 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Object Goal Visual Navigation With Class-Independent Relationship Network
Oct 15, 2023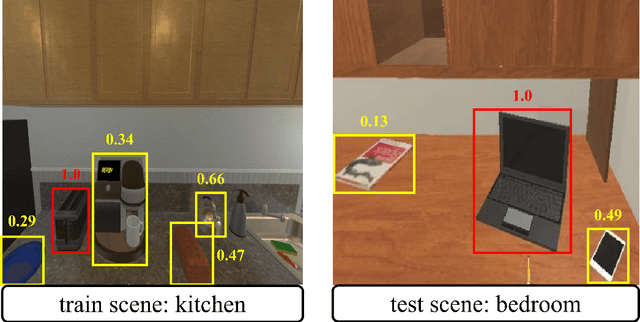
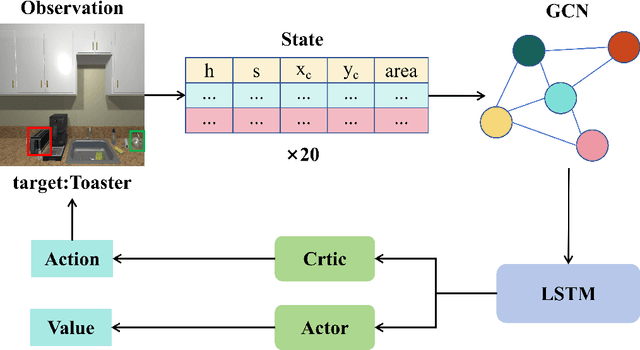
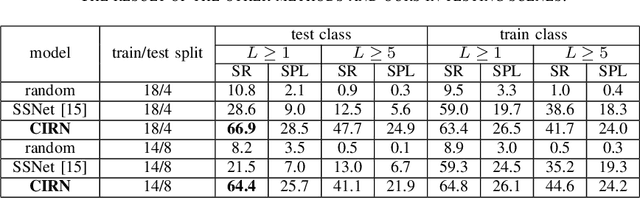

This paper investigates the zero-shot object goal visual navigation problem. In the object goal visual navigation task, the agent needs to locate navigation targets from its egocentric visual input. "Zero-shot" means that the target the agent needs to find is not trained during the training phase. To address the issue of coupling navigation ability with target features during training, we propose the Class-Independent Relationship Network (CIRN). This method combines target detection information with the relative semantic similarity between the target and the navigation target, and constructs a brand new state representation based on similarity ranking, this state representation does not include target feature or environment feature, effectively decoupling the agent's navigation ability from target features. And a Graph Convolutional Network (GCN) is employed to learn the relationships between different objects based on their similarities. During testing, our approach demonstrates strong generalization capabilities, including zero-shot navigation tasks with different targets and environments. Through extensive experiments in the AI2-THOR virtual environment, our method outperforms the current state-of-the-art approaches in the zero-shot object goal visual navigation task. Furthermore, we conducted experiments in more challenging cross-target and cross-scene settings, which further validate the robustness and generalization ability of our method. Our code is available at: https://github.com/SmartAndCleverRobot/ICRA-CIRN.