 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context and Few-Shots Learning for Forecasting Time Series Data based on Large Language Models
Dec 08, 2025Existing data-driven approaches in modeling and predicting time series data include ARIMA (Autoregressive Integrated Moving Average), Transformer-based models, LSTM (Long Short-Term Memory) and TCN (Temporal Convolutional Network). These approaches, and in particular deep learning-based models such as LSTM and TCN, have shown great results in predicting time series data. With the advancement of leveraging pre-trained foundation models such as Large Language Models (LLMs) and more notably Google's recent foundation model for time series data, {\it TimesFM} (Time Series Foundation Model), it is of interest to investigate whether these foundation models have the capability of outperforming existing modeling approaches in analyzing and predicting time series data. This paper investigates the performance of using LLM models for time series data prediction. We investigate the in-context learning methodology in the training of LLM models that are specific to the underlying application domain. More specifically, the paper explores training LLMs through in-context, zero-shot and few-shot learning and forecasting time series data with OpenAI {\tt o4-mini} and Gemini 2.5 Flash Lite, as well as the recent Google's Transformer-based TimesFM, a time series-specific foundation model, along with two deep learning models, namely TCN and LSTM networks. The findings indicate that TimesFM has the best overall performance with the lowest RMSE value (0.3023) and the competitive inference time (266 seconds). Furthermore, OpenAI's o4-mini also exhibits a good performance based on Zero Shot learning. These findings highlight pre-trained time series foundation models as a promising direction for real-time forecasting, enabling accurate and scalable deployment with minimal model adaptation.
The Performance of the LSTM-based Code Generated by Large Language Models (LLMs) in Forecasting Time Series Data
Nov 27, 2024



As an intriguing case is the goodness of the machine and deep learning models generated by these LLMs in conducting automated scientific data analysis, where a data analyst may not have enough expertise in manually coding and optimizing complex deep learning models and codes and thus may opt to leverage LLMs to generate the required models. This paper investigates and compares the performance of the mainstream LLMs, such as ChatGPT, PaLM, LLama, and Falcon, in generating deep learning models for analyzing time series data, an important and popular data type with its prevalent applications in many application domains including financial and stock market. This research conducts a set of controlled experiments where the prompts for generating deep learning-based models are controlled with respect to sensitivity levels of four criteria including 1) Clarify and Specificity, 2) Objective and Intent, 3) Contextual Information, and 4) Format and Style. While the results are relatively mix, we observe some distinct patterns. We notice that using LLMs, we are able to generate deep learning-based models with executable codes for each dataset seperatly whose performance are comparable with the manually crafted and optimized LSTM models for predicting the whole time series dataset. We also noticed that ChatGPT outperforms the other LLMs in generating more accurate models. Furthermore, we observed that the goodness of the generated models vary with respect to the ``temperature'' parameter used in configuring LLMS. The results can be beneficial for data analysts and practitioners who would like to leverage generative AIs to produce good prediction models with acceptable goodness.
A Survey on Blockchain-Based Federated Learning and Data Privacy
Jun 29, 2023
Federated learning is a decentralized machine learning paradigm that allows multiple clients to collaborate by leveraging local computational power and the models transmission. This method reduces the costs and privacy concerns associated with centralized machine learning methods while ensuring data privacy by distributing training data across heterogeneous devices. On the other hand, federated learning has the drawback of data leakage due to the lack of privacy-preserving mechanisms employed during storage, transfer, and sharing, thus posing significant risks to data owners and suppliers. Blockchain technology has emerged as a promising technology for offering secure data-sharing platforms in federated learning, especially in Industrial Internet of Things (IIoT) settings. This survey aims to compare the performance and security of various data privacy mechanisms adopted in blockchain-based federated learning architectures. We conduct a systematic review of existing literature on secure data-sharing platforms for federated learning provided by blockchain technology, providing an in-depth overview of blockchain-based federated learning, its essential components, and discussing its principles, and potential applications. The primary contribution of this survey paper is to identify critical research questions and propose potential directions for future research in blockchain-based federated learning.
A Comparative Study of Detecting Anomalies in Time Series Data Using LSTM and TCN Models
Dec 17, 2021
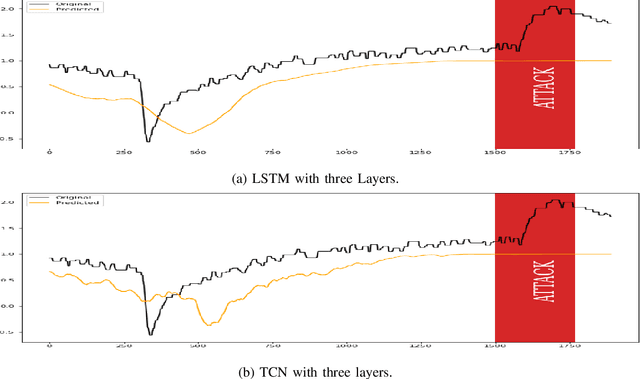
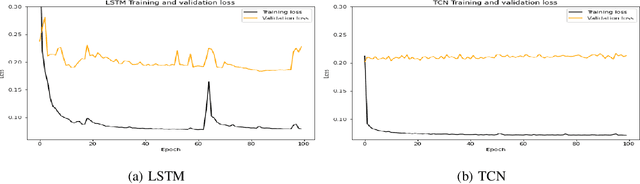
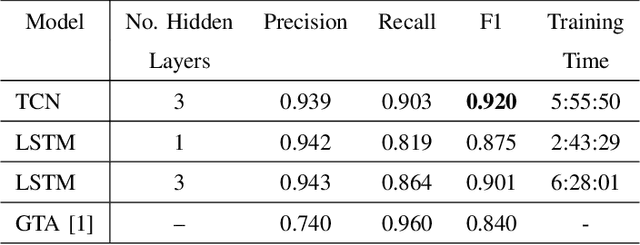
There exist several data-driven approaches that enable us model time series data including traditional regression-based modeling approaches (i.e., ARIMA). Recently, deep learning techniques have been introduced and explored in the context of time series analysis and prediction. A major research question to ask is the performance of these many variations of deep learning techniques in predicting time series data. This paper compares two prominent deep learning modeling techniques. The Recurrent Neural Network (RNN)-based Long Short-Term Memory (LSTM) and the convolutional Neural Network (CNN)-based Temporal Convolutional Networks (TCN) are compared and their performance and training time are reported. According to our experimental results, both modeling techniques perform comparably having TCN-based models outperform LSTM slightly. Moreover, the CNN-based TCN model builds a stable model faster than the RNN-based LSTM models.
Attack Prediction using Hidden Markov Model
Jun 03, 2021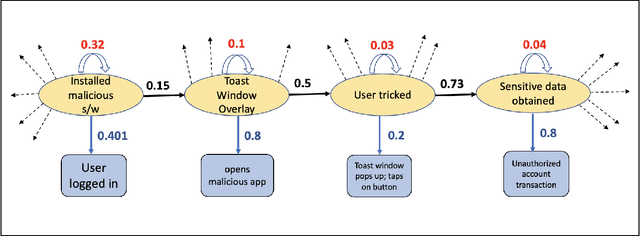

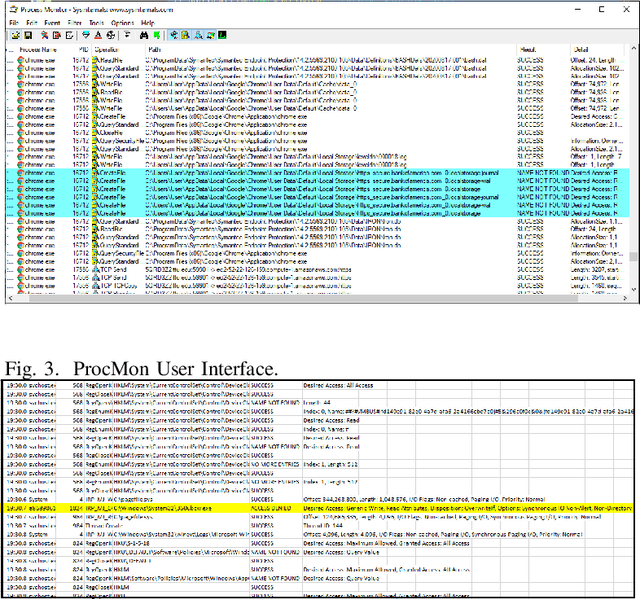

It is important to predict any adversarial attacks and their types to enable effective defense systems. Often it is hard to label such activities as malicious ones without adequate analytical reasoning. We propose the use of Hidden Markov Model (HMM) to predict the family of related attacks. Our proposed model is based on the observations often agglomerated in the form of log files and from the target or the victim's perspective. We have built an HMM-based prediction model and implemented our proposed approach using Viterbi algorithm, which generates a sequence of states corresponding to stages of a particular attack. As a proof of concept and also to demonstrate the performance of the model, we have conducted a case study on predicting a family of attacks called Action Spoofing.
Toward Explainable Users: Using NLP to Enable AI to Understand Users' Perceptions of Cyber Attacks
Jun 03, 2021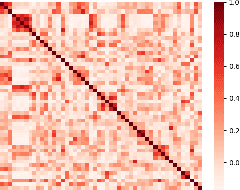
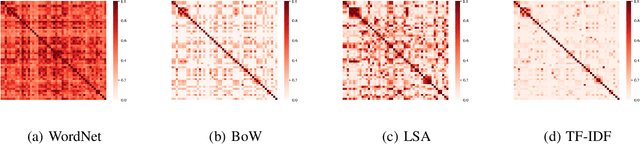
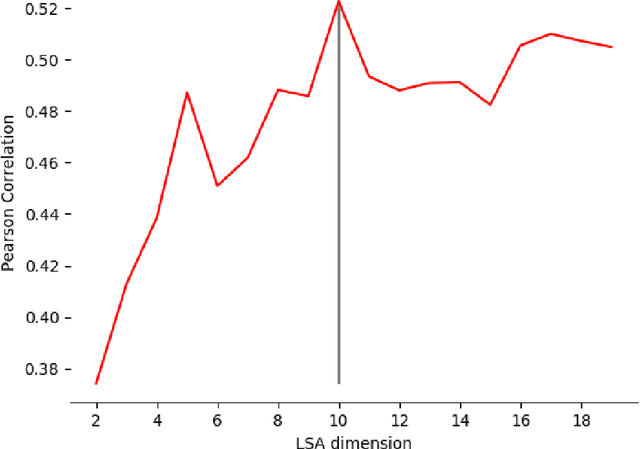

To understand how end-users conceptualize consequences of cyber security attacks, we performed a card sorting study, a well-known technique in Cognitive Sciences, where participants were free to group the given consequences of chosen cyber attacks into as many categories as they wished using rationales they see fit. The results of the open card sorting study showed a large amount of inter-participant variation making the research team wonder how the consequences of security attacks were comprehended by the participants. As an exploration of whether it is possible to explain user's mental model and behavior through Artificial Intelligence (AI) techniques, the research team compared the card sorting data with the outputs of a number of Natural Language Processing (NLP) techniques with the goal of understanding how participants perceived and interpreted the consequences of cyber attacks written in natural languages. The results of the NLP-based exploration methods revealed an interesting observation implying that participants had mostly employed checking individual keywords in each sentence to group cyber attack consequences together and less considered the semantics behind the description of consequences of cyber attacks. The results reported in this paper are seemingly useful and important for cyber attacks comprehension from user's perspectives. To the best of our knowledge, this paper is the first introducing the use of AI techniques in explaining and modeling users' behavior and their perceptions about a context. The novel idea introduced here is about explaining users using AI.
Phishing Detection through Email Embeddings
Dec 28, 2020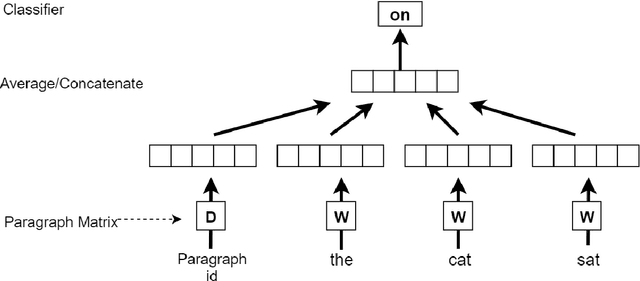
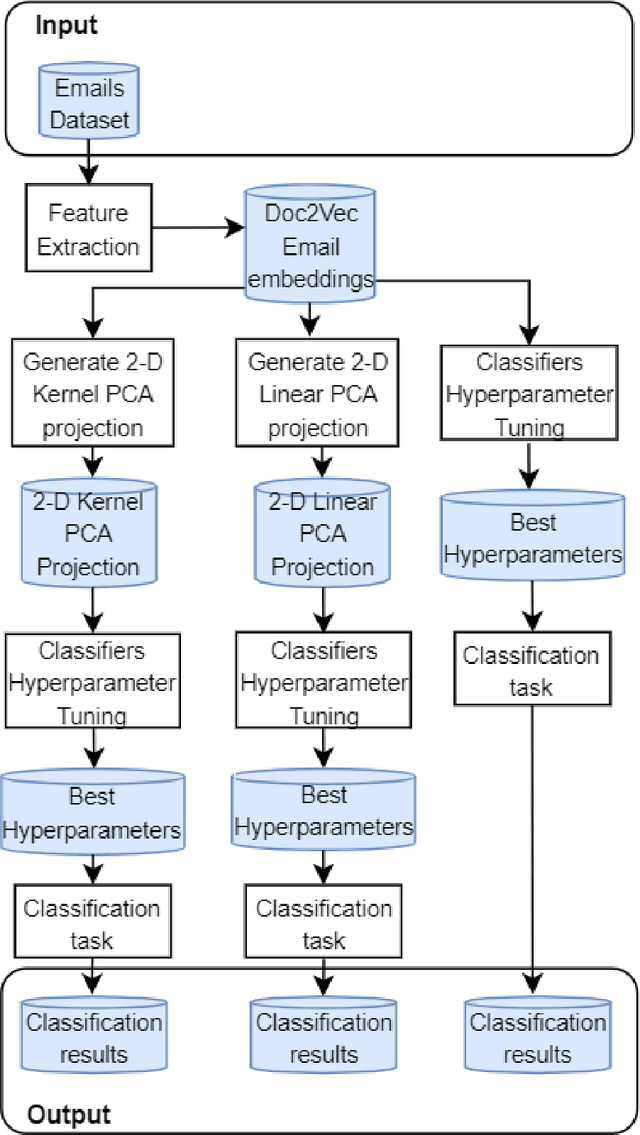
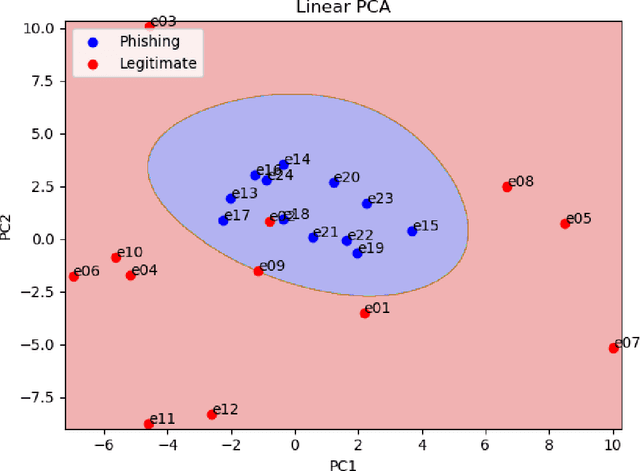
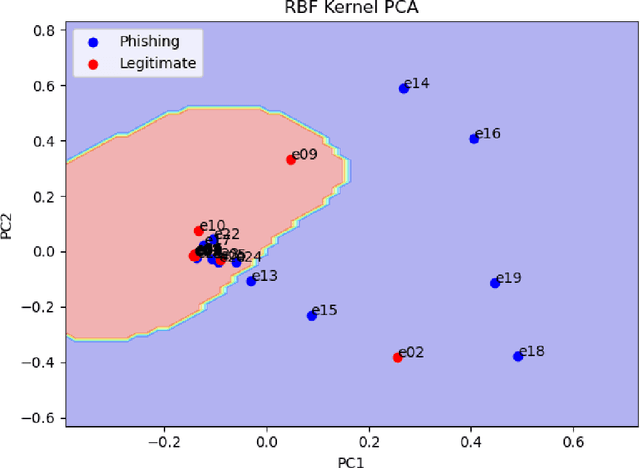
The problem of detecting phishing emails through machine learning techniques has been discussed extensively in the literature. Conventional and state-of-the-art machine learning algorithms have demonstrated the possibility of building classifiers with high accuracy. The existing research studies treat phishing and genuine emails through general indicators and thus it is not exactly clear what phishing features are contributing to variations of the classifiers. In this paper, we crafted a set of phishing and legitimate emails with similar indicators in order to investigate whether these cues are captured or disregarded by email embeddings, i.e., vectorizations. We then fed machine learning classifiers with the carefully crafted emails to find out about the performance of email embeddings developed. Our results show that using these indicators, email embeddings techniques is effective for classifying emails as phishing or legitimate.
Predicting Emotions Perceived from Sounds
Dec 04, 2020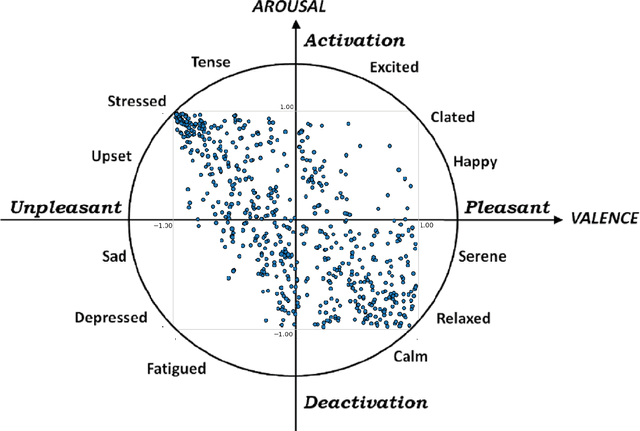

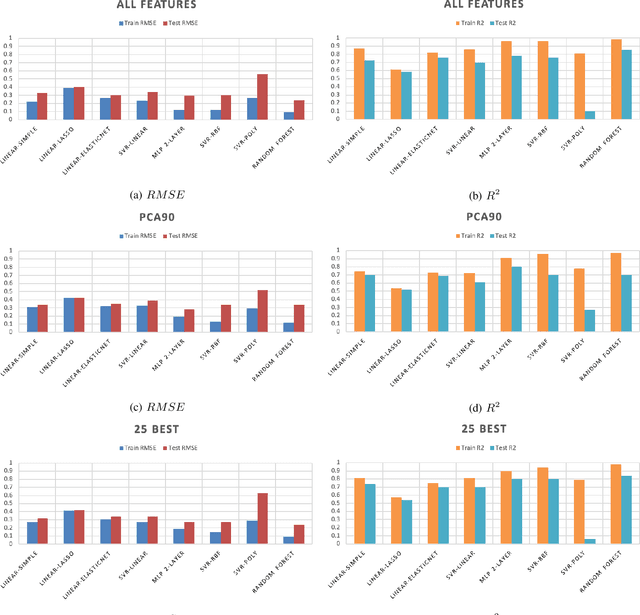
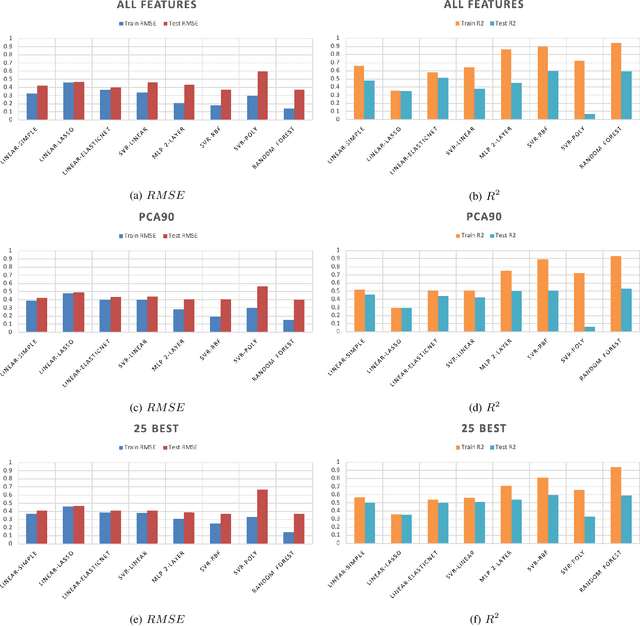
Sonification is the science of communication of data and events to users through sounds. Auditory icons, earcons, and speech are the common auditory display schemes utilized in sonification, or more specifically in the use of audio to convey information. Once the captured data are perceived, their meanings, and more importantly, intentions can be interpreted more easily and thus can be employed as a complement to visualization techniques. Through auditory perception it is possible to convey information related to temporal, spatial, or some other context-oriented information. An important research question is whether the emotions perceived from these auditory icons or earcons are predictable in order to build an automated sonification platform. This paper conducts an experiment through which several mainstream and conventional machine learning algorithms are developed to study the prediction of emotions perceived from sounds. To do so, the key features of sounds are captured and then are modeled using machine learning algorithms using feature reduction techniques. We observe that it is possible to predict perceived emotions with high accuracy. In particular, the regression based on Random Forest demonstrated its superiority compared to other machine learning algorithms.
Fake Reviews Detection through Analysis of Linguistic Features
Oct 08, 2020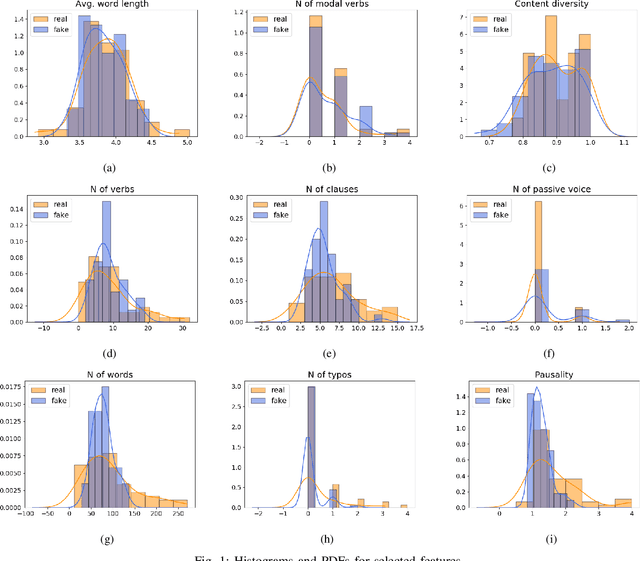
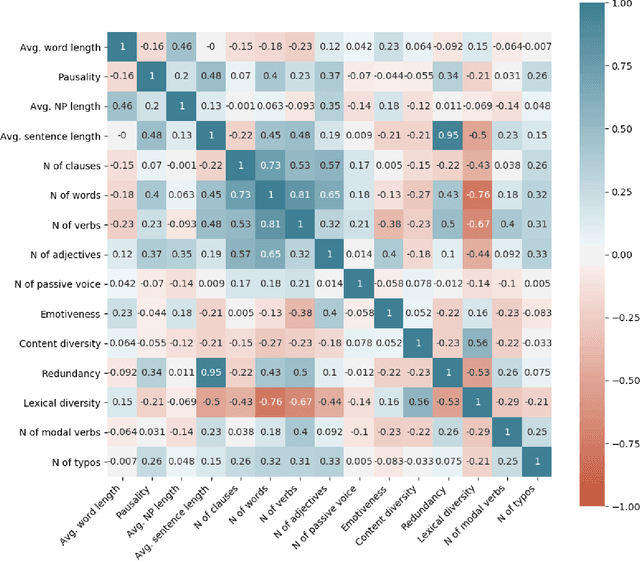
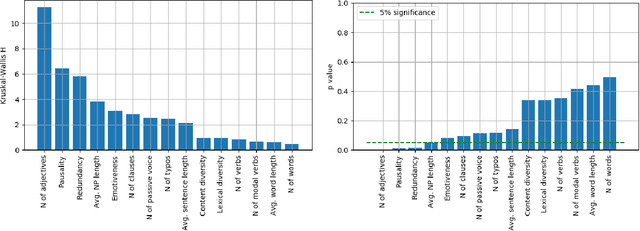
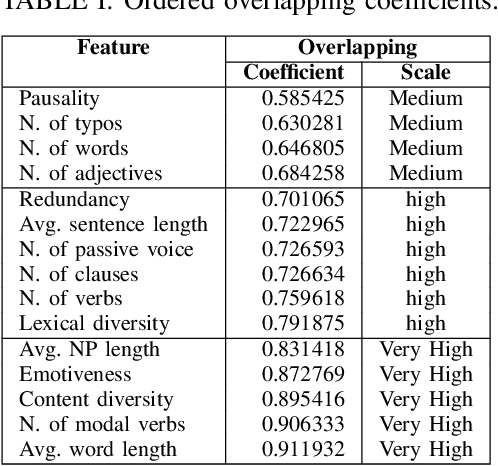
Online reviews play an integral part for success or failure of businesses. Prior to purchasing services or goods, customers first review the online comments submitted by previous customers. However, it is possible to superficially boost or hinder some businesses through posting counterfeit and fake reviews. This paper explores a natural language processing approach to identify fake reviews. We present a detailed analysis of linguistic features for distinguishing fake and trustworthy online reviews. We study 15 linguistic features and measure their significance and importance towards the classification schemes employed in this study. Our results indicate that fake reviews tend to include more redundant terms and pauses, and generally contain longer sentences. The application of several machine learning classification algorithms revealed that we were able to discriminate fake from real reviews with high accuracy using these linguistic features.
Fast Fourier Transformation for Optimizing Convolutional Neural Networks in Object Recognition
Oct 08, 2020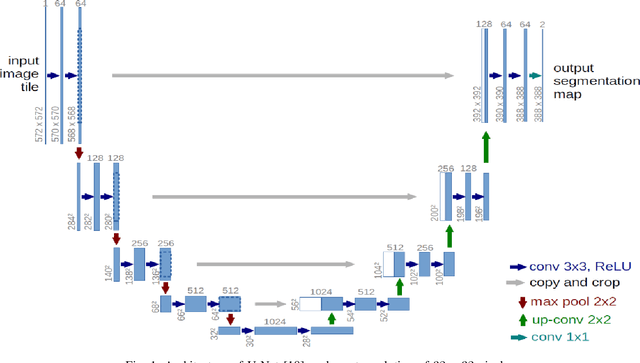
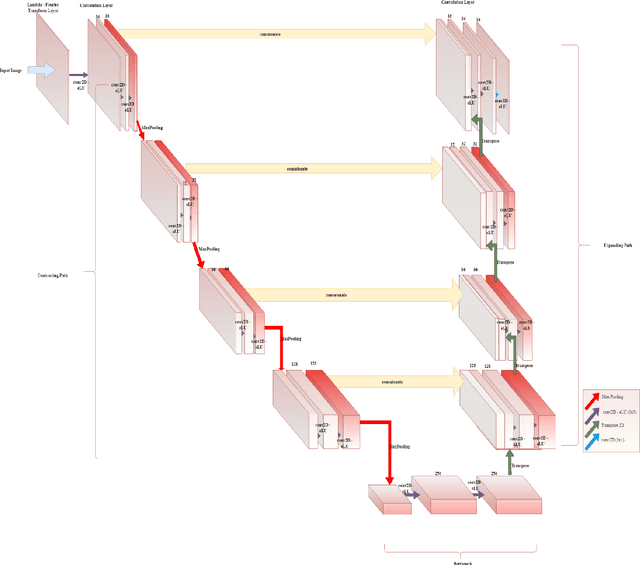
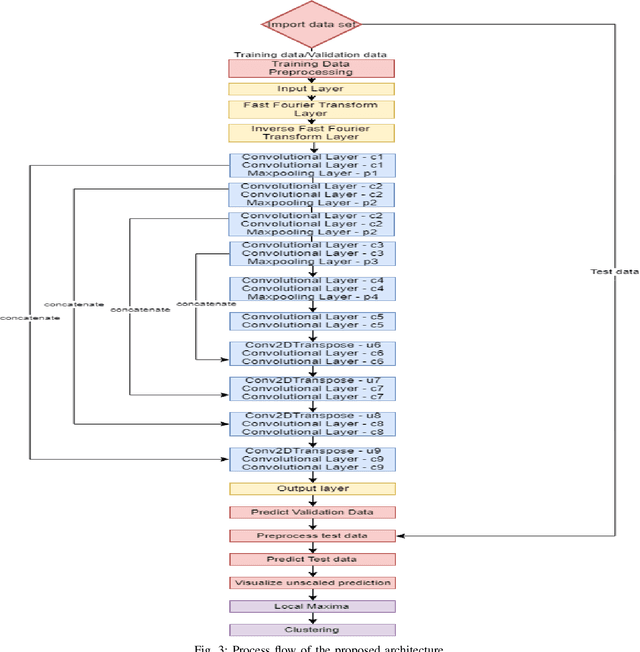

This paper proposes to use Fast Fourier Transformation-based U-Net (a refined fully convolutional networks) and perform image convolution in neural networks. Leveraging the Fast Fourier Transformation, it reduces the image convolution costs involved in the Convolutional Neural Networks (CNNs) and thus reduces the overall computational costs. The proposed model identifies the object information from the images. We apply the Fast Fourier transform algorithm on an image data set to obtain more accessible information about the image data, before segmenting them through the U-Net architecture. More specifically, we implement the FFT-based convolutional neural network to improve the training time of the network. The proposed approach was applied to publicly available Broad Bioimage Benchmark Collection (BBBC) dataset. Our model demonstrated improvement in training time during convolution from $600-700$ ms/step to $400-500$ ms/step. We evaluated the accuracy of our model using Intersection over Union (IoU) metric showing significant improvements.