 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStackelberg Games for Learning Emergent Behaviors During Competitive Autocurricula
May 04, 2023



Autocurricular training is an important sub-area of multi-agent reinforcement learning~(MARL) that allows multiple agents to learn emergent skills in an unsupervised co-evolving scheme. The robotics community has experimented autocurricular training with physically grounded problems, such as robust control and interactive manipulation tasks. However, the asymmetric nature of these tasks makes the generation of sophisticated policies challenging. Indeed, the asymmetry in the environment may implicitly or explicitly provide an advantage to a subset of agents which could, in turn, lead to a low-quality equilibrium. This paper proposes a novel game-theoretic algorithm, Stackelberg Multi-Agent Deep Deterministic Policy Gradient (ST-MADDPG), which formulates a two-player MARL problem as a Stackelberg game with one player as the `leader' and the other as the `follower' in a hierarchical interaction structure wherein the leader has an advantage. We first demonstrate that the leader's advantage from ST-MADDPG can be used to alleviate the inherent asymmetry in the environment. By exploiting the leader's advantage, ST-MADDPG improves the quality of a co-evolution process and results in more sophisticated and complex strategies that work well even against an unseen strong opponent.
Stackelberg Actor-Critic: Game-Theoretic Reinforcement Learning Algorithms
Sep 25, 2021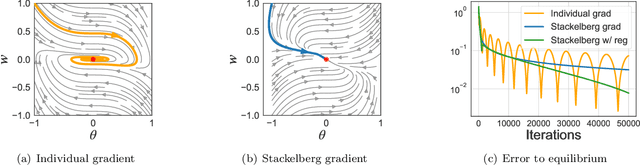
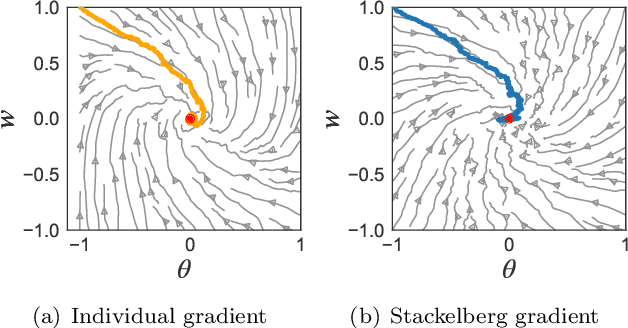
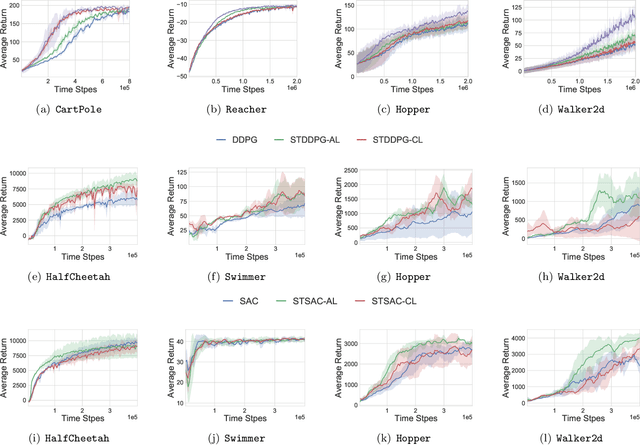
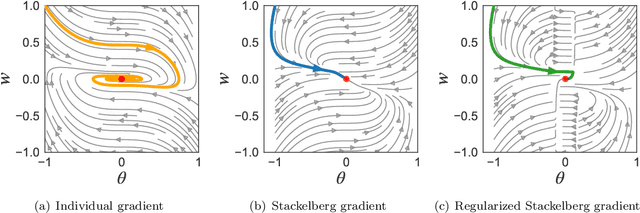
The hierarchical interaction between the actor and critic in actor-critic based reinforcement learning algorithms naturally lends itself to a game-theoretic interpretation. We adopt this viewpoint and model the actor and critic interaction as a two-player general-sum game with a leader-follower structure known as a Stackelberg game. Given this abstraction, we propose a meta-framework for Stackelberg actor-critic algorithms where the leader player follows the total derivative of its objective instead of the usual individual gradient. From a theoretical standpoint, we develop a policy gradient theorem for the refined update and provide a local convergence guarantee for the Stackelberg actor-critic algorithms to a local Stackelberg equilibrium. From an empirical standpoint, we demonstrate via simple examples that the learning dynamics we study mitigate cycling and accelerate convergence compared to the usual gradient dynamics given cost structures induced by actor-critic formulations. Finally, extensive experiments on OpenAI gym environments show that Stackelberg actor-critic algorithms always perform at least as well and often significantly outperform the standard actor-critic algorithm counterparts.
Safe Reinforcement Learning of Control-Affine Systems with Vertex Networks
Mar 20, 2020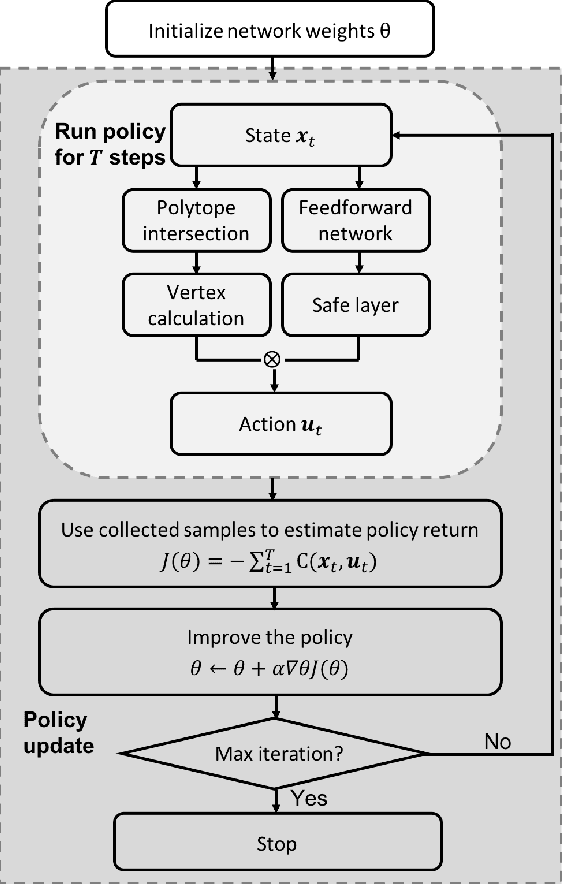
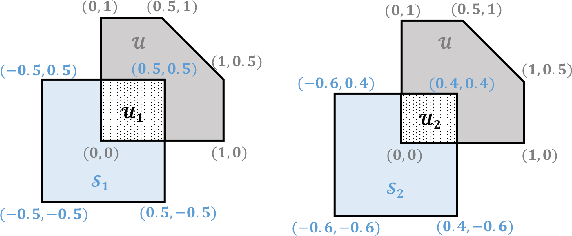
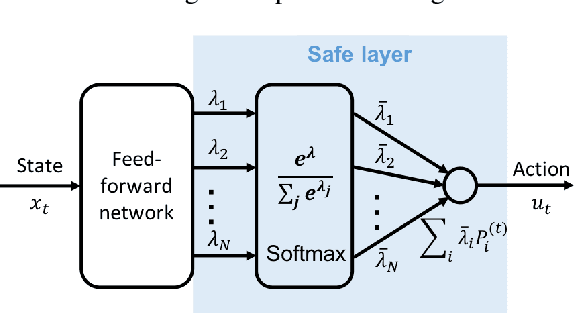
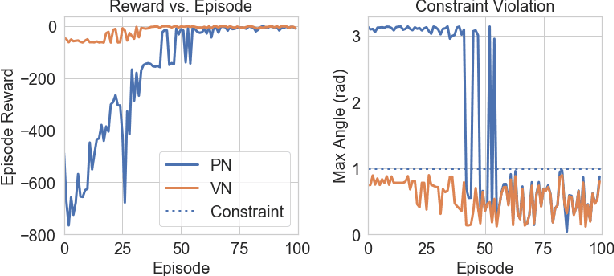
This paper focuses on finding reinforcement learning policies for control systems with hard state and action constraints. Despite its success in many domains, reinforcement learning is challenging to apply to problems with hard constraints, especially if both the state variables and actions are constrained. Previous works seeking to ensure constraint satisfaction, or safety, have focused on adding a projection step to a learned policy. Yet, this approach requires solving an optimization problem at every policy execution step, which can lead to significant computational costs. To tackle this problem, this paper proposes a new approach, termed Vertex Networks (VNs), with guarantees on safety during exploration and on learned control policies by incorporating the safety constraints into the policy network architecture. Leveraging the geometric property that all points within a convex set can be represented as the convex combination of its vertices, the proposed algorithm first learns the convex combination weights and then uses these weights along with the pre-calculated vertices to output an action. The output action is guaranteed to be safe by construction. Numerical examples illustrate that the proposed VN algorithm outperforms vanilla reinforcement learning in a variety of benchmark control tasks.
Constrained Upper Confidence Reinforcement Learning
Jan 26, 2020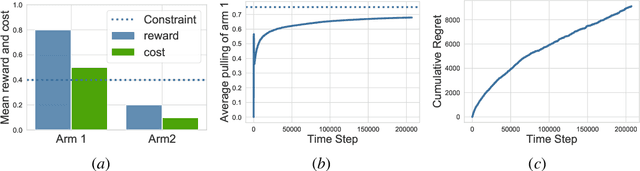
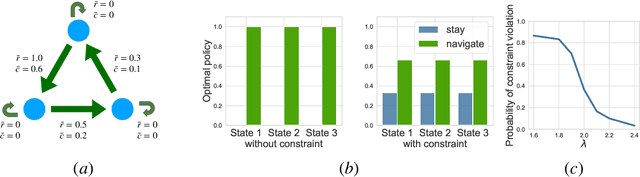
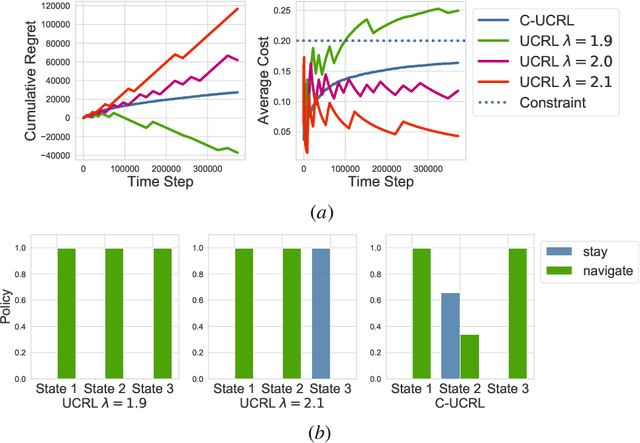
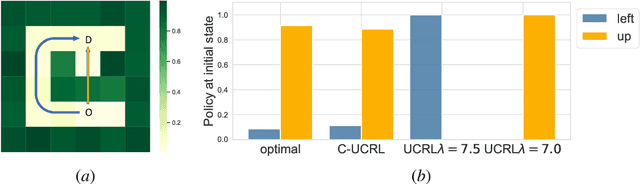
Constrained Markov Decision Processes are a class of stochastic decision problems in which the decision maker must select a policy that satisfies auxiliary cost constraints. This paper extends upper confidence reinforcement learning for settings in which the reward function and the constraints, described by cost functions, are unknown a priori but the transition kernel is known. Such a setting is well-motivated by a number of applications including exploration of unknown, potentially unsafe, environments. We present an algorithm C-UCRL and show that it achieves sub-linear regret ($ O(T^{\frac{3}{4}}\sqrt{\log(T/\delta)})$) with respect to the reward while satisfying the constraints even while learning with probability $1-\delta$. Illustrative examples are provided.
Combinatorial Bandits for Incentivizing Agents with Dynamic Preferences
Jul 06, 2018


The design of personalized incentives or recommendations to improve user engagement is gaining prominence as digital platform providers continually emerge. We propose a multi-armed bandit framework for matching incentives to users, whose preferences are unknown a priori and evolving dynamically in time, in a resource constrained environment. We design an algorithm that combines ideas from three distinct domains: (i) a greedy matching paradigm, (ii) the upper confidence bound algorithm (UCB) for bandits, and (iii) mixing times from the theory of Markov chains. For this algorithm, we provide theoretical bounds on the regret and demonstrate its performance via both synthetic and realistic (matching supply and demand in a bike-sharing platform) examples.
Incentives in the Dark: Multi-armed Bandits for Evolving Users with Unknown Type
Mar 11, 2018
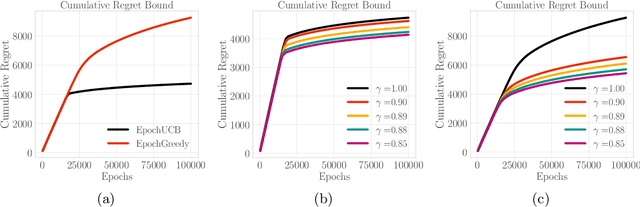
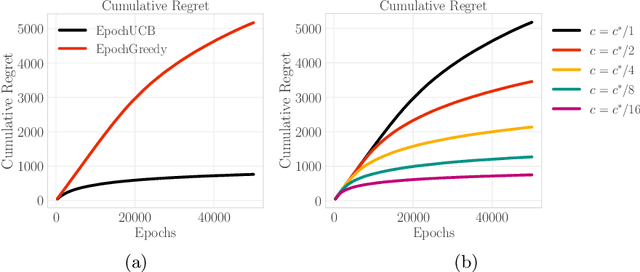
Design of incentives or recommendations to users is becoming more common as platform providers continually emerge. We propose a multi-armed bandit approach to the problem in which users types are unknown a priori and evolve dynamically in time. Unlike the traditional bandit setting, observed rewards are generated by a single Markov process. We demonstrate via an illustrative example that blindly applying the traditional bandit algorithms results in very poor performance as measured by regret. We introduce two variants of classical bandit algorithms, upper confidence bound (UCB) and epsilon-greedy, for which we provide theoretical bounds on the regret. We conduct a number of simulation-based experiments to show how the algorithms perform in comparison to traditional UCB and epsilon-greedy algorithms as well as reinforcement learning (Q-learning).