 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Audio Reveal Music Performance Difficulty? Insights from the Piano Syllabus Dataset
Paper and Code
Mar 06, 2024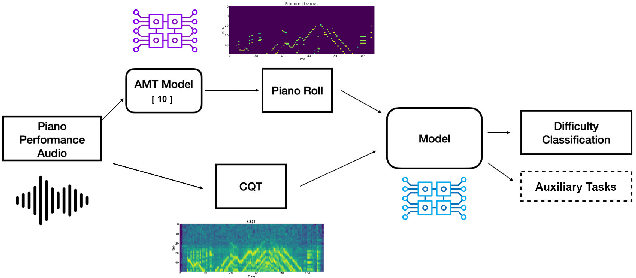
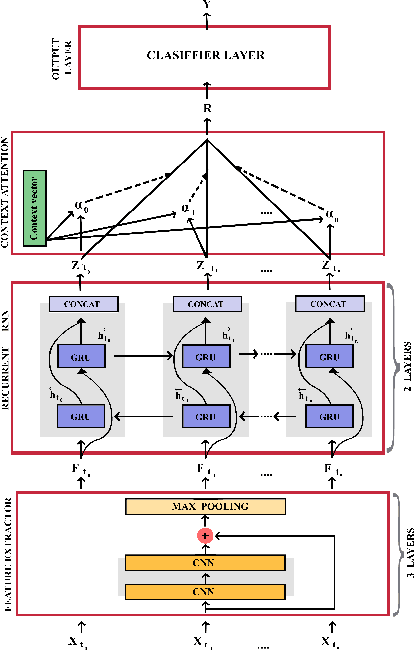
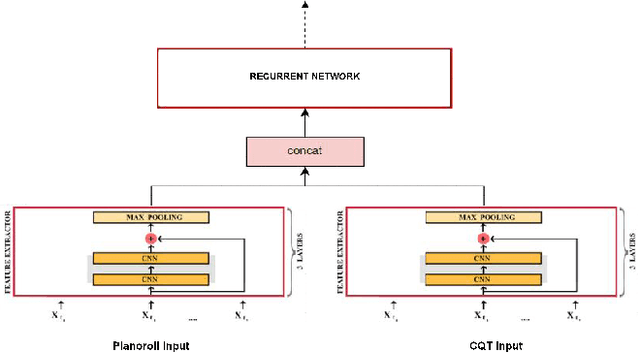

Automatically estimating the performance difficulty of a music piece represents a key process in music education to create tailored curricula according to the individual needs of the students. Given its relevance, the Music Information Retrieval (MIR) field depicts some proof-of-concept works addressing this task that mainly focuses on high-level music abstractions such as machine-readable scores or music sheet images. In this regard, the potential of directly analyzing audio recordings has been generally neglected, which prevents students from exploring diverse music pieces that may not have a formal symbolic-level transcription. This work pioneers in the automatic estimation of performance difficulty of music pieces on audio recordings with two precise contributions: (i) the first audio-based difficulty estimation dataset -- namely, Piano Syllabus (PSyllabus) dataset -- featuring 7,901 piano pieces across 11 difficulty levels from 1,233 composers; and (ii) a recognition framework capable of managing different input representations -- both unimodal and multimodal manners -- directly derived from audio to perform the difficulty estimation task. The comprehensive experimentation comprising different pre-training schemes, input modalities, and multi-task scenarios prove the validity of the proposal and establishes PSyllabus as a reference dataset for audio-based difficulty estimation in the MIR field. The dataset as well as the developed code and trained models are publicly shared to promote further research in the field.