 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwiLTra-Bench: The Swiss Legal Translation Benchmark
Mar 03, 2025In Switzerland legal translation is uniquely important due to the country's four official languages and requirements for multilingual legal documentation. However, this process traditionally relies on professionals who must be both legal experts and skilled translators -- creating bottlenecks and impacting effective access to justice. To address this challenge, we introduce SwiLTra-Bench, a comprehensive multilingual benchmark of over 180K aligned Swiss legal translation pairs comprising laws, headnotes, and press releases across all Swiss languages along with English, designed to evaluate LLM-based translation systems. Our systematic evaluation reveals that frontier models achieve superior translation performance across all document types, while specialized translation systems excel specifically in laws but under-perform in headnotes. Through rigorous testing and human expert validation, we demonstrate that while fine-tuning open SLMs significantly improves their translation quality, they still lag behind the best zero-shot prompted frontier models such as Claude-3.5-Sonnet. Additionally, we present SwiLTra-Judge, a specialized LLM evaluation system that aligns best with human expert assessments.
Privacy Preserving Multi-Agent Reinforcement Learning in Supply Chains
Dec 09, 2023



This paper addresses privacy concerns in multi-agent reinforcement learning (MARL), specifically within the context of supply chains where individual strategic data must remain confidential. Organizations within the supply chain are modeled as agents, each seeking to optimize their own objectives while interacting with others. As each organization's strategy is contingent on neighboring strategies, maintaining privacy of state and action-related information is crucial. To tackle this challenge, we propose a game-theoretic, privacy-preserving mechanism, utilizing a secure multi-party computation (MPC) framework in MARL settings. Our major contribution is the successful implementation of a secure MPC framework, SecFloat on EzPC, to solve this problem. However, simply implementing policy gradient methods such as MADDPG operations using SecFloat, while conceptually feasible, would be programmatically intractable. To overcome this hurdle, we devise a novel approach that breaks down the forward and backward pass of the neural network into elementary operations compatible with SecFloat , creating efficient and secure versions of the MADDPG algorithm. Furthermore, we present a learning mechanism that carries out floating point operations in a privacy-preserving manner, an important feature for successful learning in MARL framework. Experiments reveal that there is on average 68.19% less supply chain wastage in 2 PC compared to no data share, while also giving on average 42.27% better average cumulative revenue for each player. This work paves the way for practical, privacy-preserving MARL, promising significant improvements in secure computation within supply chain contexts and broadly.
Stackelberg Games for Learning Emergent Behaviors During Competitive Autocurricula
May 04, 2023



Autocurricular training is an important sub-area of multi-agent reinforcement learning~(MARL) that allows multiple agents to learn emergent skills in an unsupervised co-evolving scheme. The robotics community has experimented autocurricular training with physically grounded problems, such as robust control and interactive manipulation tasks. However, the asymmetric nature of these tasks makes the generation of sophisticated policies challenging. Indeed, the asymmetry in the environment may implicitly or explicitly provide an advantage to a subset of agents which could, in turn, lead to a low-quality equilibrium. This paper proposes a novel game-theoretic algorithm, Stackelberg Multi-Agent Deep Deterministic Policy Gradient (ST-MADDPG), which formulates a two-player MARL problem as a Stackelberg game with one player as the `leader' and the other as the `follower' in a hierarchical interaction structure wherein the leader has an advantage. We first demonstrate that the leader's advantage from ST-MADDPG can be used to alleviate the inherent asymmetry in the environment. By exploiting the leader's advantage, ST-MADDPG improves the quality of a co-evolution process and results in more sophisticated and complex strategies that work well even against an unseen strong opponent.
Hierarchical Control Strategy for Moving A Robot Manipulator Between Small Containers
Nov 28, 2022

In this paper, we study the implementation of a model predictive controller (MPC) for the task of object manipulation in a highly uncertain environment (e.g., picking objects from a semi-flexible array of densely packed bins). As a real-time perception-driven feedback controller, MPC is robust to the uncertainties in this environment. However, our experiment shows MPC cannot control a robot to complete a sequence of motions in a heavily occluded environment due to its myopic nature. It will benefit from adding a high-level policy that adaptively adjusts the optimization problem for MPC.
Improved Object Pose Estimation via Deep Pre-touch Sensing
Apr 09, 2022

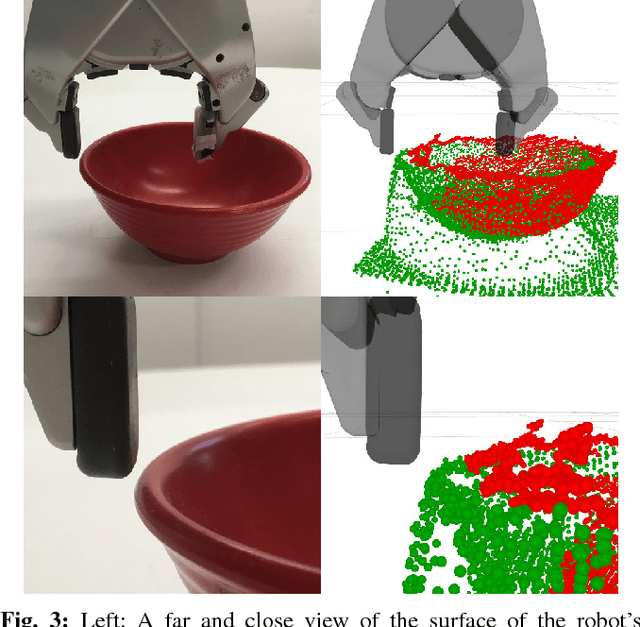

For certain manipulation tasks, object pose estimation from head-mounted cameras may not be sufficiently accurate. This is at least in part due to our inability to perfectly calibrate the coordinate frames of today's high degree of freedom robot arms that link the head to the end-effectors. We present a novel framework combining pre-touch sensing and deep learning to more accurately estimate pose in an efficient manner. The use of pre-touch sensing allows our method to localize the object directly with respect to the robot's end effector, thereby avoiding error caused by miscalibration of the arms. Instead of requiring the robot to scan the entire object with its pre-touch sensor, we use a deep neural network to detect object regions that contain distinctive geometric features. By focusing pre-touch sensing on these regions, the robot can more efficiently gather the information necessary to adjust its original pose estimate. Our region detection network was trained using a new dataset containing objects of widely varying geometries and has been labeled in a scalable fashion that is free from human bias. This dataset is applicable to any task that involves a pre-touch sensor gathering geometric information, and has been made publicly available. We evaluate our framework by having the robot re-estimate the pose of a number of objects of varying geometries. Compared to two simpler region proposal methods, we find that our deep neural network performs significantly better. In addition, we find that after a sequence of scans, objects can typically be localized to within 0.5 cm of their true position. We also observe that the original pose estimate can often be significantly improved after collecting a single quick scan.
Benchmarking Robot Manipulation with the Rubik's Cube
Feb 14, 2022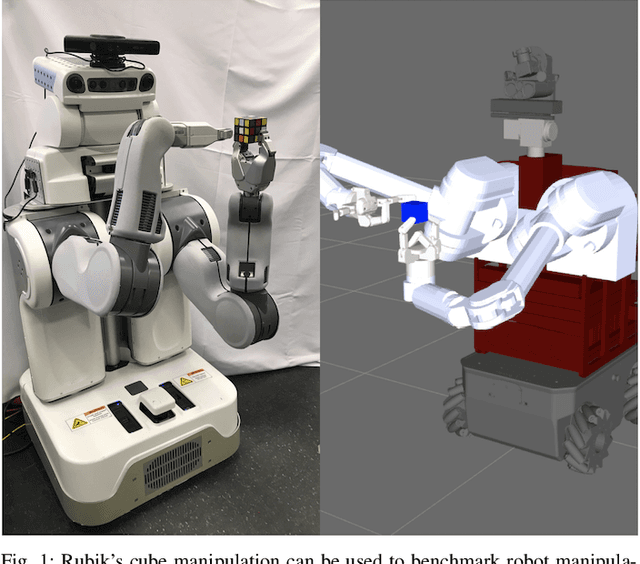
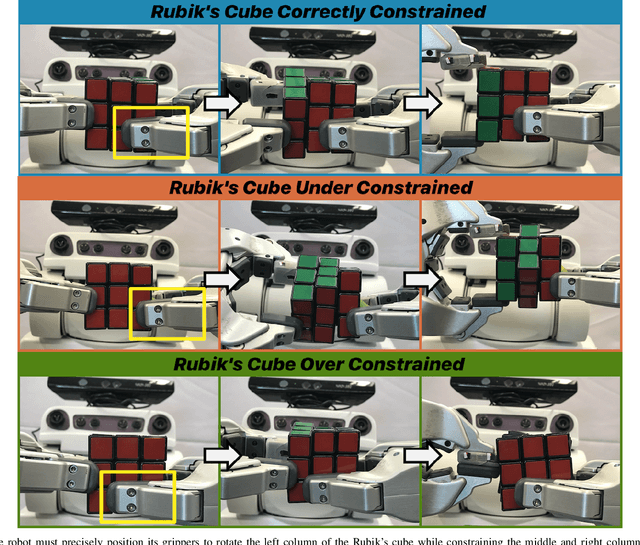
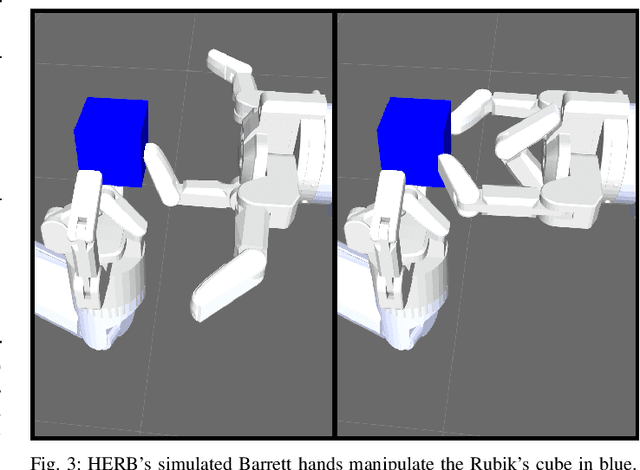
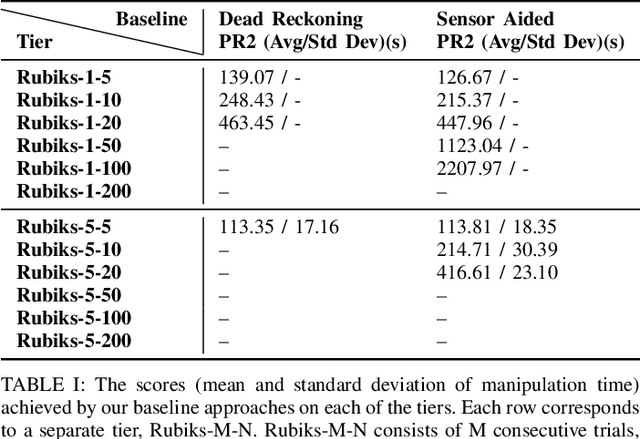
Benchmarks for robot manipulation are crucial to measuring progress in the field, yet there are few benchmarks that demonstrate critical manipulation skills, possess standardized metrics, and can be attempted by a wide array of robot platforms. To address a lack of such benchmarks, we propose Rubik's cube manipulation as a benchmark to measure simultaneous performance of precise manipulation and sequential manipulation. The sub-structure of the Rubik's cube demands precise positioning of the robot's end effectors, while its highly reconfigurable nature enables tasks that require the robot to manage pose uncertainty throughout long sequences of actions. We present a protocol for quantitatively measuring both the accuracy and speed of Rubik's cube manipulation. This protocol can be attempted by any general-purpose manipulator, and only requires a standard 3x3 Rubik's cube and a flat surface upon which the Rubik's cube initially rests (e.g. a table). We demonstrate this protocol for two distinct baseline approaches on a PR2 robot. The first baseline provides a fundamental approach for pose-based Rubik's cube manipulation. The second baseline demonstrates the benchmark's ability to quantify improved performance by the system, particularly that resulting from the integration of pre-touch sensing. To demonstrate the benchmark's applicability to other robot platforms and algorithmic approaches, we present the functional blocks required to enable the HERB robot to manipulate the Rubik's cube via push-grasping.
* IEEE RAL
Motivating Physical Activity via Competitive Human-Robot Interaction
Feb 14, 2022
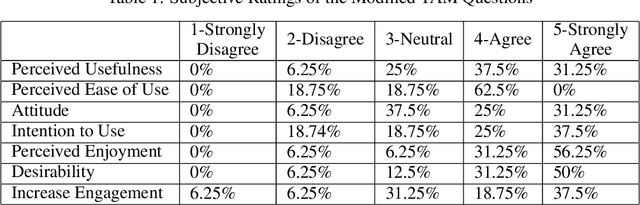
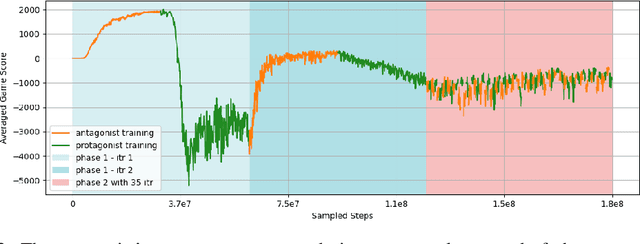
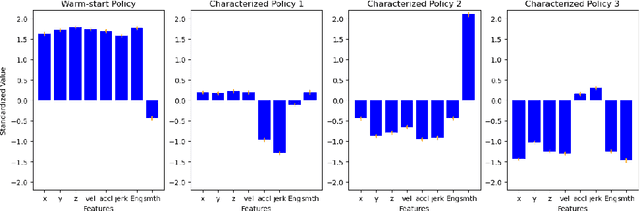
This project aims to motivate research in competitive human-robot interaction by creating a robot competitor that can challenge human users in certain scenarios such as physical exercise and games. With this goal in mind, we introduce the Fencing Game, a human-robot competition used to evaluate both the capabilities of the robot competitor and user experience. We develop the robot competitor through iterative multi-agent reinforcement learning and show that it can perform well against human competitors. Our user study additionally found that our system was able to continuously create challenging and enjoyable interactions that significantly increased human subjects' heart rates. The majority of human subjects considered the system to be entertaining and desirable for improving the quality of their exercise.
Contact-less manipulation of millimeter-scale objects via ultrasonic levitation
Feb 20, 2020


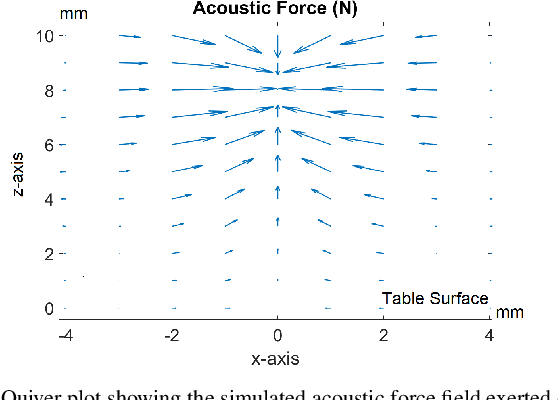
Although general purpose robotic manipulators are becoming more capable at manipulating various objects, their ability to manipulate millimeter-scale objects are usually very limited. On the other hand, ultrasonic levitation devices have been shown to levitate a large range of small objects, from polystyrene balls to living organisms. By controlling the acoustic force fields, ultrasonic levitation devices can compensate for robot manipulator positioning uncertainty and control the grasping force exerted on the target object. The material agnostic nature of acoustic levitation devices and their ability to dexterously manipulate millimeter-scale objects make them appealing as a grasping mode for general purpose robots. In this work, we present an ultrasonic, contact-less manipulation device that can be attached to or picked up by any general purpose robotic arm, enabling millimeter-scale manipulation with little to no modification to the robot itself. This device is capable of performing the very first phase-controlled picking action on acoustically reflective surfaces. With the manipulator placed around the target object, the manipulator can grasp objects smaller in size than the robot's positioning uncertainty, trap the object to resist air currents during robot movement, and dexterously hold a small and fragile object, like a flower bud. Due to the contact-less nature of the ultrasound-based gripper, a camera positioned to look into the cylinder can inspect the object without occlusion, facilitating accurate visual feature extraction.