 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Super Weight in Large Language Models
Paper and Code

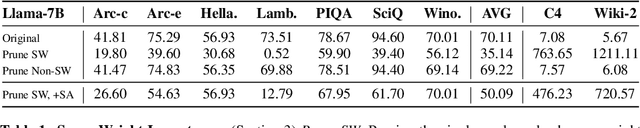
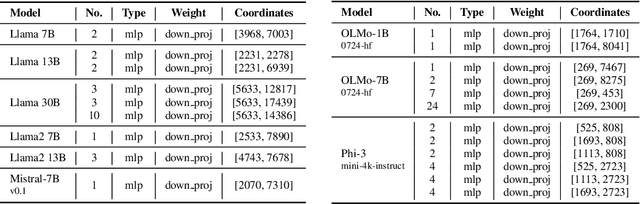

Recent works have shown a surprising result: a small fraction of Large Language Model (LLM) parameter outliers are disproportionately important to the quality of the model. LLMs contain billions of parameters, so these small fractions, such as 0.01%, translate to hundreds of thousands of parameters. In this work, we present an even more surprising finding: Pruning as few as a single parameter can destroy an LLM's ability to generate text -- increasing perplexity by 3 orders of magnitude and reducing zero-shot accuracy to guessing. We propose a data-free method for identifying such parameters, termed super weights, using a single forward pass through the model. We additionally find that these super weights induce correspondingly rare and large activation outliers, termed super activations. When preserved with high precision, super activations can improve simple round-to-nearest quantization to become competitive with state-of-the-art methods. For weight quantization, we similarly find that by preserving the super weight and clipping other weight outliers, round-to-nearest quantization can scale to much larger block sizes than previously considered. To facilitate further research into super weights, we provide an index of super weight coordinates for common, openly available LLMs.