 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNegative Feedback for Music Personalization
Jun 06, 2024


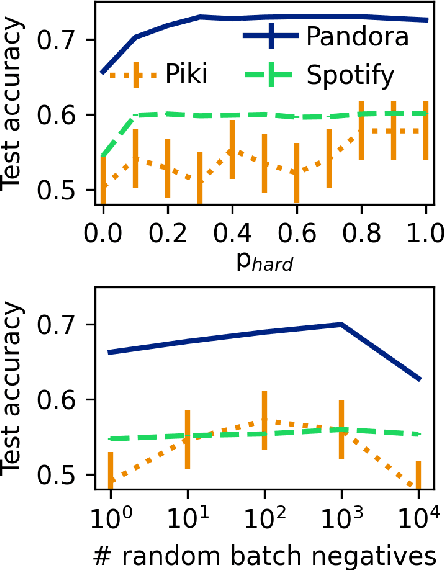
Next-item recommender systems are often trained using only positive feedback with randomly-sampled negative feedback. We show the benefits of using real negative feedback both as inputs into the user sequence and also as negative targets for training a next-song recommender system for internet radio. In particular, using explicit negative samples during training helps reduce training time by ~60% while also improving test accuracy by ~6%; adding user skips as additional inputs also can considerably increase user coverage alongside slightly improving accuracy. We test the impact of using a large number of random negative samples to capture a 'harder' one and find that the test accuracy increases with more randomly-sampled negatives, but only to a point. Too many random negatives leads to false negatives that limits the lift, which is still lower than if using true negative feedback. We also find that the test accuracy is fairly robust with respect to the proportion of different feedback types, and compare the learned embeddings for different feedback types.
Supervised and Unsupervised Learning of Audio Representations for Music Understanding
Oct 07, 2022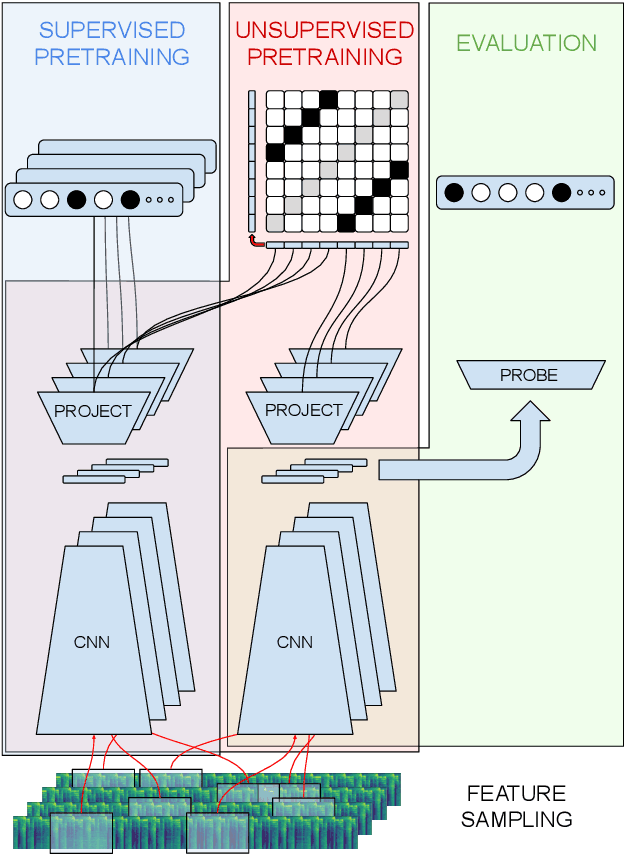
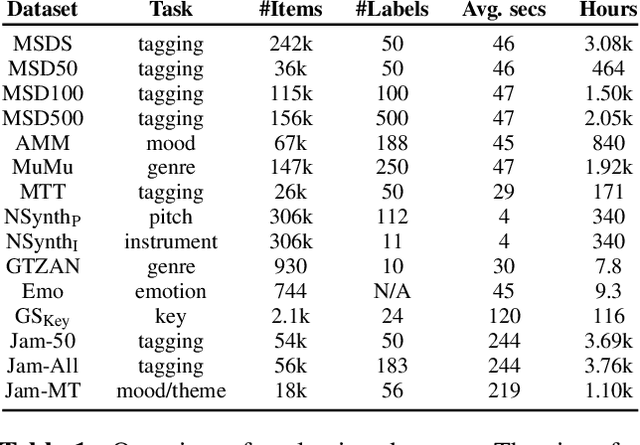
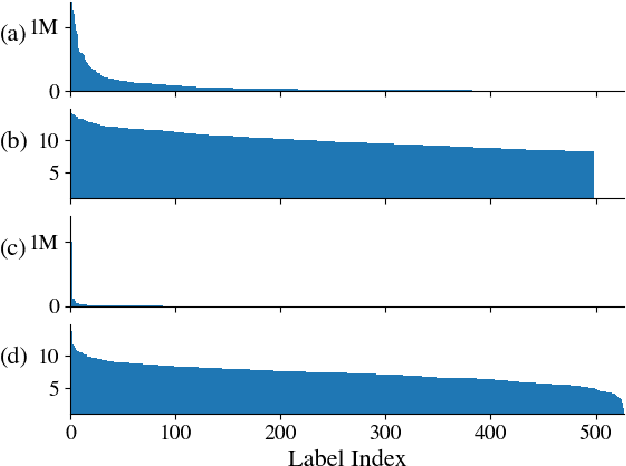
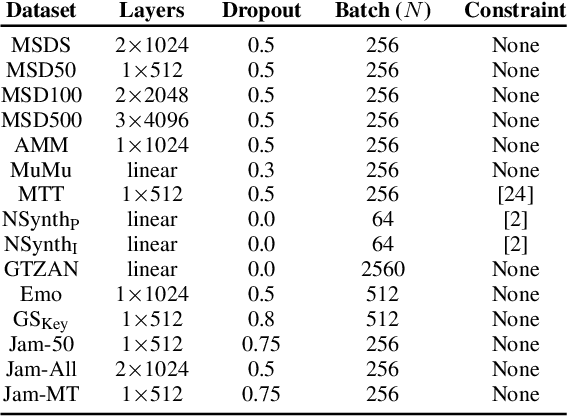
In this work, we provide a broad comparative analysis of strategies for pre-training audio understanding models for several tasks in the music domain, including labelling of genre, era, origin, mood, instrumentation, key, pitch, vocal characteristics, tempo and sonority. Specifically, we explore how the domain of pre-training datasets (music or generic audio) and the pre-training methodology (supervised or unsupervised) affects the adequacy of the resulting audio embeddings for downstream tasks. We show that models trained via supervised learning on large-scale expert-annotated music datasets achieve state-of-the-art performance in a wide range of music labelling tasks, each with novel content and vocabularies. This can be done in an efficient manner with models containing less than 100 million parameters that require no fine-tuning or reparameterization for downstream tasks, making this approach practical for industry-scale audio catalogs. Within the class of unsupervised learning strategies, we show that the domain of the training dataset can significantly impact the performance of representations learned by the model. We find that restricting the domain of the pre-training dataset to music allows for training with smaller batch sizes while achieving state-of-the-art in unsupervised learning -- and in some cases, supervised learning -- for music understanding. We also corroborate that, while achieving state-of-the-art performance on many tasks, supervised learning can cause models to specialize to the supervised information provided, somewhat compromising a model's generality.