 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Matching, Less Forgetting: A Quality-Guided Matcher for Transformer-based Incremental Object Detection
Mar 02, 2026Incremental Object Detection (IOD) aims to continuously learn new object classes without forgetting previously learned ones. A persistent challenge is catastrophic forgetting, primarily attributed to background shift in conventional detectors. While pseudo-labeling mitigates this in dense detectors, we identify a novel, distinct source of forgetting specific to DETR-like architectures: background foregrounding. This arises from the exhaustiveness constraint of the Hungarian matcher, which forcibly assigns every ground truth target to one prediction, even when predictions primarily cover background regions (i.e., low IoU). This erroneous supervision compels the model to misclassify background features as specific foreground classes, disrupting learned representations and accelerating forgetting. To address this, we propose a Quality-guided Min-Cost Max-Flow (Q-MCMF) matcher. To avoid forced assignments, Q-MCMF builds a flow graph and prunes implausible matches based on geometric quality. It then optimizes for the final matching that minimizes cost and maximizes valid assignments. This strategy eliminates harmful supervision from background foregrounding while maximizing foreground learning signals. Extensive experiments on the COCO dataset under various incremental settings demonstrate that our method consistently outperforms existing state-of-the-art approaches.
Multi-level Collaborative Distillation Meets Global Workspace Model: A Unified Framework for OCIL
Aug 12, 2025Online Class-Incremental Learning (OCIL) enables models to learn continuously from non-i.i.d. data streams and samples of the data streams can be seen only once, making it more suitable for real-world scenarios compared to offline learning. However, OCIL faces two key challenges: maintaining model stability under strict memory constraints and ensuring adaptability to new tasks. Under stricter memory constraints, current replay-based methods are less effective. While ensemble methods improve adaptability (plasticity), they often struggle with stability. To overcome these challenges, we propose a novel approach that enhances ensemble learning through a Global Workspace Model (GWM)-a shared, implicit memory that guides the learning of multiple student models. The GWM is formed by fusing the parameters of all students within each training batch, capturing the historical learning trajectory and serving as a dynamic anchor for knowledge consolidation. This fused model is then redistributed periodically to the students to stabilize learning and promote cross-task consistency. In addition, we introduce a multi-level collaborative distillation mechanism. This approach enforces peer-to-peer consistency among students and preserves historical knowledge by aligning each student with the GWM. As a result, student models remain adaptable to new tasks while maintaining previously learned knowledge, striking a better balance between stability and plasticity. Extensive experiments on three standard OCIL benchmarks show that our method delivers significant performance improvement for several OCIL models across various memory budgets.
Flow-CDNet: A Novel Network for Detecting Both Slow and Fast Changes in Bitemporal Images
Jul 03, 2025Change detection typically involves identifying regions with changes between bitemporal images taken at the same location. Besides significant changes, slow changes in bitemporal images are also important in real-life scenarios. For instance, weak changes often serve as precursors to major hazards in scenarios like slopes, dams, and tailings ponds. Therefore, designing a change detection network that simultaneously detects slow and fast changes presents a novel challenge. In this paper, to address this challenge, we propose a change detection network named Flow-CDNet, consisting of two branches: optical flow branch and binary change detection branch. The first branch utilizes a pyramid structure to extract displacement changes at multiple scales. The second one combines a ResNet-based network with the optical flow branch's output to generate fast change outputs. Subsequently, to supervise and evaluate this new change detection framework, a self-built change detection dataset Flow-Change, a loss function combining binary tversky loss and L2 norm loss, along with a new evaluation metric called FEPE are designed. Quantitative experiments conducted on Flow-Change dataset demonstrated that our approach outperforms the existing methods. Furthermore, ablation experiments verified that the two branches can promote each other to enhance the detection performance.
Adaptive Spatial Augmentation for Semi-supervised Semantic Segmentation
May 29, 2025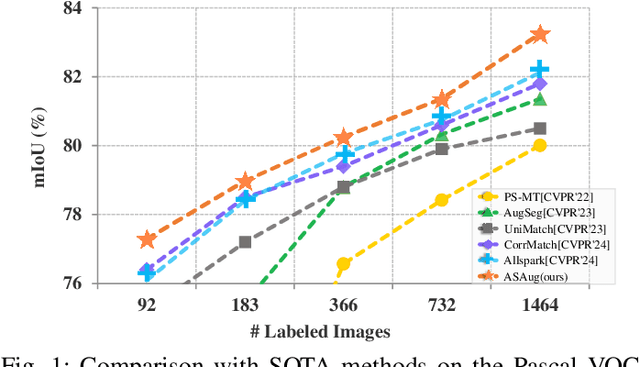
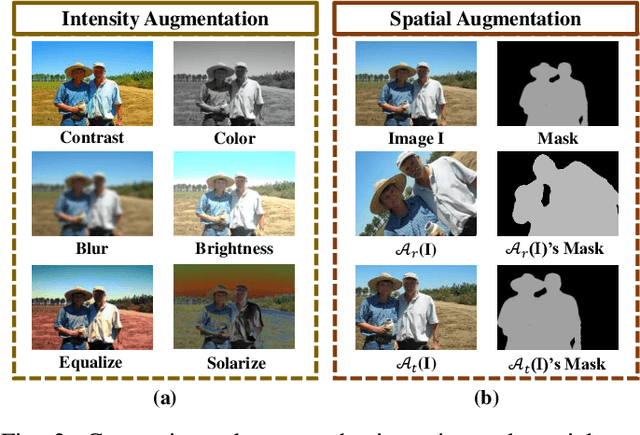
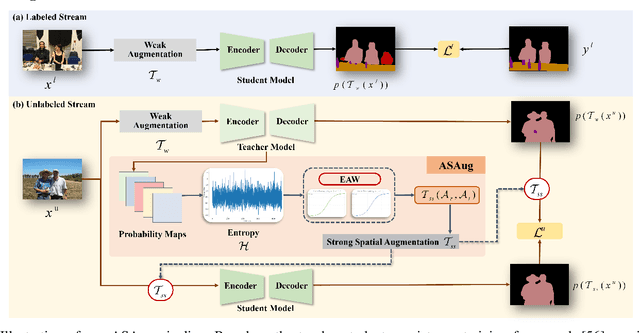
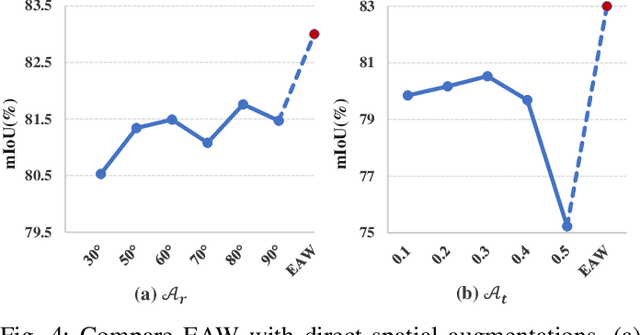
In semi-supervised semantic segmentation (SSSS), data augmentation plays a crucial role in the weak-to-strong consistency regularization framework, as it enhances diversity and improves model generalization. Recent strong augmentation methods have primarily focused on intensity-based perturbations, which have minimal impact on the semantic masks. In contrast, spatial augmentations like translation and rotation have long been acknowledged for their effectiveness in supervised semantic segmentation tasks, but they are often ignored in SSSS. In this work, we demonstrate that spatial augmentation can also contribute to model training in SSSS, despite generating inconsistent masks between the weak and strong augmentations. Furthermore, recognizing the variability among images, we propose an adaptive augmentation strategy that dynamically adjusts the augmentation for each instance based on entropy. Extensive experiments show that our proposed Adaptive Spatial Augmentation (\textbf{ASAug}) can be integrated as a pluggable module, consistently improving the performance of existing methods and achieving state-of-the-art results on benchmark datasets such as PASCAL VOC 2012, Cityscapes, and COCO.
DiffV2IR: Visible-to-Infrared Diffusion Model via Vision-Language Understanding
Mar 24, 2025

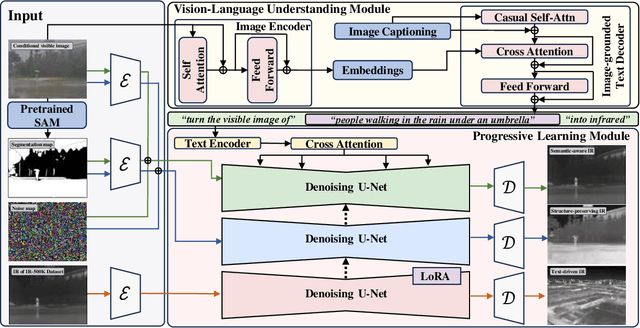
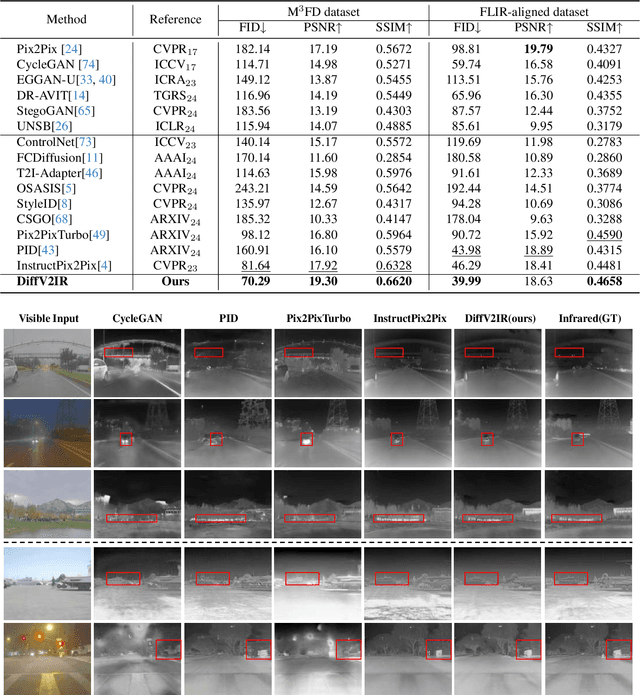
The task of translating visible-to-infrared images (V2IR) is inherently challenging due to three main obstacles: 1) achieving semantic-aware translation, 2) managing the diverse wavelength spectrum in infrared imagery, and 3) the scarcity of comprehensive infrared datasets. Current leading methods tend to treat V2IR as a conventional image-to-image synthesis challenge, often overlooking these specific issues. To address this, we introduce DiffV2IR, a novel framework for image translation comprising two key elements: a Progressive Learning Module (PLM) and a Vision-Language Understanding Module (VLUM). PLM features an adaptive diffusion model architecture that leverages multi-stage knowledge learning to infrared transition from full-range to target wavelength. To improve V2IR translation, VLUM incorporates unified Vision-Language Understanding. We also collected a large infrared dataset, IR-500K, which includes 500,000 infrared images compiled by various scenes and objects under various environmental conditions. Through the combination of PLM, VLUM, and the extensive IR-500K dataset, DiffV2IR markedly improves the performance of V2IR. Experiments validate DiffV2IR's excellence in producing high-quality translations, establishing its efficacy and broad applicability. The code, dataset, and DiffV2IR model will be available at https://github.com/LidongWang-26/DiffV2IR.
Cross-Platform Video Person ReID: A New Benchmark Dataset and Adaptation Approach
Aug 14, 2024



In this paper, we construct a large-scale benchmark dataset for Ground-to-Aerial Video-based person Re-Identification, named G2A-VReID, which comprises 185,907 images and 5,576 tracklets, featuring 2,788 distinct identities. To our knowledge, this is the first dataset for video ReID under Ground-to-Aerial scenarios. G2A-VReID dataset has the following characteristics: 1) Drastic view changes; 2) Large number of annotated identities; 3) Rich outdoor scenarios; 4) Huge difference in resolution. Additionally, we propose a new benchmark approach for cross-platform ReID by transforming the cross-platform visual alignment problem into visual-semantic alignment through vision-language model (i.e., CLIP) and applying a parameter-efficient Video Set-Level-Adapter module to adapt image-based foundation model to video ReID tasks, termed VSLA-CLIP. Besides, to further reduce the great discrepancy across the platforms, we also devise the platform-bridge prompts for efficient visual feature alignment. Extensive experiments demonstrate the superiority of the proposed method on all existing video ReID datasets and our proposed G2A-VReID dataset.
DDF: A Novel Dual-Domain Image Fusion Strategy for Remote Sensing Image Semantic Segmentation with Unsupervised Domain Adaptation
Mar 05, 2024



Semantic segmentation of remote sensing images is a challenging and hot issue due to the large amount of unlabeled data. Unsupervised domain adaptation (UDA) has proven to be advantageous in incorporating unclassified information from the target domain. However, independently fine-tuning UDA models on the source and target domains has a limited effect on the outcome. This paper proposes a hybrid training strategy as well as a novel dual-domain image fusion strategy that effectively utilizes the original image, transformation image, and intermediate domain information. Moreover, to enhance the precision of pseudo-labels, we present a pseudo-label region-specific weight strategy. The efficacy of our approach is substantiated by extensive benchmark experiments and ablation studies conducted on the ISPRS Vaihingen and Potsdam datasets.
Semi-Supervised Semantic Segmentation Based on Pseudo-Labels: A Survey
Mar 04, 2024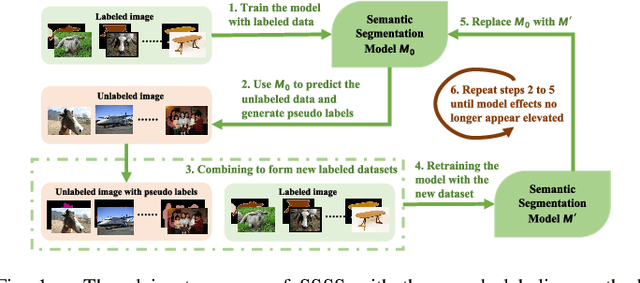
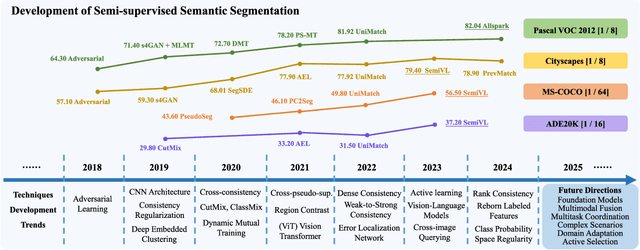
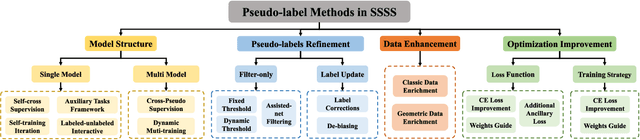
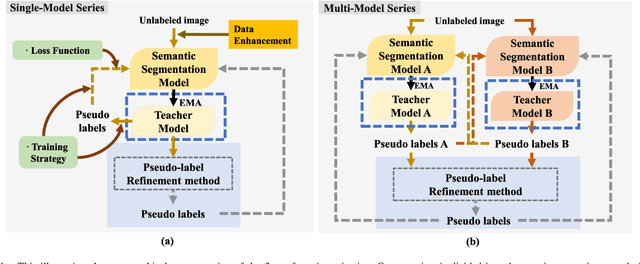
Semantic segmentation is an important and popular research area in computer vision that focuses on classifying pixels in an image based on their semantics. However, supervised deep learning requires large amounts of data to train models and the process of labeling images pixel by pixel is time-consuming and laborious. This review aims to provide a first comprehensive and organized overview of the state-of-the-art research results on pseudo-label methods in the field of semi-supervised semantic segmentation, which we categorize from different perspectives and present specific methods for specific application areas. In addition, we explore the application of pseudo-label technology in medical and remote-sensing image segmentation. Finally, we also propose some feasible future research directions to address the existing challenges.
Zero-Shot Object Goal Visual Navigation With Class-Independent Relationship Network
Oct 15, 2023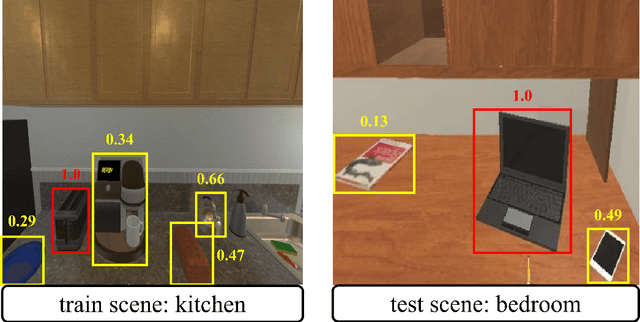
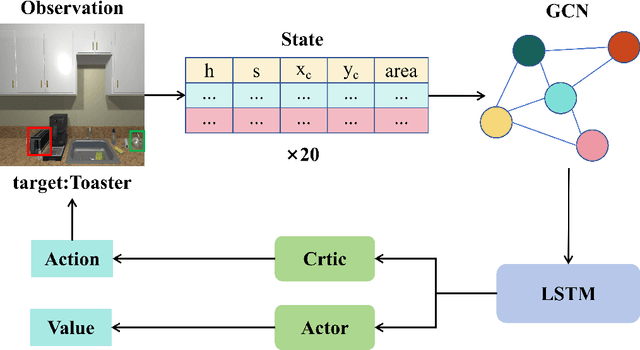
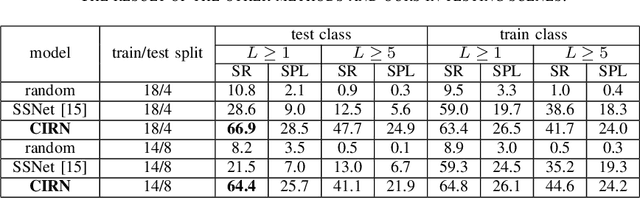

This paper investigates the zero-shot object goal visual navigation problem. In the object goal visual navigation task, the agent needs to locate navigation targets from its egocentric visual input. "Zero-shot" means that the target the agent needs to find is not trained during the training phase. To address the issue of coupling navigation ability with target features during training, we propose the Class-Independent Relationship Network (CIRN). This method combines target detection information with the relative semantic similarity between the target and the navigation target, and constructs a brand new state representation based on similarity ranking, this state representation does not include target feature or environment feature, effectively decoupling the agent's navigation ability from target features. And a Graph Convolutional Network (GCN) is employed to learn the relationships between different objects based on their similarities. During testing, our approach demonstrates strong generalization capabilities, including zero-shot navigation tasks with different targets and environments. Through extensive experiments in the AI2-THOR virtual environment, our method outperforms the current state-of-the-art approaches in the zero-shot object goal visual navigation task. Furthermore, we conducted experiments in more challenging cross-target and cross-scene settings, which further validate the robustness and generalization ability of our method. Our code is available at: https://github.com/SmartAndCleverRobot/ICRA-CIRN.
Pre-train, Adapt and Detect: Multi-Task Adapter Tuning for Camouflaged Object Detection
Jul 20, 2023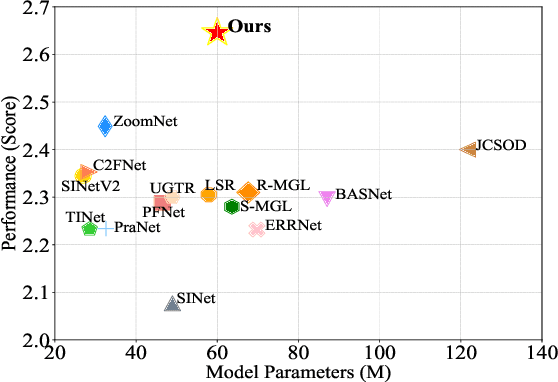
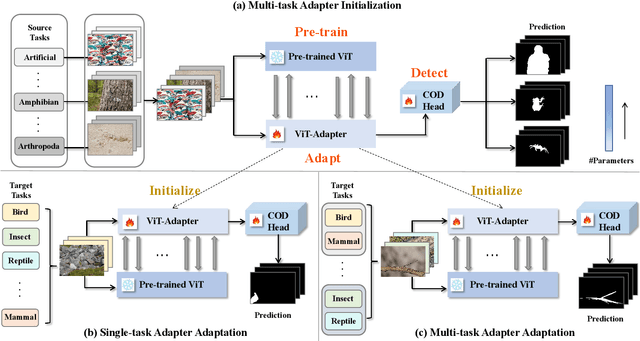

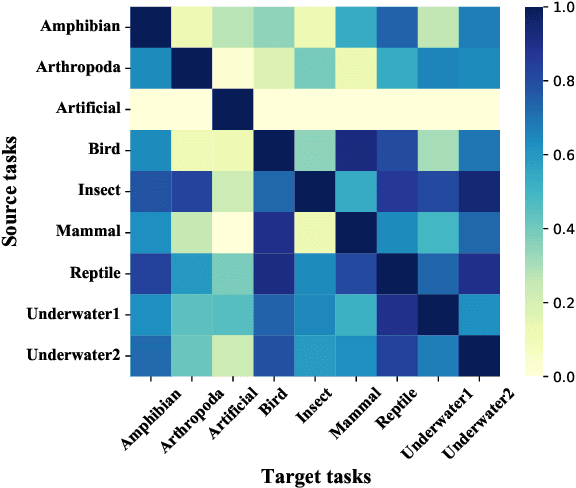
Camouflaged object detection (COD), aiming to segment camouflaged objects which exhibit similar patterns with the background, is a challenging task. Most existing works are dedicated to establishing specialized modules to identify camouflaged objects with complete and fine details, while the boundary can not be well located for the lack of object-related semantics. In this paper, we propose a novel ``pre-train, adapt and detect" paradigm to detect camouflaged objects. By introducing a large pre-trained model, abundant knowledge learned from massive multi-modal data can be directly transferred to COD. A lightweight parallel adapter is inserted to adjust the features suitable for the downstream COD task. Extensive experiments on four challenging benchmark datasets demonstrate that our method outperforms existing state-of-the-art COD models by large margins. Moreover, we design a multi-task learning scheme for tuning the adapter to exploit the shareable knowledge across different semantic classes. Comprehensive experimental results showed that the generalization ability of our model can be substantially improved with multi-task adapter initialization on source tasks and multi-task adaptation on target tasks.