 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
Cooperative Control of Multi-Quadrotors for Transporting Cable-Suspended Payloads: Obstacle-Aware Planning and Event-Based Nonlinear Model Predictive Control
Mar 24, 2025This paper introduces a novel methodology for the cooperative control of multiple quadrotors transporting cablesuspended payloads, emphasizing obstacle-aware planning and event-based Nonlinear Model Predictive Control (NMPC). Our approach integrates trajectory planning with real-time control through a combination of the A* algorithm for global path planning and NMPC for local control, enhancing trajectory adaptability and obstacle avoidance. We propose an advanced event-triggered control system that updates based on events identified through dynamically generated environmental maps. These maps are constructed using a dual-camera setup, which includes multi-camera systems for static obstacle detection and event cameras for high-resolution, low-latency detection of dynamic obstacles. This design is crucial for addressing fast-moving and transient obstacles that conventional cameras may overlook, particularly in environments with rapid motion and variable lighting conditions. When new obstacles are detected, the A* algorithm recalculates waypoints based on the updated map, ensuring safe and efficient navigation. This real-time obstacle detection and map updating integration allows the system to adaptively respond to environmental changes, markedly improving safety and navigation efficiency. The system employs SLAM and object detection techniques utilizing data from multi-cameras, event cameras, and IMUs for accurate localization and comprehensive environmental mapping. The NMPC framework adeptly manages the complex dynamics of multiple quadrotors and suspended payloads, incorporating safety constraints to maintain dynamic feasibility and stability. Extensive simulations validate the proposed approach, demonstrating significant enhancements in energy efficiency, computational resource management, and responsiveness.
SunCast: Solar Irradiance Nowcasting from Geosynchronous Satellite Data
Jan 17, 2022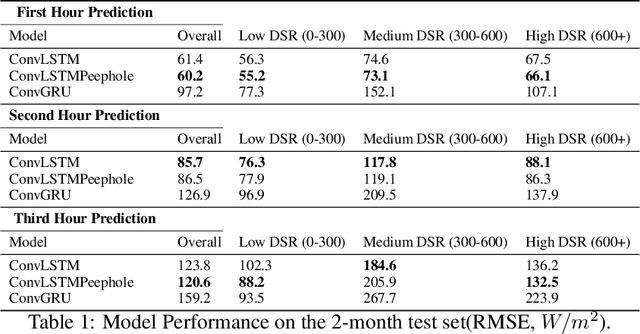
When cloud layers cover photovoltaic (PV) panels, the amount of power the panels produce fluctuates rapidly. Therefore, to maintain enough energy on a power grid to match demand, utilities companies rely on reserve power sources that typically come from fossil fuels and therefore pollute the environment. Accurate short-term PV power prediction enables operators to maximize the amount of power obtained from PV panels and safely reduce the reserve energy needed from fossil fuel sources. While several studies have developed machine learning models to predict solar irradiance at specific PV generation facilities, little work has been done to model short-term solar irradiance on a global scale. Furthermore, models that have been developed are proprietary and have architectures that are not publicly available or rely on computationally demanding Numerical Weather Prediction (NWP) models. Here, we propose a Convolutional Long Short-Term Memory Network model that treats solar nowcasting as a next frame prediction problem, is more efficient than NWP models and has a straightforward, reproducible architecture. Our models can predict solar irradiance for entire North America for up to 3 hours in under 60 seconds on a single machine without a GPU and has a RMSE of 120 W/m2 when evaluated on 2 months of data.
MedAug: Contrastive learning leveraging patient metadata improves representations for chest X-ray interpretation
Feb 21, 2021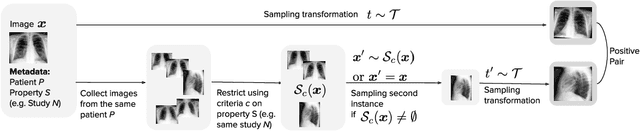
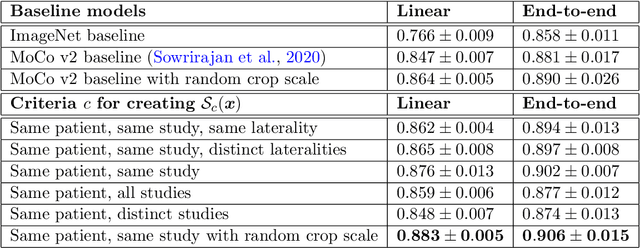

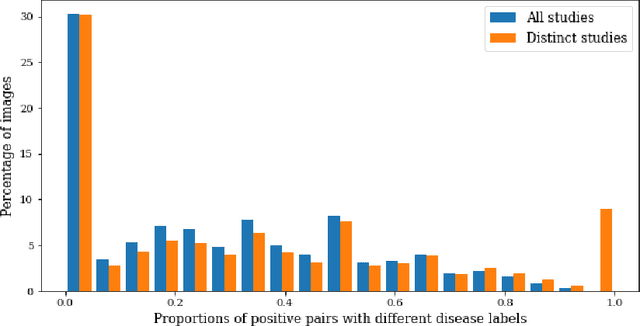
Self-supervised contrastive learning between pairs of multiple views of the same image has been shown to successfully leverage unlabeled data to produce meaningful visual representations for both natural and medical images. However, there has been limited work on determining how to select pairs for medical images, where availability of patient metadata can be leveraged to improve representations. In this work, we develop a method to select positive pairs coming from views of possibly different images through the use of patient metadata. We compare strategies for selecting positive pairs for chest X-ray interpretation including requiring them to be from the same patient, imaging study or laterality. We evaluate downstream task performance by fine-tuning the linear layer on 1% of the labeled dataset for pleural effusion classification. Our best performing positive pair selection strategy, which involves using images from the same patient from the same study across all lateralities, achieves a performance increase of 3.4% and 14.4% in mean AUC from both a previous contrastive method and ImageNet pretrained baseline respectively. Our controlled experiments show that the keys to improving downstream performance on disease classification are (1) using patient metadata to appropriately create positive pairs from different images with the same underlying pathologies, and (2) maximizing the number of different images used in query pairing. In addition, we explore leveraging patient metadata to select hard negative pairs for contrastive learning, but do not find improvement over baselines that do not use metadata. Our method is broadly applicable to medical image interpretation and allows flexibility for incorporating medical insights in choosing pairs for contrastive learning.
Adversarial Attacks on Binary Image Recognition Systems
Oct 22, 2020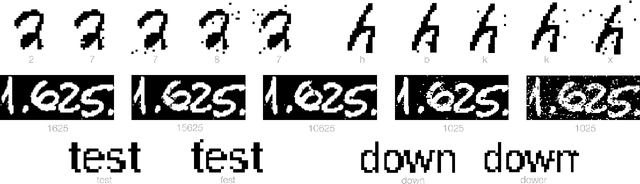
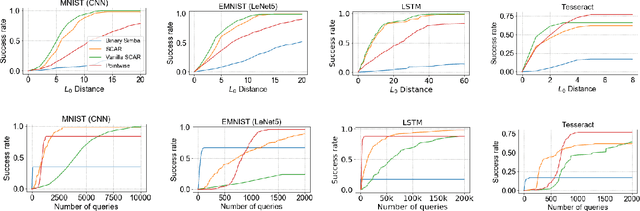

We initiate the study of adversarial attacks on models for binary (i.e. black and white) image classification. Although there has been a great deal of work on attacking models for colored and grayscale images, little is known about attacks on models for binary images. Models trained to classify binary images are used in text recognition applications such as check processing, license plate recognition, invoice processing, and many others. In contrast to colored and grayscale images, the search space of attacks on binary images is extremely restricted and noise cannot be hidden with minor perturbations in each pixel. Thus, the optimization landscape of attacks on binary images introduces new fundamental challenges. In this paper we introduce a new attack algorithm called SCAR, designed to fool classifiers of binary images. We show that SCAR significantly outperforms existing $L_0$ attacks applied to the binary setting and use it to demonstrate the vulnerability of real-world text recognition systems. SCAR's strong performance in practice contrasts with the existence of classifiers that are provably robust to large perturbations. In many cases, altering a single pixel is sufficient to trick Tesseract, a popular open-source text recognition system, to misclassify a word as a different word in the English dictionary. We also license software from providers of check processing systems to most of the major US banks and demonstrate the vulnerability of check recognitions for mobile deposits. These systems are substantially harder to fool since they classify both the handwritten amounts in digits and letters, independently. Nevertheless, we generalize SCAR to design attacks that fool state-of-the-art check processing systems using unnoticeable perturbations that lead to misclassification of deposit amounts. Consequently, this is a powerful method to perform financial fraud.
AdaLead: A simple and robust adaptive greedy search algorithm for sequence design
Oct 05, 2020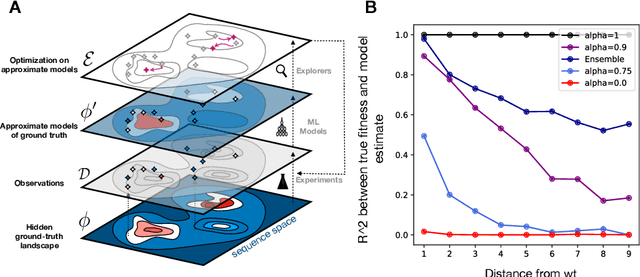
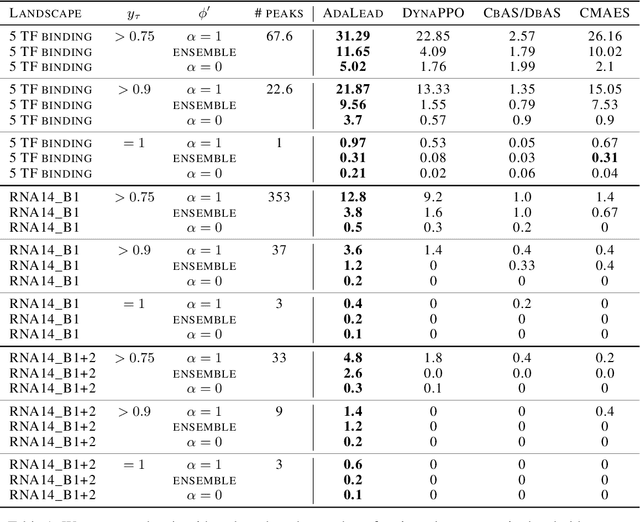
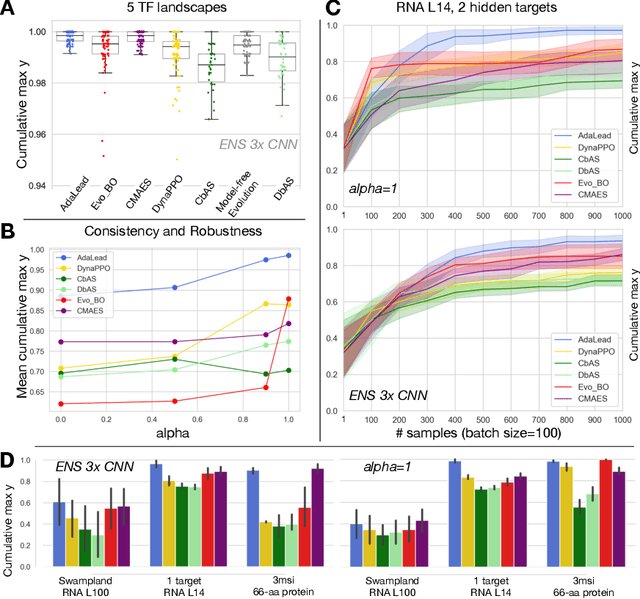
Efficient design of biological sequences will have a great impact across many industrial and healthcare domains. However, discovering improved sequences requires solving a difficult optimization problem. Traditionally, this challenge was approached by biologists through a model-free method known as "directed evolution", the iterative process of random mutation and selection. As the ability to build models that capture the sequence-to-function map improves, such models can be used as oracles to screen sequences before running experiments. In recent years, interest in better algorithms that effectively use such oracles to outperform model-free approaches has intensified. These span from approaches based on Bayesian Optimization, to regularized generative models and adaptations of reinforcement learning. In this work, we implement an open-source Fitness Landscape EXploration Sandbox (FLEXS: github.com/samsinai/FLEXS) environment to test and evaluate these algorithms based on their optimality, consistency, and robustness. Using FLEXS, we develop an easy-to-implement, scalable, and robust evolutionary greedy algorithm (AdaLead). Despite its simplicity, we show that AdaLead is a remarkably strong benchmark that out-competes more complex state of the art approaches in a variety of biologically motivated sequence design challenges.
Adversarial NLI for Factual Correctness in Text Summarisation Models
May 24, 2020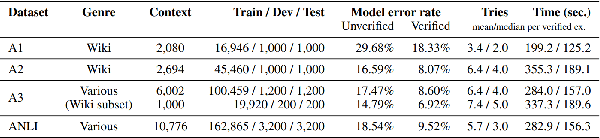
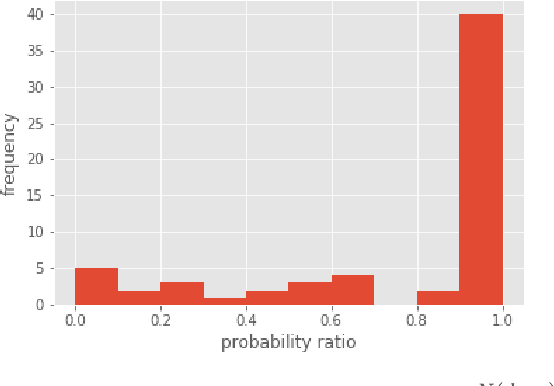


We apply the Adversarial NLI dataset to train the NLI model and show that the model has the potential to enhance factual correctness in abstract summarization. We follow the work of Falke et al. (2019), which rank multiple generated summaries based on the entailment probabilities between an source document and summaries and select the summary that has the highest entailment probability. The authors' earlier study concluded that current NLI models are not sufficiently accurate for the ranking task. We show that the Transformer models fine-tuned on the new dataset achieve significantly higher accuracy and have the potential of selecting a coherent summary.