 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImmerseDiffusion: A Generative Spatial Audio Latent Diffusion Model
Oct 19, 2024



We introduce ImmerseDiffusion, an end-to-end generative audio model that produces 3D immersive soundscapes conditioned on the spatial, temporal, and environmental conditions of sound objects. ImmerseDiffusion is trained to generate first-order ambisonics (FOA) audio, which is a conventional spatial audio format comprising four channels that can be rendered to multichannel spatial output. The proposed generative system is composed of a spatial audio codec that maps FOA audio to latent components, a latent diffusion model trained based on various user input types, namely, text prompts, spatial, temporal and environmental acoustic parameters, and optionally a spatial audio and text encoder trained in a Contrastive Language and Audio Pretraining (CLAP) style. We propose metrics to evaluate the quality and spatial adherence of the generated spatial audio. Finally, we assess the model performance in terms of generation quality and spatial conformance, comparing the two proposed modes: ``descriptive", which uses spatial text prompts) and ``parametric", which uses non-spatial text prompts and spatial parameters. Our evaluations demonstrate promising results that are consistent with the user conditions and reflect reliable spatial fidelity.
SingFake: Singing Voice Deepfake Detection
Sep 14, 2023The rise of singing voice synthesis presents critical challenges to artists and industry stakeholders over unauthorized voice usage. Unlike synthesized speech, synthesized singing voices are typically released in songs containing strong background music that may hide synthesis artifacts. Additionally, singing voices present different acoustic and linguistic characteristics from speech utterances. These unique properties make singing voice deepfake detection a relevant but significantly different problem from synthetic speech detection. In this work, we propose the singing voice deepfake detection task. We first present SingFake, the first curated in-the-wild dataset consisting of 28.93 hours of bonafide and 29.40 hours of deepfake song clips in five languages from 40 singers. We provide a train/val/test split where the test sets include various scenarios. We then use SingFake to evaluate four state-of-the-art speech countermeasure systems trained on speech utterances. We find these systems lag significantly behind their performance on speech test data. When trained on SingFake, either using separated vocal tracks or song mixtures, these systems show substantial improvement. However, our evaluations also identify challenges associated with unseen singers, communication codecs, languages, and musical contexts, calling for dedicated research into singing voice deepfake detection. The SingFake dataset and related resources are available online.
SingNet: A Real-time Singing Voice Beat and Downbeat Tracking System
Jun 04, 2023
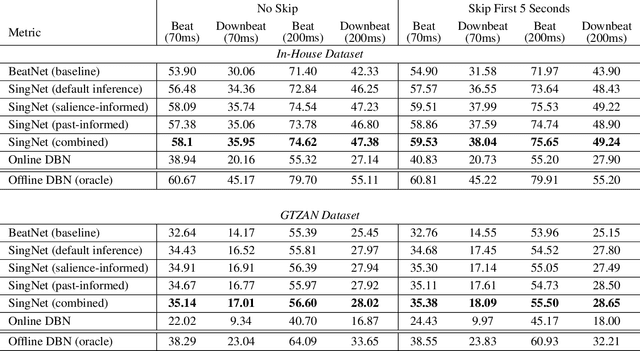
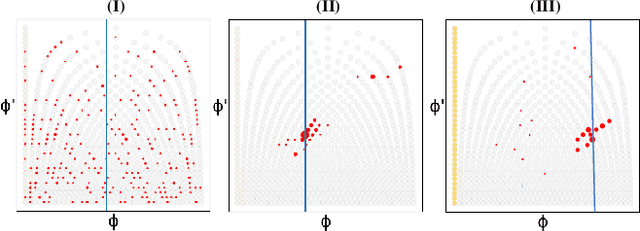
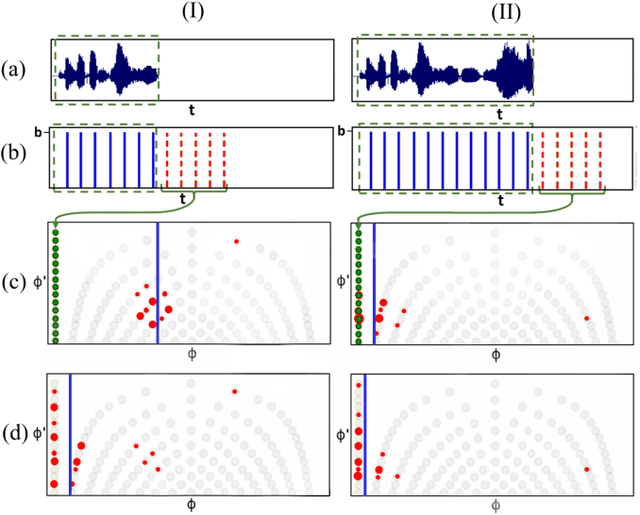
Singing voice beat and downbeat tracking posses several applications in automatic music production, analysis and manipulation. Among them, some require real-time processing, such as live performance processing and auto-accompaniment for singing inputs. This task is challenging owing to the non-trivial rhythmic and harmonic patterns in singing signals. For real-time processing, it introduces further constraints such as inaccessibility to future data and the impossibility to correct the previous results that are inconsistent with the latter ones. In this paper, we introduce the first system that tracks the beats and downbeats of singing voices in real-time. Specifically, we propose a novel dynamic particle filtering approach that incorporates offline historical data to correct the online inference by using a variable number of particles. We evaluate the performance on two datasets: GTZAN with the separated vocal tracks, and an in-house dataset with the original vocal stems. Experimental result demonstrates that our proposed approach outperforms the baseline by 3-5%.
Singing Beat Tracking With Self-supervised Front-end and Linear Transformers
Aug 31, 2022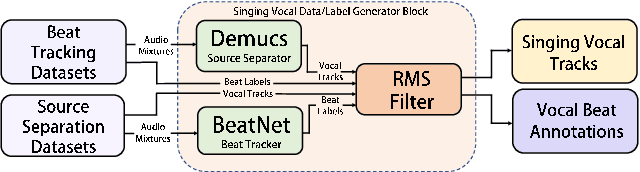
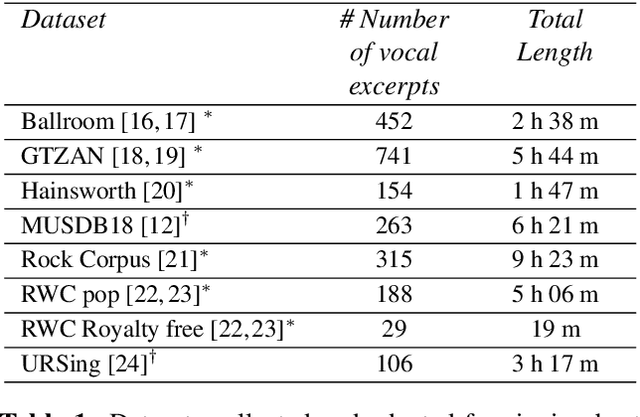

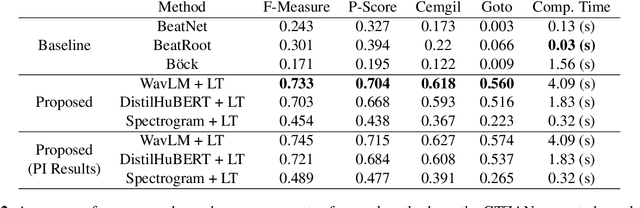
Tracking beats of singing voices without the presence of musical accompaniment can find many applications in music production, automatic song arrangement, and social media interaction. Its main challenge is the lack of strong rhythmic and harmonic patterns that are important for music rhythmic analysis in general. Even for human listeners, this can be a challenging task. As a result, existing music beat tracking systems fail to deliver satisfactory performance on singing voices. In this paper, we propose singing beat tracking as a novel task, and propose the first approach to solving this task. Our approach leverages semantic information of singing voices by employing pre-trained self-supervised WavLM and DistilHuBERT speech representations as the front-end and uses a self-attention encoder layer to predict beats. To train and test the system, we obtain separated singing voices and their beat annotations using source separation and beat tracking on complete songs, followed by manual corrections. Experiments on the 741 separated vocal tracks of the GTZAN dataset show that the proposed system outperforms several state-of-the-art music beat tracking methods by a large margin in terms of beat tracking accuracy. Ablation studies also confirm the advantages of pre-trained self-supervised speech representations over generic spectral features.
A Novel 1D State Space for Efficient Music Rhythmic Analysis
Nov 01, 2021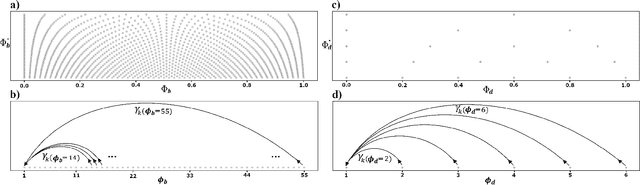
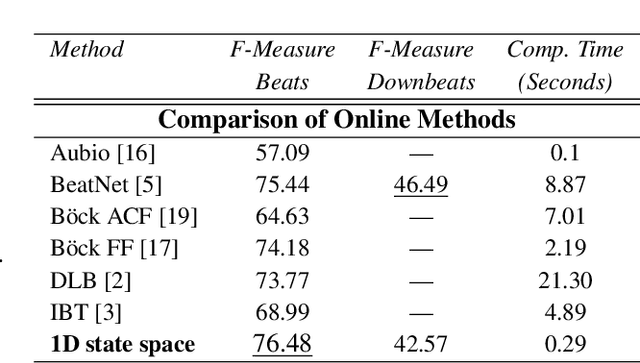
Inferring music time structures has a broad range of applications in music production, processing and analysis. Scholars have proposed various methods to analyze different aspects of time structures, including beat, downbeat, tempo and meter. Many of the state-of-the-art methods, however, are computationally expensive. This makes them inapplicable in real-world industrial settings where the scale of the music collections can be millions. This paper proposes a new state space approach for music time structure analysis. The proposed approach collapses the commonly used 2D state spaces into 1D through a jump-back reward strategy. This reduces the state space size drastically. We then utilize the proposed method for casual, joint beat, downbeat, tempo, and meter tracking, and compare it against several previous beat and downbeat tracking methods. The proposed method delivers comparable performance with the state-of-the-art joint casual models with a much smaller state space and a more than 30 times speedup.
Learning Sparse Analytic Filters for Piano Transcription
Aug 23, 2021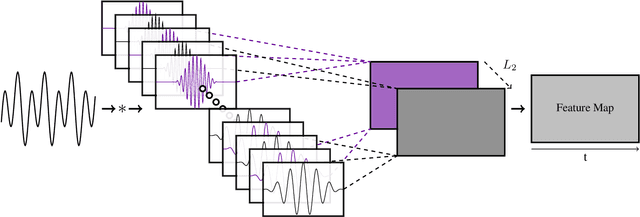
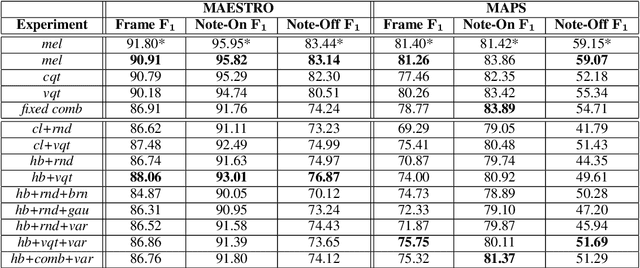
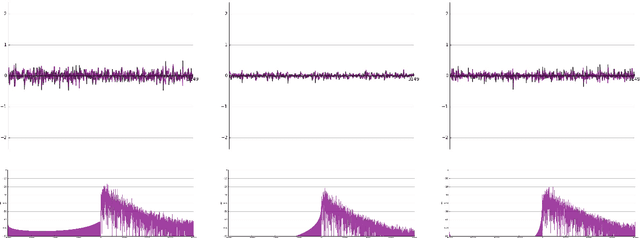
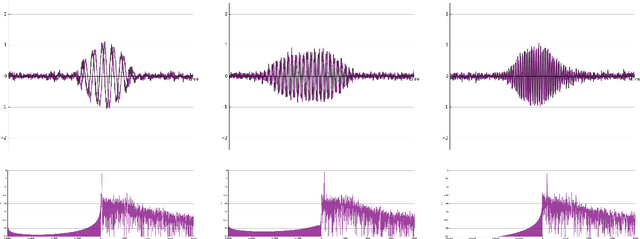
In recent years, filterbank learning has become an increasingly popular strategy for various audio-related machine learning tasks. This is partly due to its ability to discover task-specific audio characteristics which can be leveraged in downstream processing. It is also a natural extension of the nearly ubiquitous deep learning methods employed to tackle a diverse array of audio applications. In this work, several variations of a frontend filterbank learning module are investigated for piano transcription, a challenging low-level music information retrieval task. We build upon a standard piano transcription model, modifying only the feature extraction stage. The filterbank module is designed such that its complex filters are unconstrained 1D convolutional kernels with long receptive fields. Additional variations employ the Hilbert transform to render the filters intrinsically analytic and apply variational dropout to promote filterbank sparsity. Transcription results are compared across all experiments, and we offer visualization and analysis of the filterbanks.
BeatNet: CRNN and Particle Filtering for Online Joint Beat Downbeat and Meter Tracking
Aug 08, 2021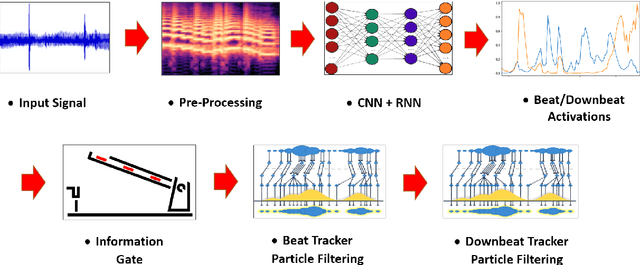
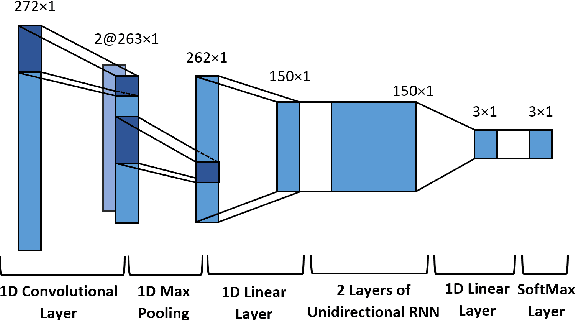
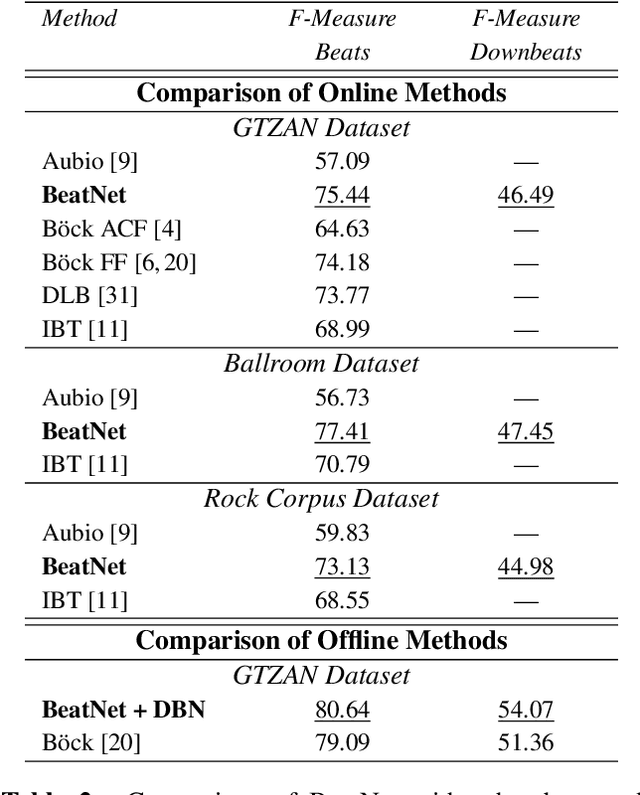
The online estimation of rhythmic information, such as beat positions, downbeat positions, and meter, is critical for many real-time music applications. Musical rhythm comprises complex hierarchical relationships across time, rendering its analysis intrinsically challenging and at times subjective. Furthermore, systems which attempt to estimate rhythmic information in real-time must be causal and must produce estimates quickly and efficiently. In this work, we introduce an online system for joint beat, downbeat, and meter tracking, which utilizes causal convolutional and recurrent layers, followed by a pair of sequential Monte Carlo particle filters applied during inference. The proposed system does not need to be primed with a time signature in order to perform downbeat tracking, and is instead able to estimate meter and adjust the predictions over time. Additionally, we propose an information gate strategy to significantly decrease the computational cost of particle filtering during the inference step, making the system much faster than previous sampling-based methods. Experiments on the GTZAN dataset, which is unseen during training, show that the system outperforms various online beat and downbeat tracking systems and achieves comparable performance to a baseline offline joint method.