 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Matching, Less Forgetting: A Quality-Guided Matcher for Transformer-based Incremental Object Detection
Mar 02, 2026Incremental Object Detection (IOD) aims to continuously learn new object classes without forgetting previously learned ones. A persistent challenge is catastrophic forgetting, primarily attributed to background shift in conventional detectors. While pseudo-labeling mitigates this in dense detectors, we identify a novel, distinct source of forgetting specific to DETR-like architectures: background foregrounding. This arises from the exhaustiveness constraint of the Hungarian matcher, which forcibly assigns every ground truth target to one prediction, even when predictions primarily cover background regions (i.e., low IoU). This erroneous supervision compels the model to misclassify background features as specific foreground classes, disrupting learned representations and accelerating forgetting. To address this, we propose a Quality-guided Min-Cost Max-Flow (Q-MCMF) matcher. To avoid forced assignments, Q-MCMF builds a flow graph and prunes implausible matches based on geometric quality. It then optimizes for the final matching that minimizes cost and maximizes valid assignments. This strategy eliminates harmful supervision from background foregrounding while maximizing foreground learning signals. Extensive experiments on the COCO dataset under various incremental settings demonstrate that our method consistently outperforms existing state-of-the-art approaches.
Knowing the Unknown: Interpretable Open-World Object Detection via Concept Decomposition Model
Feb 24, 2026Open-world object detection (OWOD) requires incrementally detecting known categories while reliably identifying unknown objects. Existing methods primarily focus on improving unknown recall, yet overlook interpretability, often leading to known-unknown confusion and reduced prediction reliability. This paper aims to make the entire OWOD framework interpretable, enabling the detector to truly "knowing the unknown". To this end, we propose a concept-driven InterPretable OWOD framework(IPOW) by introducing a Concept Decomposition Model (CDM) for OWOD, which explicitly decomposes the coupled RoI features in Faster R-CNN into discriminative, shared, and background concepts. Discriminative concepts identify the most discriminative features to enlarge the distances between known categories, while shared and background concepts, due to their strong generalization ability, can be readily transferred to detect unknown categories. Leveraging the interpretable framework, we identify that known-unknown confusion arises when unknown objects fall into the discriminative space of known classes. To address this, we propose Concept-Guided Rectification (CGR) to further resolve such confusion. Extensive experiments show that IPOW significantly improves unknown recall while mitigating confusion, and provides concept-level interpretability for both known and unknown predictions.
Attention Retention for Continual Learning with Vision Transformers
Feb 05, 2026Continual learning (CL) empowers AI systems to progressively acquire knowledge from non-stationary data streams. However, catastrophic forgetting remains a critical challenge. In this work, we identify attention drift in Vision Transformers as a primary source of catastrophic forgetting, where the attention to previously learned visual concepts shifts significantly after learning new tasks. Inspired by neuroscientific insights into the selective attention in the human visual system, we propose a novel attention-retaining framework to mitigate forgetting in CL. Our method constrains attention drift by explicitly modifying gradients during backpropagation through a two-step process: 1) extracting attention maps of the previous task using a layer-wise rollout mechanism and generating instance-adaptive binary masks, and 2) when learning a new task, applying these masks to zero out gradients associated with previous attention regions, thereby preventing disruption of learned visual concepts. For compatibility with modern optimizers, the gradient masking process is further enhanced by scaling parameter updates proportionally to maintain their relative magnitudes. Experiments and visualizations demonstrate the effectiveness of our method in mitigating catastrophic forgetting and preserving visual concepts. It achieves state-of-the-art performance and exhibits robust generalizability across diverse CL scenarios.
YOLO-IOD: Towards Real Time Incremental Object Detection
Dec 28, 2025Current methods for incremental object detection (IOD) primarily rely on Faster R-CNN or DETR series detectors; however, these approaches do not accommodate the real-time YOLO detection frameworks. In this paper, we first identify three primary types of knowledge conflicts that contribute to catastrophic forgetting in YOLO-based incremental detectors: foreground-background confusion, parameter interference, and misaligned knowledge distillation. Subsequently, we introduce YOLO-IOD, a real-time Incremental Object Detection (IOD) framework that is constructed upon the pretrained YOLO-World model, facilitating incremental learning via a stage-wise parameter-efficient fine-tuning process. Specifically, YOLO-IOD encompasses three principal components: 1) Conflict-Aware Pseudo-Label Refinement (CPR), which mitigates the foreground-background confusion by leveraging the confidence levels of pseudo labels and identifying potential objects relevant to future tasks. 2) Importancebased Kernel Selection (IKS), which identifies and updates the pivotal convolution kernels pertinent to the current task during the current learning stage. 3) Cross-Stage Asymmetric Knowledge Distillation (CAKD), which addresses the misaligned knowledge distillation conflict by transmitting the features of the student target detector through the detection heads of both the previous and current teacher detectors, thereby facilitating asymmetric distillation between existing and newly introduced categories. We further introduce LoCo COCO, a more realistic benchmark that eliminates data leakage across stages. Experiments on both conventional and LoCo COCO benchmarks show that YOLO-IOD achieves superior performance with minimal forgetting.
On Modality Incomplete Infrared-Visible Object Detection: An Architecture Compatibility Perspective
Nov 09, 2025Infrared and visible object detection (IVOD) is essential for numerous around-the-clock applications. Despite notable advancements, current IVOD models exhibit notable performance declines when confronted with incomplete modality data, particularly if the dominant modality is missing. In this paper, we take a thorough investigation on modality incomplete IVOD problem from an architecture compatibility perspective. Specifically, we propose a plug-and-play Scarf Neck module for DETR variants, which introduces a modality-agnostic deformable attention mechanism to enable the IVOD detector to flexibly adapt to any single or double modalities during training and inference. When training Scarf-DETR, we design a pseudo modality dropout strategy to fully utilize the multi-modality information, making the detector compatible and robust to both working modes of single and double modalities. Moreover, we introduce a comprehensive benchmark for the modality-incomplete IVOD task aimed at thoroughly assessing situations where the absent modality is either dominant or secondary. Our proposed Scarf-DETR not only performs excellently in missing modality scenarios but also achieves superior performances on the standard IVOD modality complete benchmarks. Our code will be available at https://github.com/YinghuiXing/Scarf-DETR.
Demystifying Catastrophic Forgetting in Two-Stage Incremental Object Detector
Feb 08, 2025Catastrophic forgetting is a critical chanllenge for incremental object detection (IOD). Most existing methods treat the detector monolithically, relying on instance replay or knowledge distillation without analyzing component-specific forgetting. Through dissection of Faster R-CNN, we reveal a key insight: Catastrophic forgetting is predominantly localized to the RoI Head classifier, while regressors retain robustness across incremental stages. This finding challenges conventional assumptions, motivating us to develop a framework termed NSGP-RePRE. Regional Prototype Replay (RePRE) mitigates classifier forgetting via replay of two types of prototypes: coarse prototypes represent class-wise semantic centers of RoI features, while fine-grained prototypes model intra-class variations. Null Space Gradient Projection (NSGP) is further introduced to eliminate prototype-feature misalignment by updating the feature extractor in directions orthogonal to subspace of old inputs via gradient projection, aligning RePRE with incremental learning dynamics. Our simple yet effective design allows NSGP-RePRE to achieve state-of-the-art performance on the Pascal VOC and MS COCO datasets under various settings. Our work not only advances IOD methodology but also provide pivotal insights for catastrophic forgetting mitigation in IOD. Code will be available soon.
Cross-Platform Video Person ReID: A New Benchmark Dataset and Adaptation Approach
Aug 14, 2024



In this paper, we construct a large-scale benchmark dataset for Ground-to-Aerial Video-based person Re-Identification, named G2A-VReID, which comprises 185,907 images and 5,576 tracklets, featuring 2,788 distinct identities. To our knowledge, this is the first dataset for video ReID under Ground-to-Aerial scenarios. G2A-VReID dataset has the following characteristics: 1) Drastic view changes; 2) Large number of annotated identities; 3) Rich outdoor scenarios; 4) Huge difference in resolution. Additionally, we propose a new benchmark approach for cross-platform ReID by transforming the cross-platform visual alignment problem into visual-semantic alignment through vision-language model (i.e., CLIP) and applying a parameter-efficient Video Set-Level-Adapter module to adapt image-based foundation model to video ReID tasks, termed VSLA-CLIP. Besides, to further reduce the great discrepancy across the platforms, we also devise the platform-bridge prompts for efficient visual feature alignment. Extensive experiments demonstrate the superiority of the proposed method on all existing video ReID datasets and our proposed G2A-VReID dataset.
Visual Prompt Tuning in Null Space for Continual Learning
Jun 11, 2024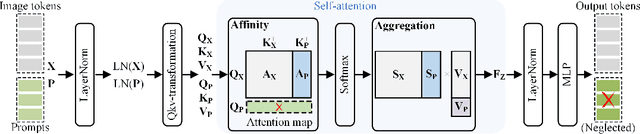
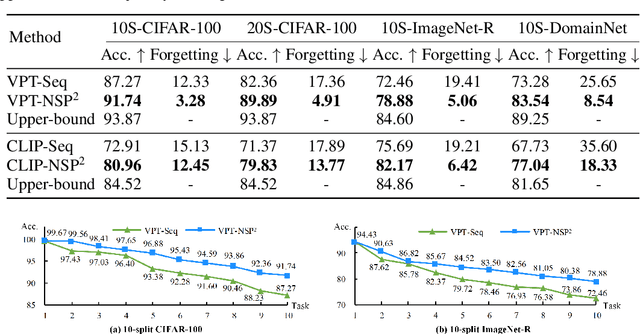
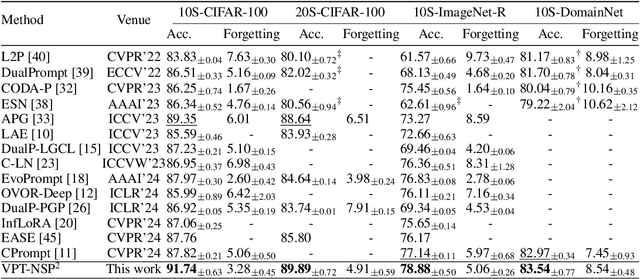
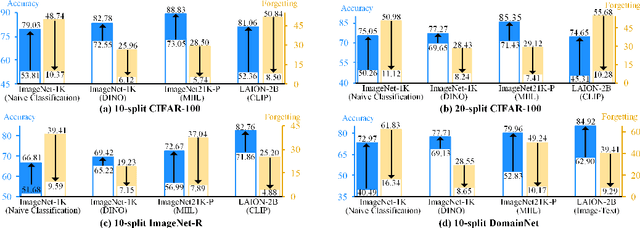
Existing prompt-tuning methods have demonstrated impressive performances in continual learning (CL), by selecting and updating relevant prompts in the vision-transformer models. On the contrary, this paper aims to learn each task by tuning the prompts in the direction orthogonal to the subspace spanned by previous tasks' features, so as to ensure no interference on tasks that have been learned to overcome catastrophic forgetting in CL. However, different from the orthogonal projection in the traditional CNN architecture, the prompt gradient orthogonal projection in the ViT architecture shows completely different and greater challenges, i.e., 1) the high-order and non-linear self-attention operation; 2) the drift of prompt distribution brought by the LayerNorm in the transformer block. Theoretically, we have finally deduced two consistency conditions to achieve the prompt gradient orthogonal projection, which provide a theoretical guarantee of eliminating interference on previously learned knowledge via the self-attention mechanism in visual prompt tuning. In practice, an effective null-space-based approximation solution has been proposed to implement the prompt gradient orthogonal projection. Extensive experimental results demonstrate the effectiveness of anti-forgetting on four class-incremental benchmarks with diverse pre-trained baseline models, and our approach achieves superior performances to state-of-the-art methods. Our code is available at https://github.com/zugexiaodui/VPTinNSforCL.
DDF: A Novel Dual-Domain Image Fusion Strategy for Remote Sensing Image Semantic Segmentation with Unsupervised Domain Adaptation
Mar 05, 2024



Semantic segmentation of remote sensing images is a challenging and hot issue due to the large amount of unlabeled data. Unsupervised domain adaptation (UDA) has proven to be advantageous in incorporating unclassified information from the target domain. However, independently fine-tuning UDA models on the source and target domains has a limited effect on the outcome. This paper proposes a hybrid training strategy as well as a novel dual-domain image fusion strategy that effectively utilizes the original image, transformation image, and intermediate domain information. Moreover, to enhance the precision of pseudo-labels, we present a pseudo-label region-specific weight strategy. The efficacy of our approach is substantiated by extensive benchmark experiments and ablation studies conducted on the ISPRS Vaihingen and Potsdam datasets.
CrossDiff: Exploring Self-Supervised Representation of Pansharpening via Cross-Predictive Diffusion Model
Jan 13, 2024



Fusion of a panchromatic (PAN) image and corresponding multispectral (MS) image is also known as pansharpening, which aims to combine abundant spatial details of PAN and spectral information of MS. Due to the absence of high-resolution MS images, available deep-learning-based methods usually follow the paradigm of training at reduced resolution and testing at both reduced and full resolution. When taking original MS and PAN images as inputs, they always obtain sub-optimal results due to the scale variation. In this paper, we propose to explore the self-supervised representation of pansharpening by designing a cross-predictive diffusion model, named CrossDiff. It has two-stage training. In the first stage, we introduce a cross-predictive pretext task to pre-train the UNet structure based on conditional DDPM, while in the second stage, the encoders of the UNets are frozen to directly extract spatial and spectral features from PAN and MS, and only the fusion head is trained to adapt for pansharpening task. Extensive experiments show the effectiveness and superiority of the proposed model compared with state-of-the-art supervised and unsupervised methods. Besides, the cross-sensor experiments also verify the generalization ability of proposed self-supervised representation learners for other satellite's datasets. We will release our code for reproducibility.