 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOALA: Co-Aligned Autoencoders for Learning Semantically Enriched Audio Representations
Paper and Code
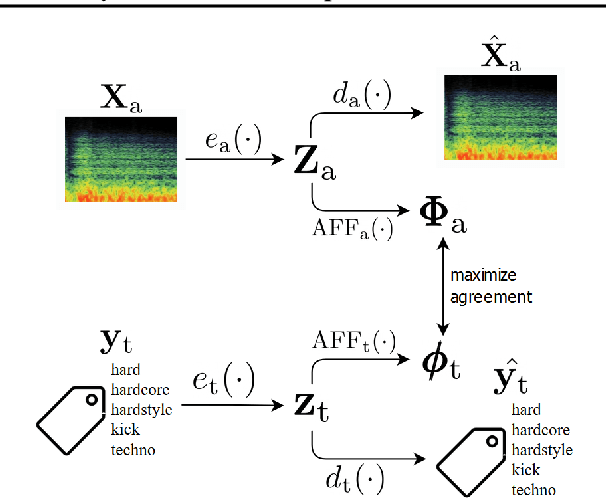

Audio representation learning based on deep neural networks (DNNs) emerged as an alternative approach to hand-crafted features. For achieving high performance, DNNs often need a large amount of annotated data which can be difficult and costly to obtain. In this paper, we propose a method for learning audio representations, aligning the learned latent representations of audio and associated tags. Aligning is done by maximizing the agreement of the latent representations of audio and tags, using a contrastive loss. The result is an audio embedding model which reflects acoustic and semantic characteristics of sounds. We evaluate the quality of our embedding model, measuring its performance as a feature extractor on three different tasks (namely, sound event recognition, and music genre and musical instrument classification), and investigate what type of characteristics the model captures. Our results are promising, sometimes in par with the state-of-the-art in the considered tasks and the embeddings produced with our method are well correlated with some acoustic descriptors.