 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Self-Supervised Pretraining Improves Self-Supervised Pretraining
Mar 25, 2021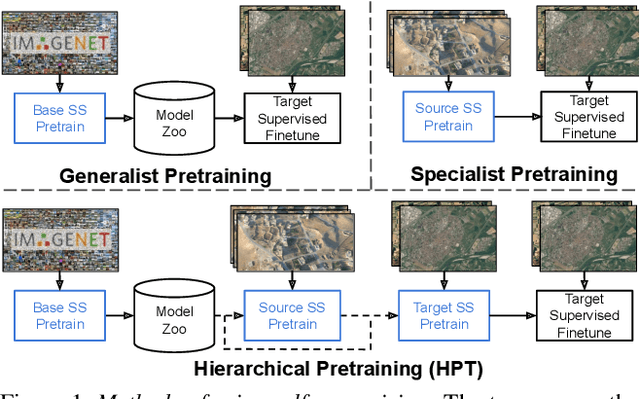
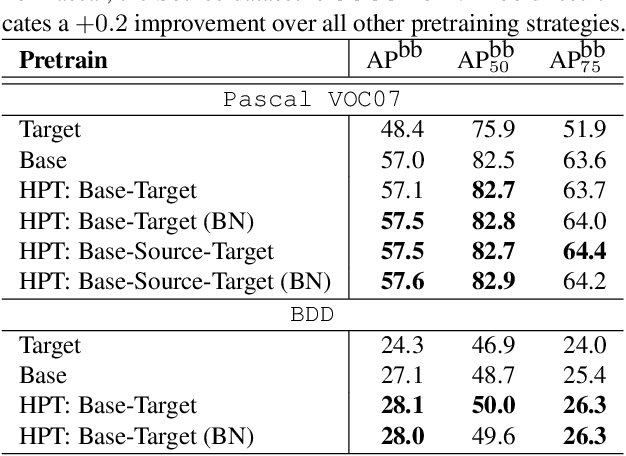
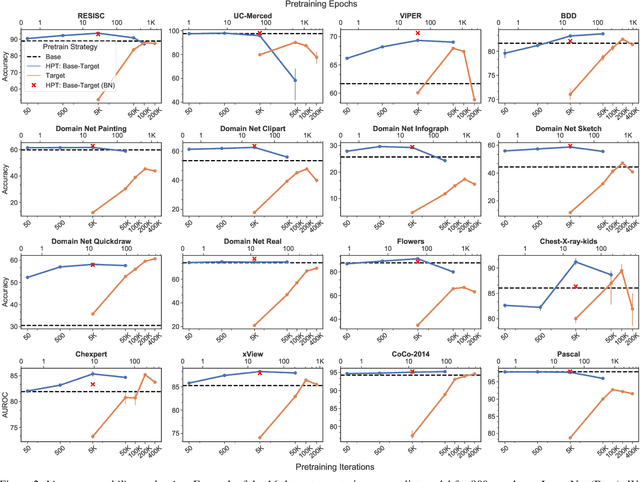
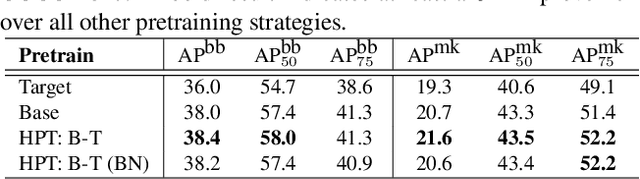
While self-supervised pretraining has proven beneficial for many computer vision tasks, it requires expensive and lengthy computation, large amounts of data, and is sensitive to data augmentation. Prior work demonstrates that models pretrained on datasets dissimilar to their target data, such as chest X-ray models trained on ImageNet, underperform models trained from scratch. Users that lack the resources to pretrain must use existing models with lower performance. This paper explores Hierarchical PreTraining (HPT), which decreases convergence time and improves accuracy by initializing the pretraining process with an existing pretrained model. Through experimentation on 16 diverse vision datasets, we show HPT converges up to 80x faster, improves accuracy across tasks, and improves the robustness of the self-supervised pretraining process to changes in the image augmentation policy or amount of pretraining data. Taken together, HPT provides a simple framework for obtaining better pretrained representations with less computational resources.
Evaluating Self-Supervised Pretraining Without Using Labels
Sep 16, 2020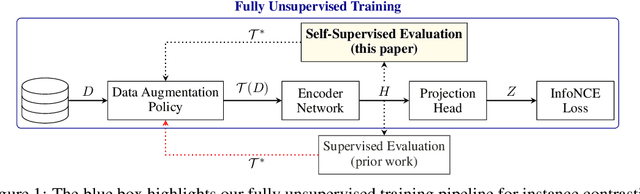
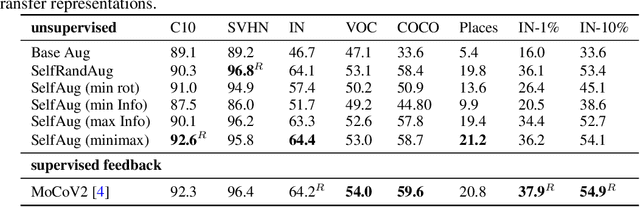
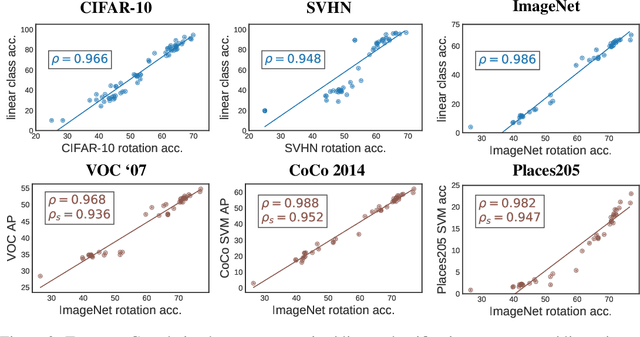
A common practice in unsupervised representation learning is to use labeled data to evaluate the learned representations - oftentimes using the labels from the "unlabeled" training dataset. This supervised evaluation is then used to guide the training process, e.g. to select augmentation policies. However, supervised evaluations may not be possible when labeled data is difficult to obtain (such as medical imaging) or ambiguous to label (such as fashion categorization). This raises the question: is it possible to evaluate unsupervised models without using labeled data? Furthermore, is it possible to use this evaluation to make decisions about the training process, such as which augmentation policies to use? In this work, we show that the simple self-supervised evaluation task of image rotation prediction is highly correlated with the supervised performance of standard visual recognition tasks and datasets (rank correlation > 0.94). We establish this correlation across hundreds of augmentation policies and training schedules and show how this evaluation criteria can be used to automatically select augmentation policies without using labels. Despite not using any labeled data, these policies perform comparably with policies that were determined using supervised downstream tasks. Importantly, this work explores the idea of using unsupervised evaluation criteria to help both researchers and practitioners make decisions when training without labeled data.