 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Aware Commitment Reduction for Network-Constrained Unit Commitment with Solver-Preserving Guarantees
Apr 03, 2026The growing number of individual generating units, hybrid resources, and security constraints has significantly increased the computational burden of network-constrained unit commitment (UC), where most solution time is spent exploring branch-and-bound trees over unit-hour binary variables. To reduce this combinatorial burden, recent approaches have explored learning-based guidance to assist commitment decisions. However, directly using tools such as large language models (LLMs) to predict full commitment schedules is unreliable, as infeasible or inconsistent binary decisions can violate inter-temporal constraints and degrade economic optimality. This paper proposes a solver-compatible dimensionality reduction framework for UC that exploits structural regularities in commitment decisions. Instead of generating complete schedules, the framework identifies a sparse subset of structurally stable commitment binaries to fix prior to optimization. One implementation uses an LLM to select these variables. The LLM does not replace the optimization process but provides partial variable restriction, while all constraints and remaining decisions are handled by the original MILP solver, which continues to enforce network, ramping, reserve, and security constraints. We formally show that the masked problem defines a reduced feasible region of the original UC model, thereby preserving feasibility and enabling solver-certified optimality within the restricted space. Experiments on IEEE 57-bus, RTS 73-bus, IEEE 118-bus, and augmented large-scale cases, including security-constrained variants, demonstrate consistent reductions in branch-and-bound nodes and solution time, achieving order-of-magnitude speedups on high-complexity instances while maintaining near-optimal objective values.
Flow-CDNet: A Novel Network for Detecting Both Slow and Fast Changes in Bitemporal Images
Jul 03, 2025Change detection typically involves identifying regions with changes between bitemporal images taken at the same location. Besides significant changes, slow changes in bitemporal images are also important in real-life scenarios. For instance, weak changes often serve as precursors to major hazards in scenarios like slopes, dams, and tailings ponds. Therefore, designing a change detection network that simultaneously detects slow and fast changes presents a novel challenge. In this paper, to address this challenge, we propose a change detection network named Flow-CDNet, consisting of two branches: optical flow branch and binary change detection branch. The first branch utilizes a pyramid structure to extract displacement changes at multiple scales. The second one combines a ResNet-based network with the optical flow branch's output to generate fast change outputs. Subsequently, to supervise and evaluate this new change detection framework, a self-built change detection dataset Flow-Change, a loss function combining binary tversky loss and L2 norm loss, along with a new evaluation metric called FEPE are designed. Quantitative experiments conducted on Flow-Change dataset demonstrated that our approach outperforms the existing methods. Furthermore, ablation experiments verified that the two branches can promote each other to enhance the detection performance.
Fast and Reliable $N-k$ Contingency Screening with Input-Convex Neural Networks
Oct 01, 2024



Power system operators must ensure that dispatch decisions remain feasible in case of grid outages or contingencies to prevent cascading failures and ensure reliable operation. However, checking the feasibility of all $N - k$ contingencies -- every possible simultaneous failure of $k$ grid components -- is computationally intractable for even small $k$, requiring system operators to resort to heuristic screening methods. Because of the increase in uncertainty and changes in system behaviors, heuristic lists might not include all relevant contingencies, generating false negatives in which unsafe scenarios are misclassified as safe. In this work, we propose to use input-convex neural networks (ICNNs) for contingency screening. We show that ICNN reliability can be determined by solving a convex optimization problem, and by scaling model weights using this problem as a differentiable optimization layer during training, we can learn an ICNN classifier that is both data-driven and has provably guaranteed reliability. Namely, our method can ensure a zero false negative rate. We empirically validate this methodology in a case study on the IEEE 39-bus test network, observing that it yields substantial (10-20x) speedups while having excellent classification accuracy.
An Efficient Learning-Based Solver for Two-Stage DC Optimal Power Flow with Feasibility Guarantees
Apr 03, 2023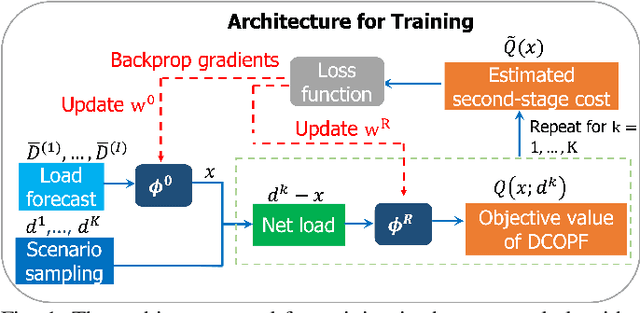
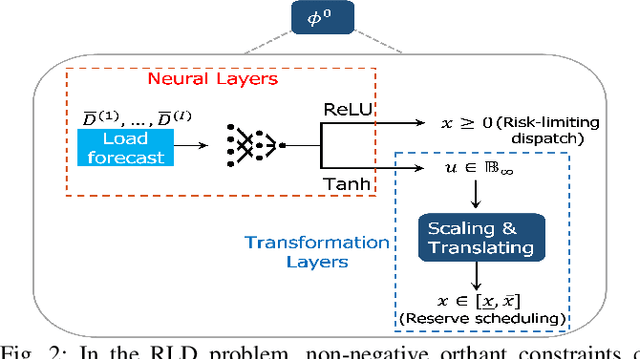
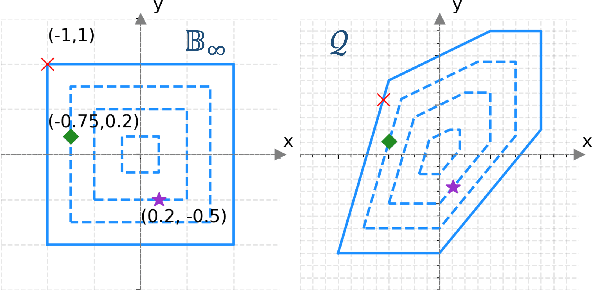
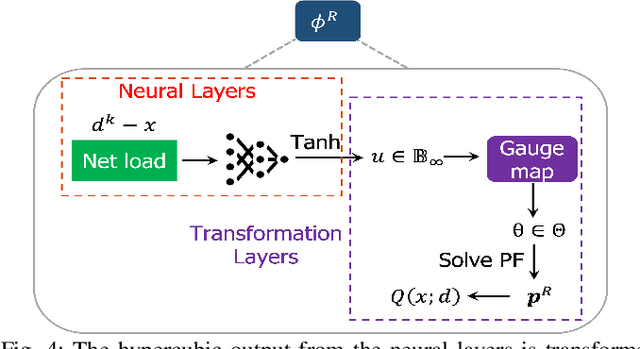
In this paper, we consider the scenario-based two-stage stochastic DC optimal power flow (OPF) problem for optimal and reliable dispatch when the load is facing uncertainty. Although this problem is a linear program, it remains computationally challenging to solve due to the large number of scenarios needed to accurately represent the uncertainties. To mitigate the computational issues, many techniques have been proposed to approximate the second-stage decisions so they can dealt more efficiently. The challenge of finding good policies to approximate the second-stage decisions is that these solutions need to be feasible, which has been difficult to achieve with existing policies. To address these challenges, this paper proposes a learning method to solve the two-stage problem in a more efficient and optimal way. A technique called the gauge map is incorporated into the learning architecture design to guarantee the learned solutions' feasibility to the network constraints. Namely, we can design policies that are feed forward functions that only output feasible solutions. Simulation results on standard IEEE systems show that, compared to iterative solvers and the widely used affine policy, our proposed method not only learns solutions of good quality but also accelerates the computation by orders of magnitude.
Solving Differential-Algebraic Equations in Power Systems Dynamics with Neural Networks and Spatial Decomposition
Mar 17, 2023



The dynamics of the power system are described by a system of differential-algebraic equations. Time-domain simulations are used to understand the evolution of the system dynamics. These simulations can be computationally expensive due to the stiffness of the system which requires the use of finely discretized time-steps. By increasing the allowable time-step size, we aim to accelerate such simulations. In this paper, we use the observation that even though the individual components are described using both algebraic and differential equations, their coupling only involves algebraic equations. Following this observation, we use Neural Networks (NNs) to approximate the components' state evolution, leading to fast, accurate, and numerically stable approximators, which enable larger time-steps. To account for effects of the network on the components and vice-versa, the NNs take the temporal evolution of the coupling algebraic variables as an input for their prediction. We initially estimate this temporal evolution and then update it in an iterative fashion using the Newton-Raphson algorithm. The involved Jacobian matrix is calculated with Automatic Differentiation and its size depends only on the network size but not on the component dynamics. We demonstrate this NN-based simulator on the IEEE 9-bus test case with 3 generators.
Interpreting Primal-Dual Algorithms for Constrained MARL
Dec 01, 2022



Constrained multiagent reinforcement learning (C-MARL) is gaining importance as MARL algorithms find new applications in real-world systems ranging from energy systems to drone swarms. Most C-MARL algorithms use a primal-dual approach to enforce constraints through a penalty function added to the reward. In this paper, we study the structural effects of this penalty term on the MARL problem. First, we show that the standard practice of using the constraint function as the penalty leads to a weak notion of safety. However, by making simple modifications to the penalty term, we can enforce meaningful probabilistic (chance and conditional value at risk) constraints. Second, we quantify the effect of the penalty term on the value function, uncovering an improved value estimation procedure. We use these insights to propose a constrained multiagent advantage actor critic (C-MAA2C) algorithm. Simulations in a simple constrained multiagent environment affirm that our reinterpretation of the primal-dual method in terms of probabilistic constraints is effective, and that our proposed value estimate accelerates convergence to a safe joint policy.
Efficient Reinforcement Learning Through Trajectory Generation
Dec 01, 2022



A key barrier to using reinforcement learning (RL) in many real-world applications is the requirement of a large number of system interactions to learn a good control policy. Off-policy and Offline RL methods have been proposed to reduce the number of interactions with the physical environment by learning control policies from historical data. However, their performances suffer from the lack of exploration and the distributional shifts in trajectories once controllers are updated. Moreover, most RL methods require that all states are directly observed, which is difficult to be attained in many settings. To overcome these challenges, we propose a trajectory generation algorithm, which adaptively generates new trajectories as if the system is being operated and explored under the updated control policies. Motivated by the fundamental lemma for linear systems, assuming sufficient excitation, we generate trajectories from linear combinations of historical trajectories. For linear feedback control, we prove that the algorithm generates trajectories with the exact distribution as if they are sampled from the real system using the updated control policy. In particular, the algorithm extends to systems where the states are not directly observed. Experiments show that the proposed method significantly reduces the number of sampled data needed for RL algorithms.
Learning to Solve the AC Optimal Power Flow via a Lagrangian Approach
Oct 04, 2021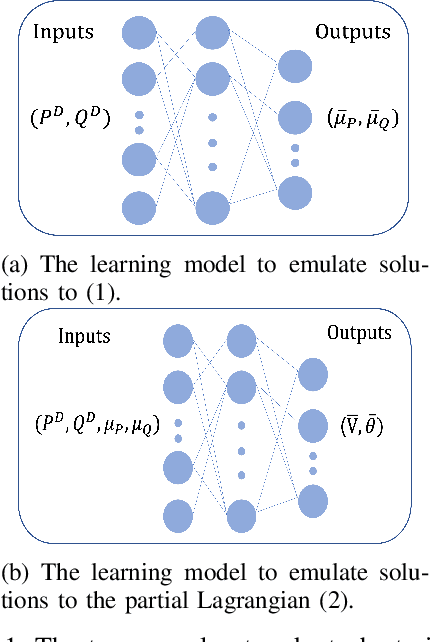
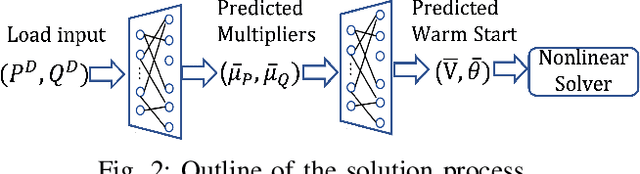
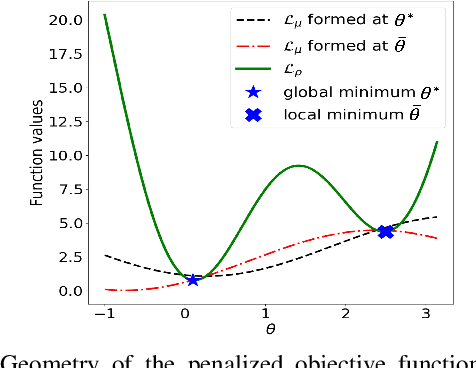
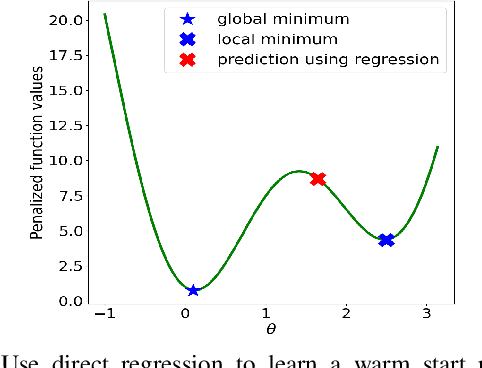
Using deep neural networks to predict the solutions of AC optimal power flow (ACOPF) problems has been an active direction of research. However, because the ACOPF is nonconvex, it is difficult to construct a good data set that contains mostly globally optimal solutions. To overcome the challenge that the training data may contain suboptimal solutions, we propose a Lagrangian-based approach. First, we use a neural network to learn the dual variables of the ACOPF problem. Then we use a second neural network to predict solutions of the partial Lagrangian from the predicted dual variables. Since the partial Lagrangian has a much better optimization landscape, we use the predicted solutions from the neural network as a warm start for the ACOPF problem. Using standard and modified IEEE 22-bus, 39-bus, and 118-bus networks, we show that our approach is able to obtain the globally optimal cost even when the training data is mostly comprised of suboptimal solutions.
Lyapunov-Regularized Reinforcement Learning for Power System Transient Stability
Mar 05, 2021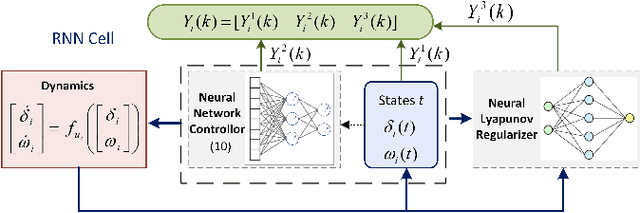

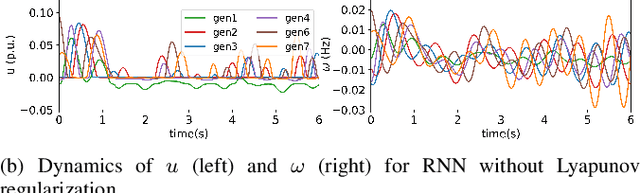
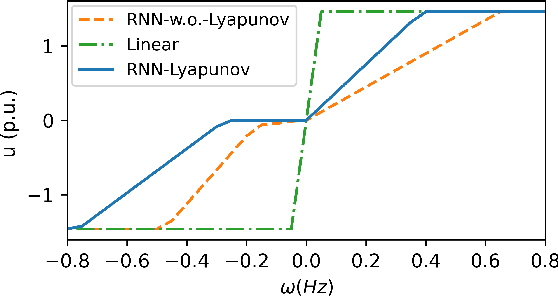
Transient stability of power systems is becoming increasingly important because of the growing integration of renewable resources. These resources lead to a reduction in mechanical inertia but also provide increased flexibility in frequency responses. Namely, their power electronic interfaces can implement almost arbitrary control laws. To design these controllers, reinforcement learning (RL) has emerged as a powerful method in searching for optimal non-linear control policy parameterized by neural networks. A key challenge is to enforce that a learned controller must be stabilizing. This paper proposes a Lyapunov regularized RL approach for optimal frequency control for transient stability in lossy networks. Because the lack of an analytical Lyapunov function, we learn a Lyapunov function parameterized by a neural network. The losses are specially designed with respect to the physical power system. The learned neural Lyapunov function is then utilized as a regularization to train the neural network controller by penalizing actions that violate the Lyapunov conditions. Case study shows that introducing the Lyapunov regularization enables the controller to be stabilizing and achieve smaller losses.
Multi-Agent Reinforcement Learning in Cournot Games
Sep 14, 2020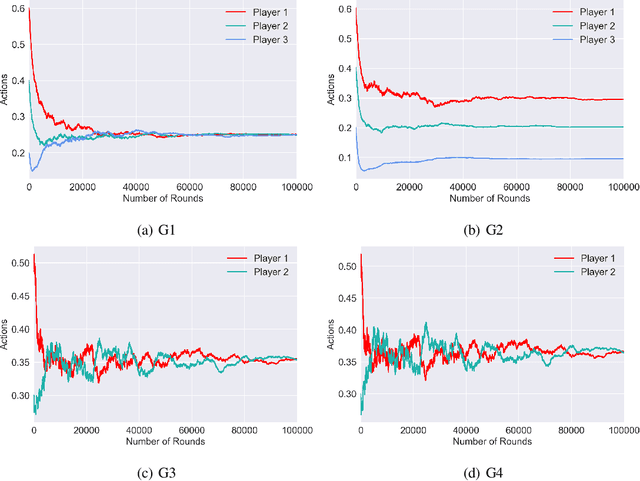
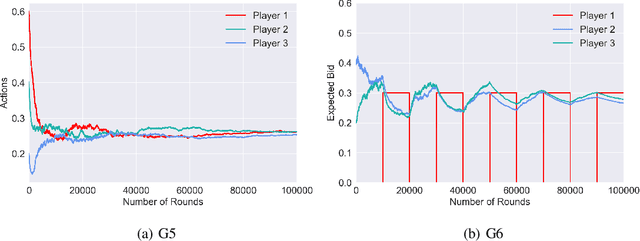
In this work, we study the interaction of strategic agents in continuous action Cournot games with limited information feedback. Cournot game is the essential market model for many socio-economic systems where agents learn and compete without the full knowledge of the system or each other. We consider the dynamics of the policy gradient algorithm, which is a widely adopted continuous control reinforcement learning algorithm, in concave Cournot games. We prove the convergence of policy gradient dynamics to the Nash equilibrium when the price function is linear or the number of agents is two. This is the first result (to the best of our knowledge) on the convergence property of learning algorithms with continuous action spaces that do not fall in the no-regret class.