 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompatibility of Max and Sum Objectives for Committee Selection and $k$-Facility Location
Jul 22, 2025We study a version of the metric facility location problem (or, equivalently, variants of the committee selection problem) in which we must choose $k$ facilities in an arbitrary metric space to serve some set of clients $C$. We consider four different objectives, where each client $i\in C$ attempts to minimize either the sum or the maximum of its distance to the chosen facilities, and where the overall objective either considers the sum or the maximum of the individual client costs. Rather than optimizing a single objective at a time, we study how compatible these objectives are with each other, and show the existence of solutions which are simultaneously close-to-optimum for any pair of the above objectives. Our results show that when choosing a set of facilities or a representative committee, it is often possible to form a solution which is good for several objectives at the same time, instead of sacrificing one desideratum to achieve another.
Optimizing Multiple Simultaneous Objectives for Voting and Facility Location
Dec 10, 2022We study the classic facility location setting, where we are given $n$ clients and $m$ possible facility locations in some arbitrary metric space, and want to choose a location to build a facility. The exact same setting also arises in spatial social choice, where voters are the clients and the goal is to choose a candidate or outcome, with the distance from a voter to an outcome representing the cost of this outcome for the voter (e.g., based on their ideological differences). Unlike most previous work, we do not focus on a single objective to optimize (e.g., the total distance from clients to the facility, or the maximum distance, etc.), but instead attempt to optimize several different objectives simultaneously. More specifically, we consider the $l$-centrum family of objectives, which includes the total distance, max distance, and many others. We present tight bounds on how well any pair of such objectives (e.g., max and sum) can be simultaneously approximated compared to their optimum outcomes. In particular, we show that for any such pair of objectives, it is always possible to choose an outcome which simultaneously approximates both objectives within a factor of $1+\sqrt{2}$, and give a precise characterization of how this factor improves as the two objectives being optimized become more similar. For $q>2$ different centrum objectives, we show that it is always possible to approximate all $q$ of these objectives within a small constant, and that this constant approaches 3 as $q\rightarrow \infty$. Our results show that when optimizing only a few simultaneous objectives, it is always possible to form an outcome which is a significantly better than 3 approximation for all of these objectives.
Awareness of Voter Passion Greatly Improves the Distortion of Metric Social Choice
Jun 25, 2019
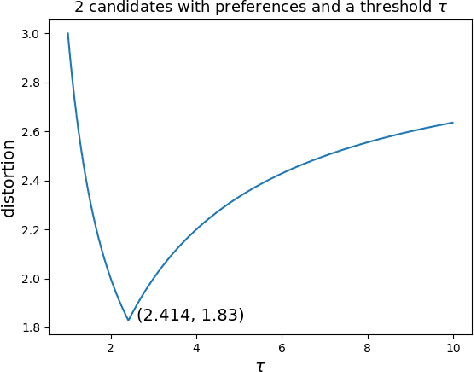
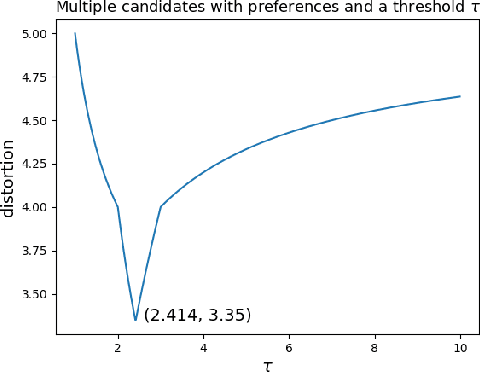

We develop new voting mechanisms for the case when voters and candidates are located in an arbitrary unknown metric space, and the goal is to choose a candidate minimizing social cost: the total distance from the voters to this candidate. Previous work has often assumed that only ordinal preferences of the voters are known (instead of their true costs), and focused on minimizing distortion: the quality of the chosen candidate as compared with the best possible candidate. In this paper, we instead assume that a (very small) amount of information is known about the voter preference strengths, not just about their ordinal preferences. We provide mechanisms with much better distortion when this extra information is known as compared to mechanisms which use only ordinal information. We quantify tradeoffs between the amount of information known about preference strengths and the achievable distortion. We further provide advice about which type of information about preference strengths seems to be the most useful. Finally, we conclude by quantifying the ideal candidate distortion, which compares the quality of the chosen outcome with the best possible candidate that could ever exist, instead of only the best candidate that is actually in the running.
Truthful Mechanisms for Matching and Clustering in an Ordinal World
Oct 18, 2016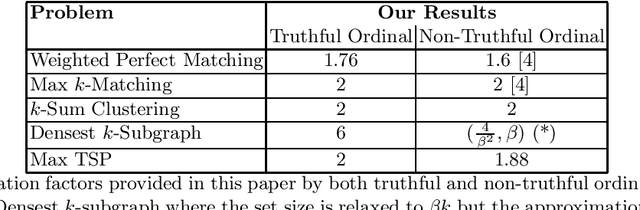
We study truthful mechanisms for matching and related problems in a partial information setting, where the agents' true utilities are hidden, and the algorithm only has access to ordinal preference information. Our model is motivated by the fact that in many settings, agents cannot express the numerical values of their utility for different outcomes, but are still able to rank the outcomes in their order of preference. Specifically, we study problems where the ground truth exists in the form of a weighted graph of agent utilities, but the algorithm can only elicit the agents' private information in the form of a preference ordering for each agent induced by the underlying weights. Against this backdrop, we design truthful algorithms to approximate the true optimum solution with respect to the hidden weights. Our techniques yield universally truthful algorithms for a number of graph problems: a 1.76-approximation algorithm for Max-Weight Matching, 2-approximation algorithm for Max k-matching, a 6-approximation algorithm for Densest k-subgraph, and a 2-approximation algorithm for Max Traveling Salesman as long as the hidden weights constitute a metric. We also provide improved approximation algorithms for such problems when the agents are not able to lie about their preferences. Our results are the first non-trivial truthful approximation algorithms for these problems, and indicate that in many situations, we can design robust algorithms even when the agents may lie and only provide ordinal information instead of precise utilities.
Randomized Social Choice Functions Under Metric Preferences
Sep 26, 2016
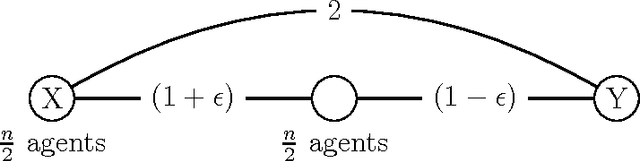
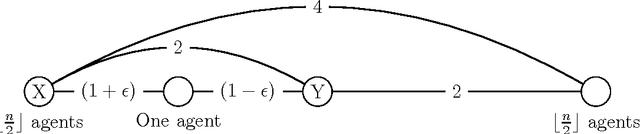
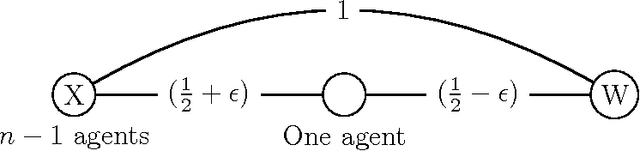
We determine the quality of randomized social choice mechanisms in a setting in which the agents have metric preferences: every agent has a cost for each alternative, and these costs form a metric. We assume that these costs are unknown to the mechanisms (and possibly even to the agents themselves), which means we cannot simply select the optimal alternative, i.e. the alternative that minimizes the total agent cost (or median agent cost). However, we do assume that the agents know their ordinal preferences that are induced by the metric space. We examine randomized social choice functions that require only this ordinal information and select an alternative that is good in expectation with respect to the costs from the metric. To quantify how good a randomized social choice function is, we bound the distortion, which is the worst-case ratio between expected cost of the alternative selected and the cost of the optimal alternative. We provide new distortion bounds for a variety of randomized mechanisms, for both general metrics and for important special cases. Our results show a sizable improvement in distortion over deterministic mechanisms.
Blind, Greedy, and Random: Ordinal Approximation Algorithms for Matching and Clustering
Aug 01, 2016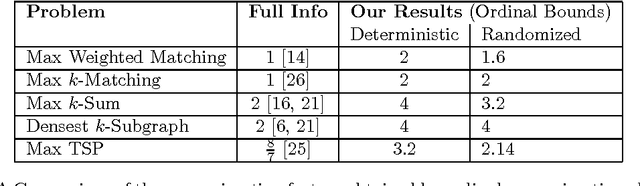
We study Matching and other related problems in a partial information setting where the agents' utilities for being matched to other agents are hidden and the mechanism only has access to ordinal preference information. Our model is motivated by the fact that in many settings, agents cannot express the numerical values of their utility for different outcomes, but are still able to rank the outcomes in their order of preference. Specifically, we study problems where the ground truth exists in the form of a weighted graph, and look to design algorithms that approximate the true optimum matching using only the preference orderings for each agent (induced by the hidden weights) as input. If no restrictions are placed on the weights, then one cannot hope to do better than the simple greedy algorithm, which yields a half optimal matching. Perhaps surprisingly, we show that by imposing a little structure on the weights, we can improve upon the trivial algorithm significantly: we design a 1.6-approximation algorithm for instances where the hidden weights obey the metric inequality. Using our algorithms for matching as a black-box, we also design new approximation algorithms for other closely related problems: these include a a 3.2-approximation for the problem of clustering agents into equal sized partitions, a 4-approximation algorithm for Densest k-subgraph, and a 2.14-approximation algorithm for Max TSP. These results are the first non-trivial ordinal approximation algorithms for such problems, and indicate that we can design robust algorithms even when we are agnostic to the precise agent utilities.
Computing Stable Coalitions: Approximation Algorithms for Reward Sharing
Aug 27, 2015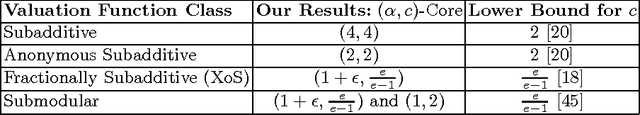

Consider a setting where selfish agents are to be assigned to coalitions or projects from a fixed set P. Each project k is characterized by a valuation function; v_k(S) is the value generated by a set S of agents working on project k. We study the following classic problem in this setting: "how should the agents divide the value that they collectively create?". One traditional approach in cooperative game theory is to study core stability with the implicit assumption that there are infinite copies of one project, and agents can partition themselves into any number of coalitions. In contrast, we consider a model with a finite number of non-identical projects; this makes computing both high-welfare solutions and core payments highly non-trivial. The main contribution of this paper is a black-box mechanism that reduces the problem of computing a near-optimal core stable solution to the purely algorithmic problem of welfare maximization; we apply this to compute an approximately core stable solution that extracts one-fourth of the optimal social welfare for the class of subadditive valuations. We also show much stronger results for several popular sub-classes: anonymous, fractionally subadditive, and submodular valuations, as well as provide new approximation algorithms for welfare maximization with anonymous functions. Finally, we establish a connection between our setting and the well-studied simultaneous auctions with item bidding; we adapt our results to compute approximate pure Nash equilibria for these auctions.