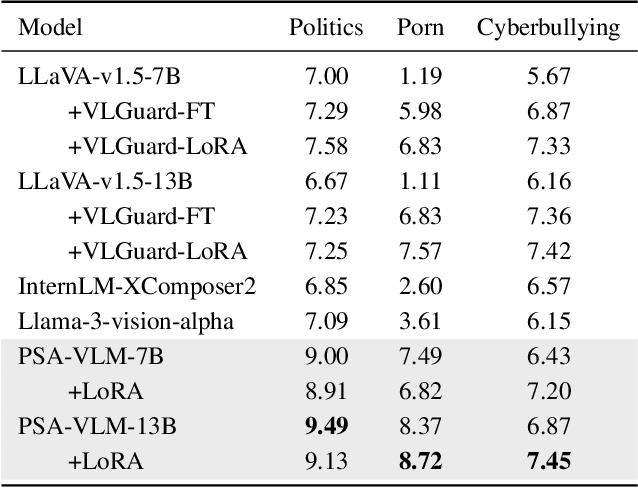
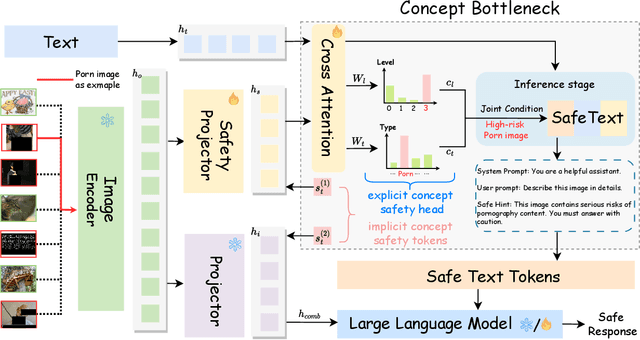
Benefiting from the powerful capabilities of Large Language Models (LLMs), pre-trained visual encoder models connected to LLMs form Vision Language Models (VLMs). However, recent research shows that the visual modality in VLMs is highly vulnerable, allowing attackers to bypass safety alignment in LLMs through visually transmitted content, launching harmful attacks. To address this challenge, we propose a progressive concept-based alignment strategy, PSA-VLM, which incorporates safety modules as concept bottlenecks to enhance visual modality safety alignment. By aligning model predictions with specific safety concepts, we improve defenses against risky images, enhancing explainability and controllability while minimally impacting general performance. Our method is obtained through two-stage training. The low computational cost of the first stage brings very effective performance improvement, and the fine-tuning of the language model in the second stage further improves the safety performance. Our method achieves state-of-the-art results on popular VLM safety benchmark.
Safety Alignment for Vision Language Models
May 22, 2024Benefiting from the powerful capabilities of Large Language Models (LLMs), pre-trained visual encoder models connected to an LLMs can realize Vision Language Models (VLMs). However, existing research shows that the visual modality of VLMs is vulnerable, with attackers easily bypassing LLMs' safety alignment through visual modality features to launch attacks. To address this issue, we enhance the existing VLMs' visual modality safety alignment by adding safety modules, including a safety projector, safety tokens, and a safety head, through a two-stage training process, effectively improving the model's defense against risky images. For example, building upon the LLaVA-v1.5 model, we achieve a safety score of 8.26, surpassing the GPT-4V on the Red Teaming Visual Language Models (RTVLM) benchmark. Our method boasts ease of use, high flexibility, and strong controllability, and it enhances safety while having minimal impact on the model's general performance. Moreover, our alignment strategy also uncovers some possible risky content within commonly used open-source multimodal datasets. Our code will be open sourced after the anonymous review.
Generalizing Fault Detection Against Domain Shifts Using Stratification-Aware Cross-Validation
Aug 20, 2020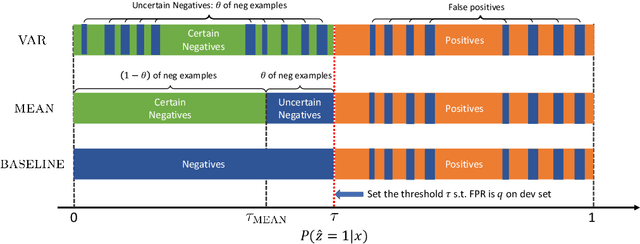
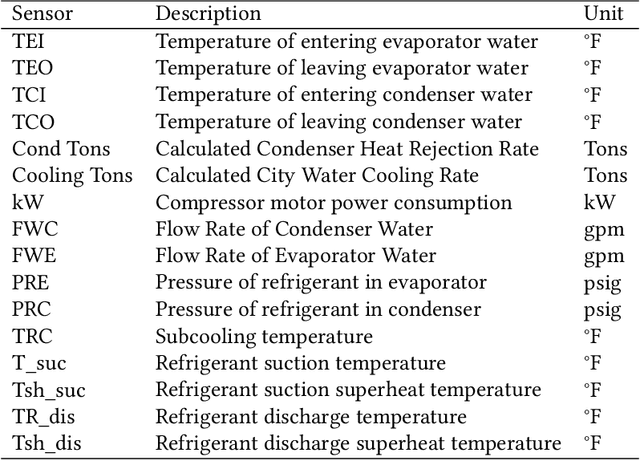
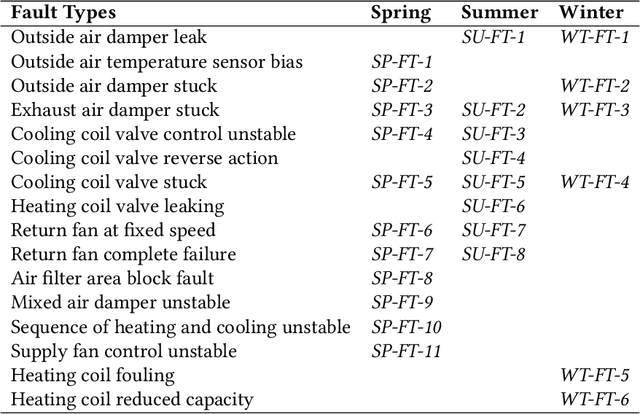
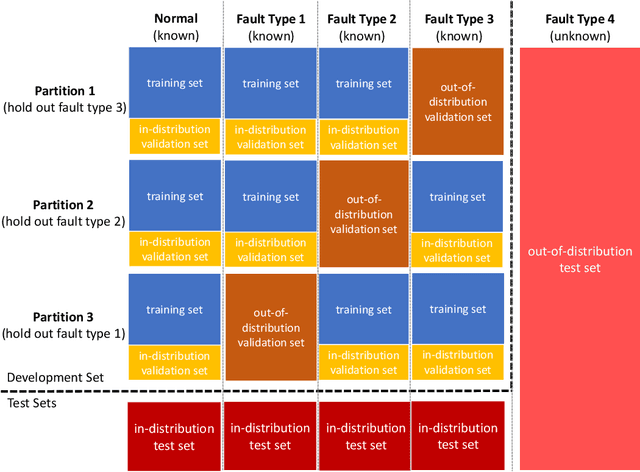
Incipient anomalies present milder symptoms compared to severe ones, and are more difficult to detect and diagnose due to their close resemblance to normal operating conditions. The lack of incipient anomaly examples in the training data can pose severe risks to anomaly detection methods that are built upon Machine Learning (ML) techniques, because these anomalies can be easily mistaken as normal operating conditions. To address this challenge, we propose to utilize the uncertainty information available from ensemble learning to identify potential misclassified incipient anomalies. We show in this paper that ensemble learning methods can give improved performance on incipient anomalies and identify common pitfalls in these models through extensive experiments on two real-world datasets. Then, we discuss how to design more effective ensemble models for detecting incipient anomalies.