 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Emotions Perceived from Sounds
Dec 04, 2020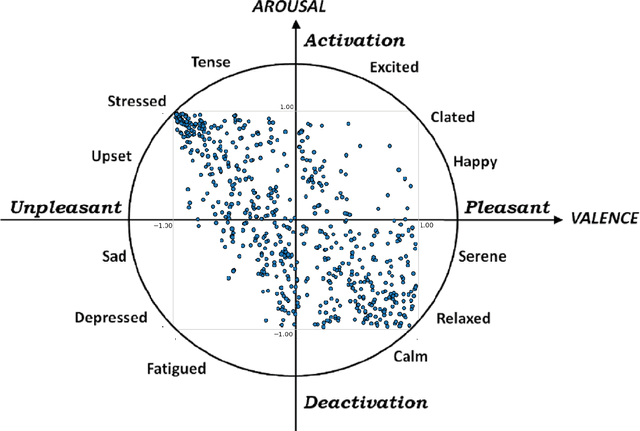

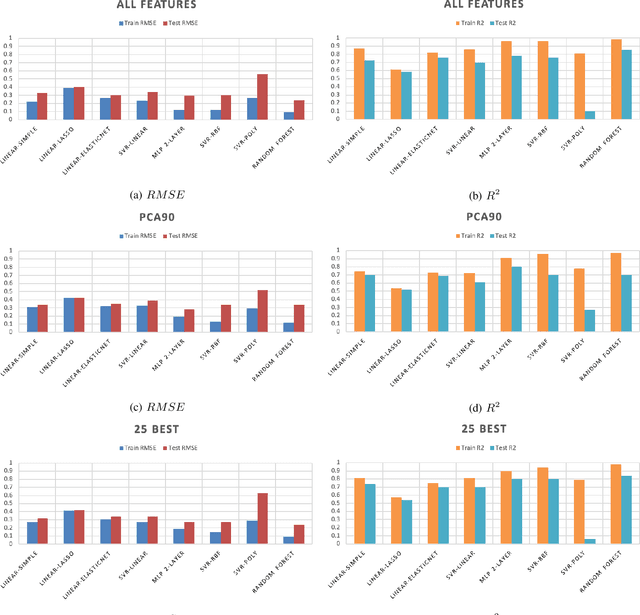
Sonification is the science of communication of data and events to users through sounds. Auditory icons, earcons, and speech are the common auditory display schemes utilized in sonification, or more specifically in the use of audio to convey information. Once the captured data are perceived, their meanings, and more importantly, intentions can be interpreted more easily and thus can be employed as a complement to visualization techniques. Through auditory perception it is possible to convey information related to temporal, spatial, or some other context-oriented information. An important research question is whether the emotions perceived from these auditory icons or earcons are predictable in order to build an automated sonification platform. This paper conducts an experiment through which several mainstream and conventional machine learning algorithms are developed to study the prediction of emotions perceived from sounds. To do so, the key features of sounds are captured and then are modeled using machine learning algorithms using feature reduction techniques. We observe that it is possible to predict perceived emotions with high accuracy. In particular, the regression based on Random Forest demonstrated its superiority compared to other machine learning algorithms.
Fake Reviews Detection through Analysis of Linguistic Features
Oct 08, 2020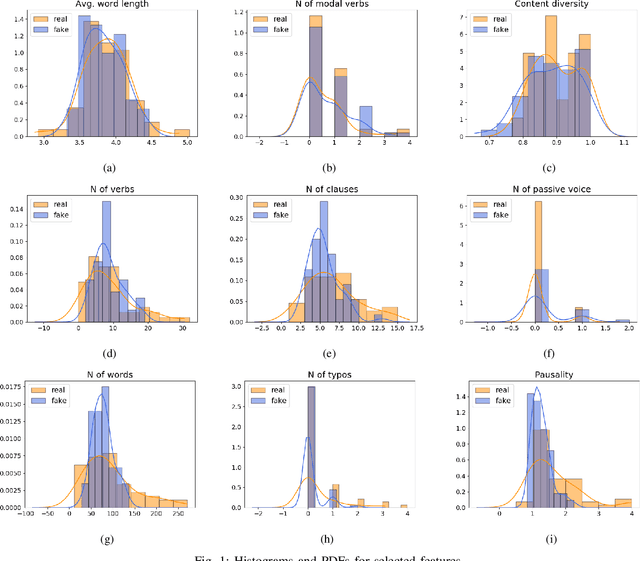
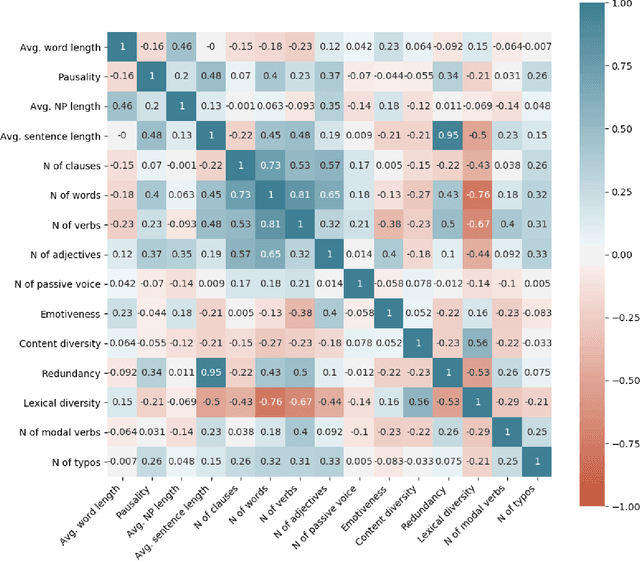
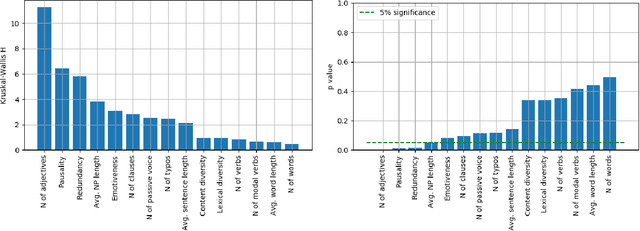
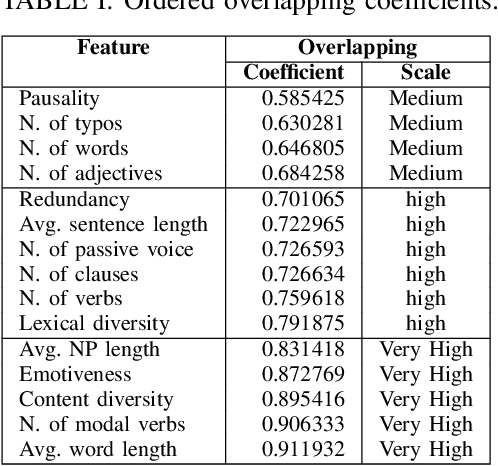
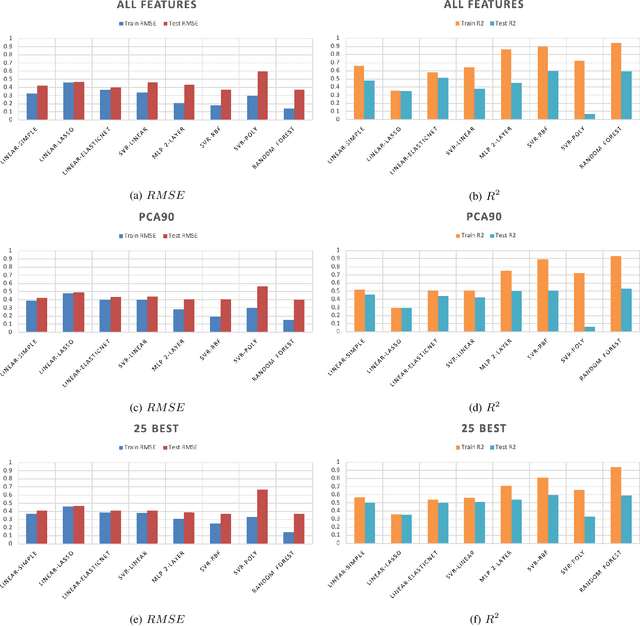
Online reviews play an integral part for success or failure of businesses. Prior to purchasing services or goods, customers first review the online comments submitted by previous customers. However, it is possible to superficially boost or hinder some businesses through posting counterfeit and fake reviews. This paper explores a natural language processing approach to identify fake reviews. We present a detailed analysis of linguistic features for distinguishing fake and trustworthy online reviews. We study 15 linguistic features and measure their significance and importance towards the classification schemes employed in this study. Our results indicate that fake reviews tend to include more redundant terms and pauses, and generally contain longer sentences. The application of several machine learning classification algorithms revealed that we were able to discriminate fake from real reviews with high accuracy using these linguistic features.
String-based methods for tonal harmony: A corpus study of Haydn's string quartets
Jun 27, 2020

This chapter considers how string-based methods might be adapted to address music-analytic questions related to the discovery of musical organization, with particular attention devoted to the analysis of tonal harmony. I begin by applying the taxonomy of mental organization proposed by Mandler (1979) to the concept of musical organization. Using this taxonomy as a guide, I then present evidence for three principles of tonal harmony -- recurrence, syntax, and recursion -- using a corpus of Haydn string quartets.
Fake Reviews Detection through Ensemble Learning
Jun 14, 2020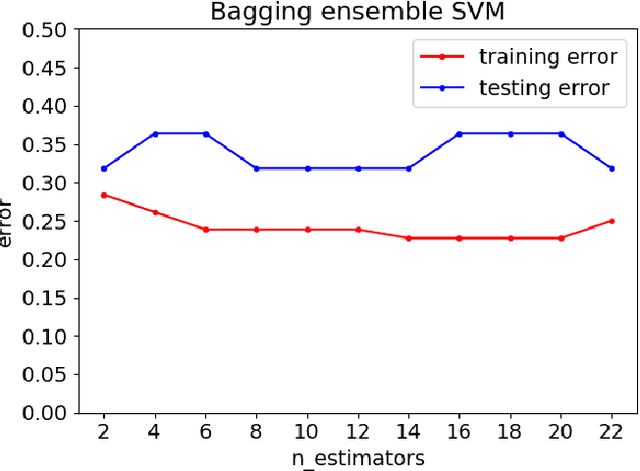
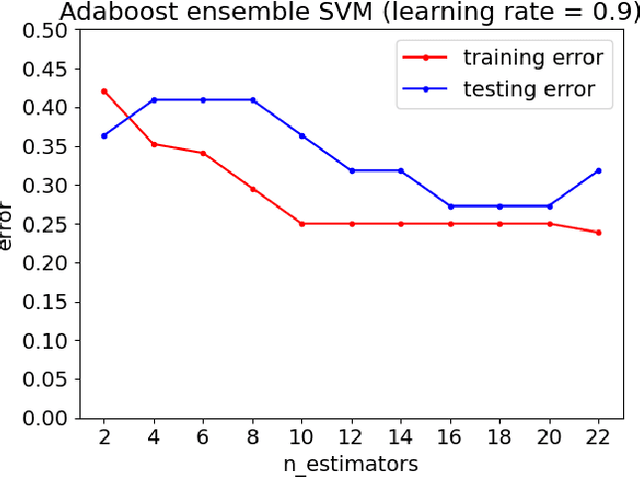
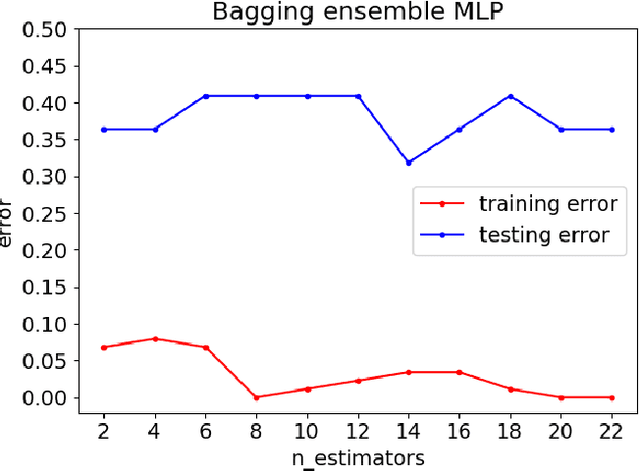
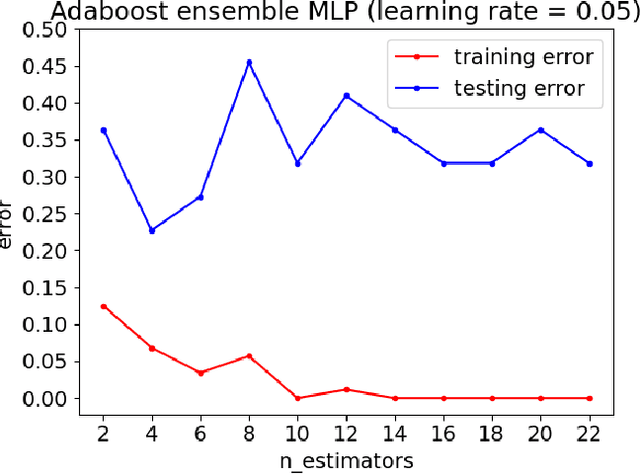
Customers represent their satisfactions of consuming products by sharing their experiences through the utilization of online reviews. Several machine learning-based approaches can automatically detect deceptive and fake reviews. Recently, there have been studies reporting the performance of ensemble learning-based approaches in comparison to conventional machine learning techniques. Motivated by the recent trends in ensemble learning, this paper evaluates the performance of ensemble learning-based approaches to identify bogus online information. The application of a number of ensemble learning-based approaches to a collection of fake restaurant reviews that we developed show that these ensemble learning-based approaches detect deceptive information better than conventional machine learning algorithms.
A Large-Scale Study of Language Models for Chord Prediction
Apr 05, 2018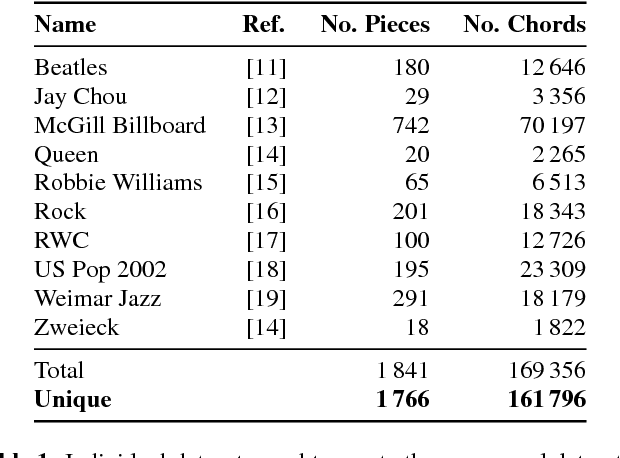
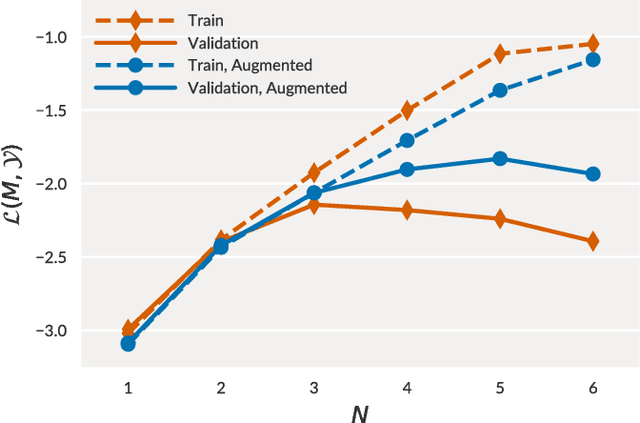


We conduct a large-scale study of language models for chord prediction. Specifically, we compare N-gram models to various flavours of recurrent neural networks on a comprehensive dataset comprising all publicly available datasets of annotated chords known to us. This large amount of data allows us to systematically explore hyper-parameter settings for the recurrent neural networks---a crucial step in achieving good results with this model class. Our results show not only a quantitative difference between the models, but also a qualitative one: in contrast to static N-gram models, certain RNN configurations adapt to the songs at test time. This finding constitutes a further step towards the development of chord recognition systems that are more aware of local musical context than what was previously possible.
What were you expecting? Using Expectancy Features to Predict Expressive Performances of Classical Piano Music
Sep 11, 2017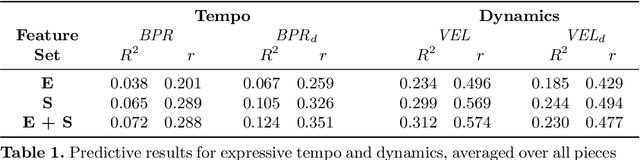
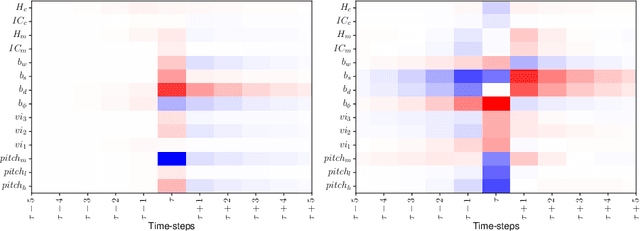
In this paper we present preliminary work examining the relationship between the formation of expectations and the realization of musical performances, paying particular attention to expressive tempo and dynamics. To compute features that reflect what a listener is expecting to hear, we employ a computational model of auditory expectation called the Information Dynamics of Music model (IDyOM). We then explore how well these expectancy features -- when combined with score descriptors using the Basis-Function modeling approach -- can predict expressive tempo and dynamics in a dataset of Mozart piano sonata performances. Our results suggest that using expectancy features significantly improves the predictions for tempo.