 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy Preserving Multi-Agent Reinforcement Learning in Supply Chains
Dec 09, 2023



This paper addresses privacy concerns in multi-agent reinforcement learning (MARL), specifically within the context of supply chains where individual strategic data must remain confidential. Organizations within the supply chain are modeled as agents, each seeking to optimize their own objectives while interacting with others. As each organization's strategy is contingent on neighboring strategies, maintaining privacy of state and action-related information is crucial. To tackle this challenge, we propose a game-theoretic, privacy-preserving mechanism, utilizing a secure multi-party computation (MPC) framework in MARL settings. Our major contribution is the successful implementation of a secure MPC framework, SecFloat on EzPC, to solve this problem. However, simply implementing policy gradient methods such as MADDPG operations using SecFloat, while conceptually feasible, would be programmatically intractable. To overcome this hurdle, we devise a novel approach that breaks down the forward and backward pass of the neural network into elementary operations compatible with SecFloat , creating efficient and secure versions of the MADDPG algorithm. Furthermore, we present a learning mechanism that carries out floating point operations in a privacy-preserving manner, an important feature for successful learning in MARL framework. Experiments reveal that there is on average 68.19% less supply chain wastage in 2 PC compared to no data share, while also giving on average 42.27% better average cumulative revenue for each player. This work paves the way for practical, privacy-preserving MARL, promising significant improvements in secure computation within supply chain contexts and broadly.
IITK@LCP at SemEval 2021 Task 1: Classification for Lexical Complexity Regression Task
Apr 02, 2021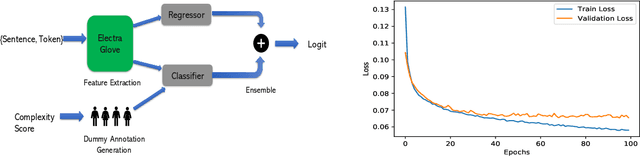
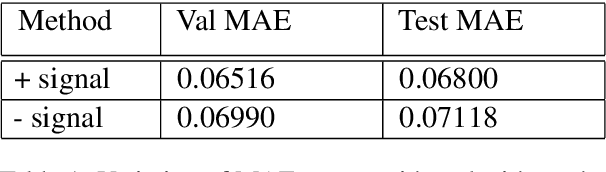
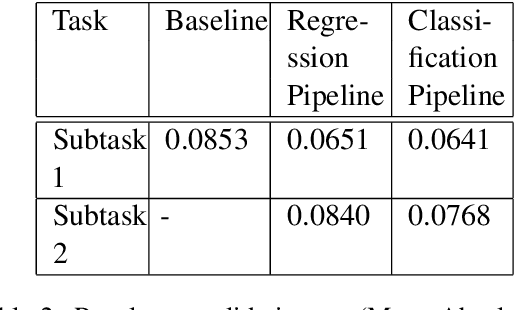
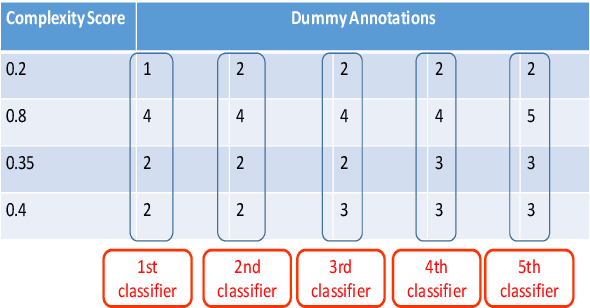
This paper describes our contribution to SemEval 2021 Task 1: Lexical Complexity Prediction. In our approach, we leverage the ELECTRA model and attempt to mirror the data annotation scheme. Although the task is a regression task, we show that we can treat it as an aggregation of several classification and regression models. This somewhat counter-intuitive approach achieved an MAE score of 0.0654 for Sub-Task 1 and MAE of 0.0811 on Sub-Task 2. Additionally, we used the concept of weak supervision signals from Gloss-BERT in our work, and it significantly improved the MAE score in Sub-Task 1.