Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIITK@LCP at SemEval 2021 Task 1: Classification for Lexical Complexity Regression Task
Apr 02, 2021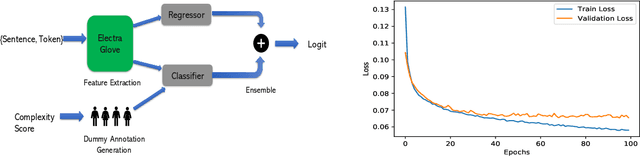
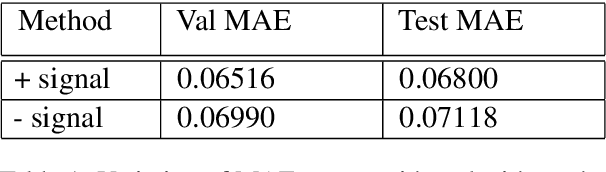
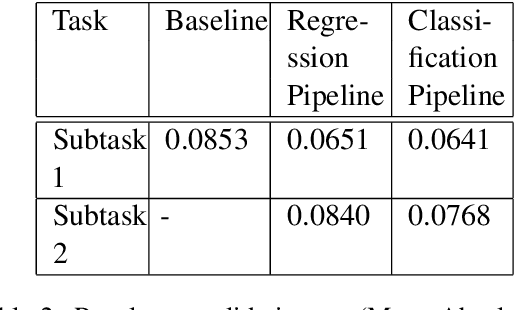
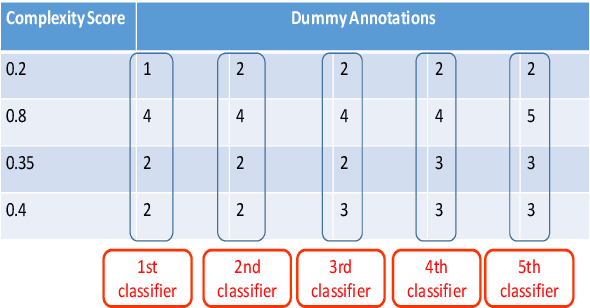
This paper describes our contribution to SemEval 2021 Task 1: Lexical Complexity Prediction. In our approach, we leverage the ELECTRA model and attempt to mirror the data annotation scheme. Although the task is a regression task, we show that we can treat it as an aggregation of several classification and regression models. This somewhat counter-intuitive approach achieved an MAE score of 0.0654 for Sub-Task 1 and MAE of 0.0811 on Sub-Task 2. Additionally, we used the concept of weak supervision signals from Gloss-BERT in our work, and it significantly improved the MAE score in Sub-Task 1.
* Accepted at SemEval 2021 Task 1, 7 Pages (5 Pages main content+ 2
pages for reference)
Via