 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Prompt Tuning in Null Space for Continual Learning
Paper and Code
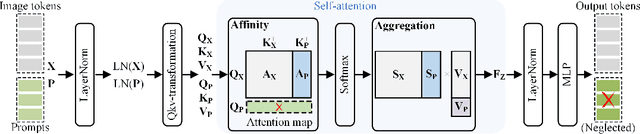
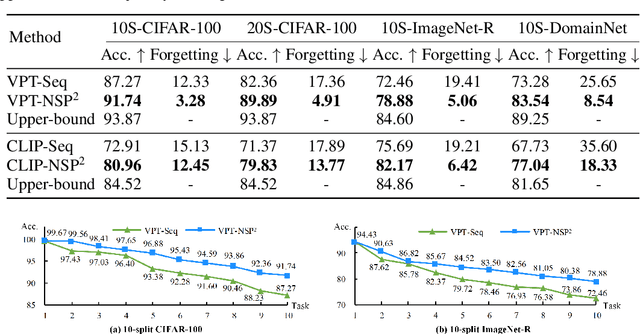
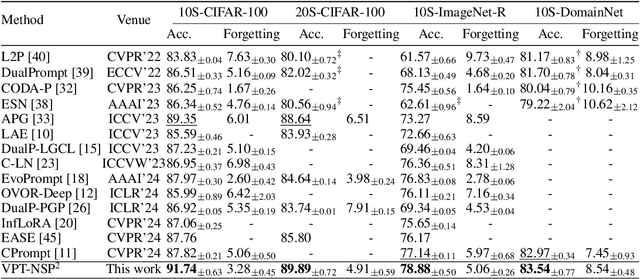
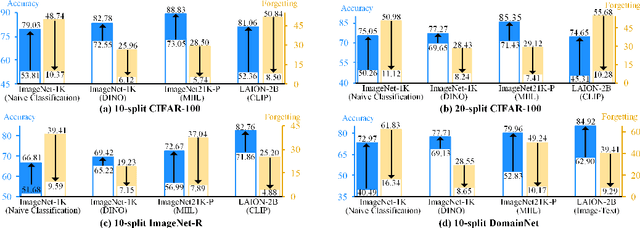
Existing prompt-tuning methods have demonstrated impressive performances in continual learning (CL), by selecting and updating relevant prompts in the vision-transformer models. On the contrary, this paper aims to learn each task by tuning the prompts in the direction orthogonal to the subspace spanned by previous tasks' features, so as to ensure no interference on tasks that have been learned to overcome catastrophic forgetting in CL. However, different from the orthogonal projection in the traditional CNN architecture, the prompt gradient orthogonal projection in the ViT architecture shows completely different and greater challenges, i.e., 1) the high-order and non-linear self-attention operation; 2) the drift of prompt distribution brought by the LayerNorm in the transformer block. Theoretically, we have finally deduced two consistency conditions to achieve the prompt gradient orthogonal projection, which provide a theoretical guarantee of eliminating interference on previously learned knowledge via the self-attention mechanism in visual prompt tuning. In practice, an effective null-space-based approximation solution has been proposed to implement the prompt gradient orthogonal projection. Extensive experimental results demonstrate the effectiveness of anti-forgetting on four class-incremental benchmarks with diverse pre-trained baseline models, and our approach achieves superior performances to state-of-the-art methods. Our code is available at https://github.com/zugexiaodui/VPTinNSforCL.