 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Product Rankings Robust to Fake Users
Sep 10, 2020
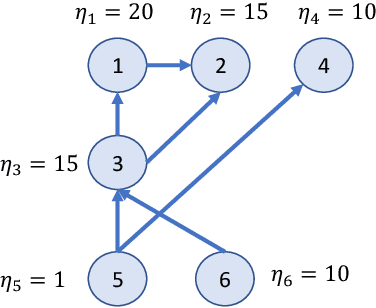
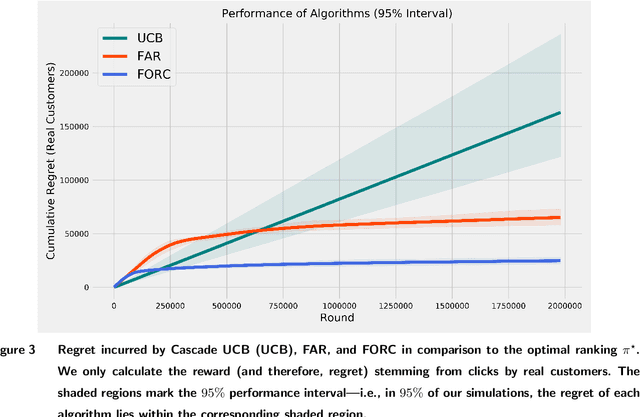
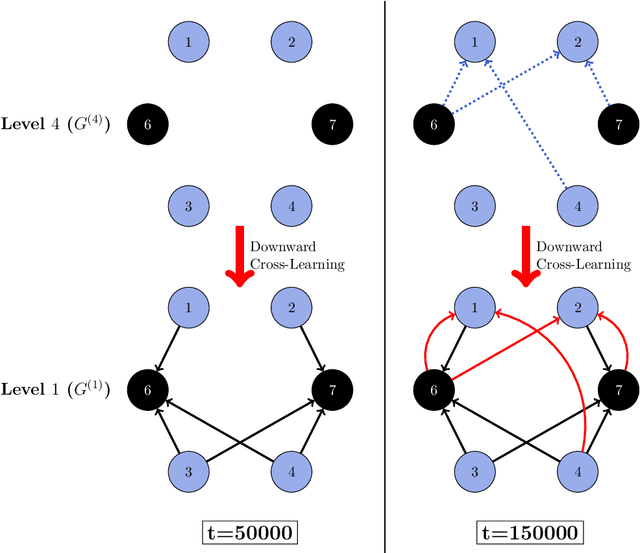
In many online platforms, customers' decisions are substantially influenced by product rankings as most customers only examine a few top-ranked products. Concurrently, such platforms also use the same data corresponding to customers' actions to learn how these products must be ranked or ordered. These interactions in the underlying learning process, however, may incentivize sellers to artificially inflate their position by employing fake users, as exemplified by the emergence of click farms. Motivated by such fraudulent behavior, we study the ranking problem of a platform that faces a mixture of real and fake users who are indistinguishable from one another. We first show that existing learning algorithms---that are optimal in the absence of fake users---may converge to highly sub-optimal rankings under manipulation by fake users. To overcome this deficiency, we develop efficient learning algorithms under two informational environments: in the first setting, the platform is aware of the number of fake users, and in the second setting, it is agnostic to the number of fake users. For both these environments, we prove that our algorithms converge to the optimal ranking, while being robust to the aforementioned fraudulent behavior; we also present worst-case performance guarantees for our methods, and show that they significantly outperform existing algorithms. At a high level, our work employs several novel approaches to guarantee robustness such as: (i) constructing product-ordering graphs that encode the pairwise relationships between products inferred from the customers' actions; and (ii) implementing multiple levels of learning with a judicious amount of bi-directional cross-learning between levels.
Combinatorial Bandits for Incentivizing Agents with Dynamic Preferences
Jul 06, 2018

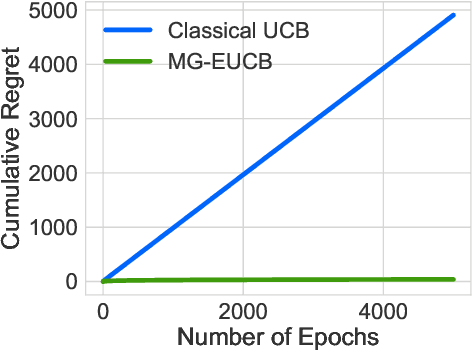

The design of personalized incentives or recommendations to improve user engagement is gaining prominence as digital platform providers continually emerge. We propose a multi-armed bandit framework for matching incentives to users, whose preferences are unknown a priori and evolving dynamically in time, in a resource constrained environment. We design an algorithm that combines ideas from three distinct domains: (i) a greedy matching paradigm, (ii) the upper confidence bound algorithm (UCB) for bandits, and (iii) mixing times from the theory of Markov chains. For this algorithm, we provide theoretical bounds on the regret and demonstrate its performance via both synthetic and realistic (matching supply and demand in a bike-sharing platform) examples.
Incentives in the Dark: Multi-armed Bandits for Evolving Users with Unknown Type
Mar 11, 2018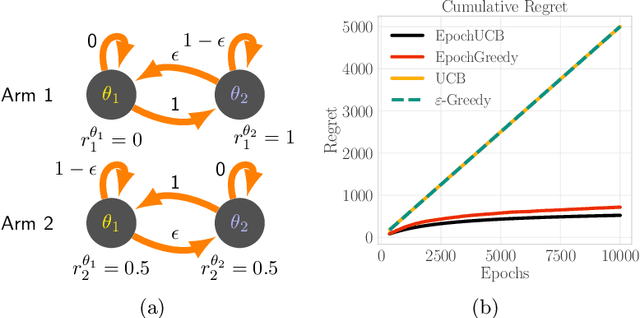
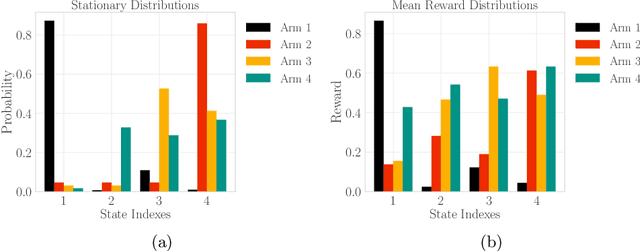
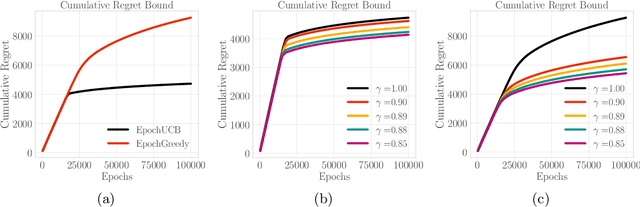
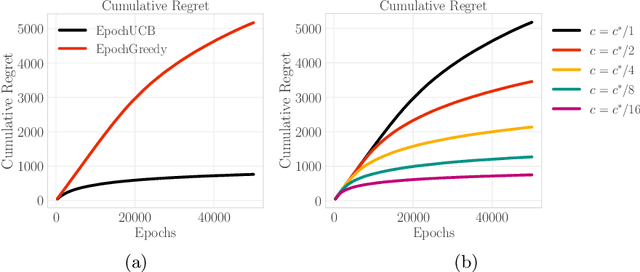
Design of incentives or recommendations to users is becoming more common as platform providers continually emerge. We propose a multi-armed bandit approach to the problem in which users types are unknown a priori and evolve dynamically in time. Unlike the traditional bandit setting, observed rewards are generated by a single Markov process. We demonstrate via an illustrative example that blindly applying the traditional bandit algorithms results in very poor performance as measured by regret. We introduce two variants of classical bandit algorithms, upper confidence bound (UCB) and epsilon-greedy, for which we provide theoretical bounds on the regret. We conduct a number of simulation-based experiments to show how the algorithms perform in comparison to traditional UCB and epsilon-greedy algorithms as well as reinforcement learning (Q-learning).
Truthful Mechanisms for Matching and Clustering in an Ordinal World
Oct 18, 2016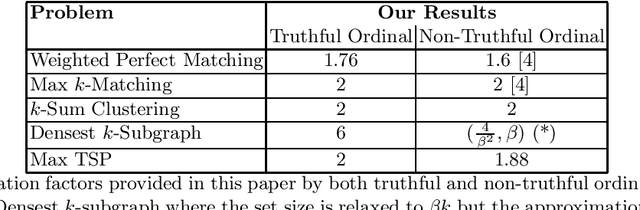
We study truthful mechanisms for matching and related problems in a partial information setting, where the agents' true utilities are hidden, and the algorithm only has access to ordinal preference information. Our model is motivated by the fact that in many settings, agents cannot express the numerical values of their utility for different outcomes, but are still able to rank the outcomes in their order of preference. Specifically, we study problems where the ground truth exists in the form of a weighted graph of agent utilities, but the algorithm can only elicit the agents' private information in the form of a preference ordering for each agent induced by the underlying weights. Against this backdrop, we design truthful algorithms to approximate the true optimum solution with respect to the hidden weights. Our techniques yield universally truthful algorithms for a number of graph problems: a 1.76-approximation algorithm for Max-Weight Matching, 2-approximation algorithm for Max k-matching, a 6-approximation algorithm for Densest k-subgraph, and a 2-approximation algorithm for Max Traveling Salesman as long as the hidden weights constitute a metric. We also provide improved approximation algorithms for such problems when the agents are not able to lie about their preferences. Our results are the first non-trivial truthful approximation algorithms for these problems, and indicate that in many situations, we can design robust algorithms even when the agents may lie and only provide ordinal information instead of precise utilities.
Blind, Greedy, and Random: Ordinal Approximation Algorithms for Matching and Clustering
Aug 01, 2016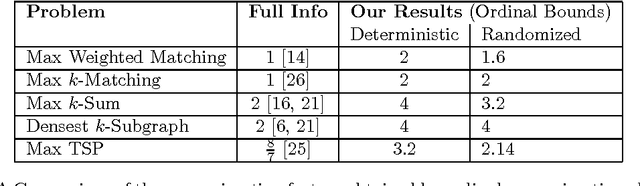
We study Matching and other related problems in a partial information setting where the agents' utilities for being matched to other agents are hidden and the mechanism only has access to ordinal preference information. Our model is motivated by the fact that in many settings, agents cannot express the numerical values of their utility for different outcomes, but are still able to rank the outcomes in their order of preference. Specifically, we study problems where the ground truth exists in the form of a weighted graph, and look to design algorithms that approximate the true optimum matching using only the preference orderings for each agent (induced by the hidden weights) as input. If no restrictions are placed on the weights, then one cannot hope to do better than the simple greedy algorithm, which yields a half optimal matching. Perhaps surprisingly, we show that by imposing a little structure on the weights, we can improve upon the trivial algorithm significantly: we design a 1.6-approximation algorithm for instances where the hidden weights obey the metric inequality. Using our algorithms for matching as a black-box, we also design new approximation algorithms for other closely related problems: these include a a 3.2-approximation for the problem of clustering agents into equal sized partitions, a 4-approximation algorithm for Densest k-subgraph, and a 2.14-approximation algorithm for Max TSP. These results are the first non-trivial ordinal approximation algorithms for such problems, and indicate that we can design robust algorithms even when we are agnostic to the precise agent utilities.
Computing Stable Coalitions: Approximation Algorithms for Reward Sharing
Aug 27, 2015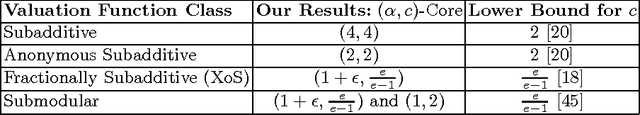

Consider a setting where selfish agents are to be assigned to coalitions or projects from a fixed set P. Each project k is characterized by a valuation function; v_k(S) is the value generated by a set S of agents working on project k. We study the following classic problem in this setting: "how should the agents divide the value that they collectively create?". One traditional approach in cooperative game theory is to study core stability with the implicit assumption that there are infinite copies of one project, and agents can partition themselves into any number of coalitions. In contrast, we consider a model with a finite number of non-identical projects; this makes computing both high-welfare solutions and core payments highly non-trivial. The main contribution of this paper is a black-box mechanism that reduces the problem of computing a near-optimal core stable solution to the purely algorithmic problem of welfare maximization; we apply this to compute an approximately core stable solution that extracts one-fourth of the optimal social welfare for the class of subadditive valuations. We also show much stronger results for several popular sub-classes: anonymous, fractionally subadditive, and submodular valuations, as well as provide new approximation algorithms for welfare maximization with anonymous functions. Finally, we establish a connection between our setting and the well-studied simultaneous auctions with item bidding; we adapt our results to compute approximate pure Nash equilibria for these auctions.