 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlocksecRT-DETR: Decentralized Privacy-Preserving and Token-Efficient Federated Transformer Learning for Secure Real-Time Object Detection in ITS
Jan 19, 2026Federated real-time object detection using transformers in Intelligent Transportation Systems (ITS) faces three major challenges: (1) missing-class non-IID data heterogeneity from geographically diverse traffic environments, (2) latency constraints on edge hardware for high-capacity transformer models, and (3) privacy and security risks from untrusted client updates and centralized aggregation. We propose BlockSecRT-DETR, a BLOCKchain-SECured Real-Time Object DEtection TRansformer framework for ITS that provides a decentralized, token-efficient, and privacy-preserving federated training solution using RT-DETR transformer, incorporating a blockchain-secured update validation mechanism for trustworthy aggregation. In this framework, challenges (1) and (2) are jointly addressed through a unified client-side design that integrates RT-DETR training with a Token Engineering Module (TEM). TEM prunes low-utility tokens, reducing encoder complexity and latency on edge hardware, while aggregated updates mitigate non-IID data heterogeneity across clients. To address challenge (3), BlockSecRT-DETR incorporates a decentralized blockchain-secured update validation mechanism that enables tamper-proof, privacy-preserving, and trust-free authenticated model aggregation without relying on a central server. We evaluated the proposed framework under a missing-class Non-IID partition of the KITTI dataset and conducted a blockchain case study to quantify security overhead. TEM improves inference latency by 17.2% and reduces encoder FLOPs by 47.8%, while maintaining global detection accuracy (89.20% mAP@0.5). The blockchain integration adds 400 ms per round, and the ledger size remains under 12 KB due to metadata-only on-chain storage.
SoK: Privacy-aware LLM in Healthcare: Threat Model, Privacy Techniques, Challenges and Recommendations
Jan 15, 2026Large Language Models (LLMs) are increasingly adopted in healthcare to support clinical decision-making, summarize electronic health records (EHRs), and enhance patient care. However, this integration introduces significant privacy and security challenges, driven by the sensitivity of clinical data and the high-stakes nature of medical workflows. These risks become even more pronounced across heterogeneous deployment environments, ranging from small on-premise hospital systems to regional health networks, each with unique resource limitations and regulatory demands. This Systematization of Knowledge (SoK) examines the evolving threat landscape across the three core LLM phases: Data preprocessing, Fine-tuning, and Inference within realistic healthcare settings. We present a detailed threat model that characterizes adversaries, capabilities, and attack surfaces at each phase, and we systematize how existing privacy-preserving techniques (PPTs) attempt to mitigate these vulnerabilities. While existing defenses show promise, our analysis identifies persistent limitations in securing sensitive clinical data across diverse operational tiers. We conclude with phase-aware recommendations and future research directions aimed at strengthening privacy guarantees for LLMs in regulated environments. This work provides a foundation for understanding the intersection of LLMs, threats, and privacy in healthcare, offering a roadmap toward more robust and clinically trustworthy AI systems.
Attack Prediction using Hidden Markov Model
Jun 03, 2021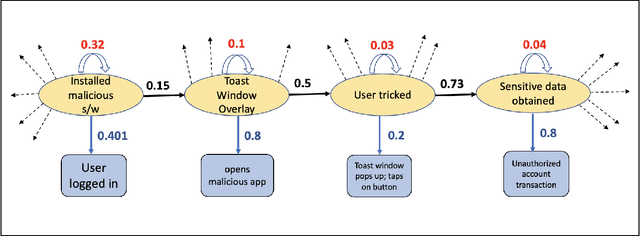


It is important to predict any adversarial attacks and their types to enable effective defense systems. Often it is hard to label such activities as malicious ones without adequate analytical reasoning. We propose the use of Hidden Markov Model (HMM) to predict the family of related attacks. Our proposed model is based on the observations often agglomerated in the form of log files and from the target or the victim's perspective. We have built an HMM-based prediction model and implemented our proposed approach using Viterbi algorithm, which generates a sequence of states corresponding to stages of a particular attack. As a proof of concept and also to demonstrate the performance of the model, we have conducted a case study on predicting a family of attacks called Action Spoofing.
Detection of Coincidentally Correct Test Cases through Random Forests
Jun 14, 2020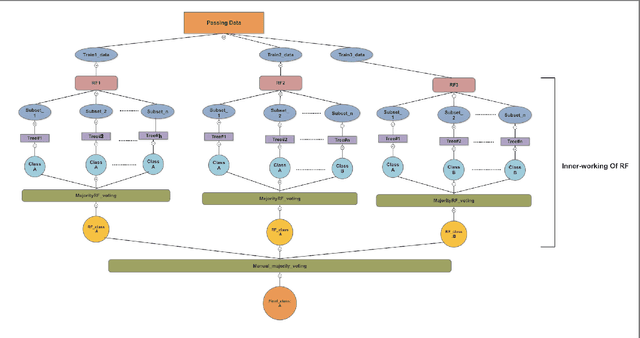

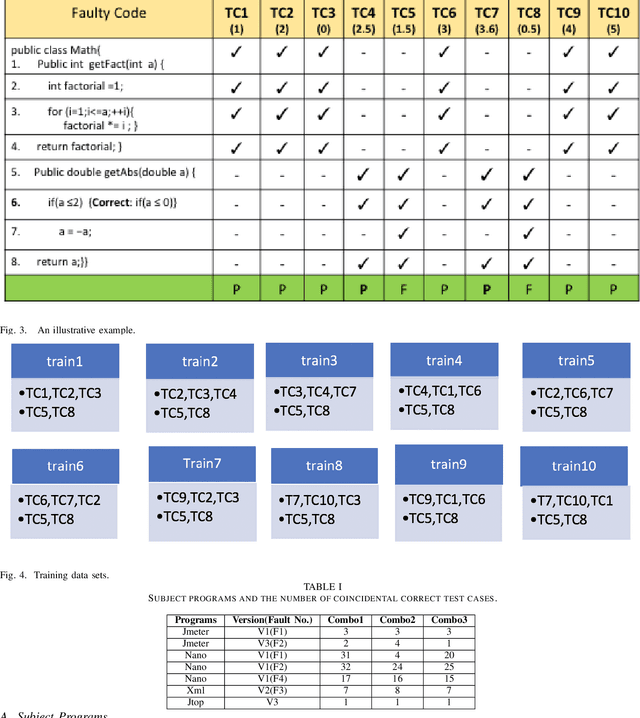
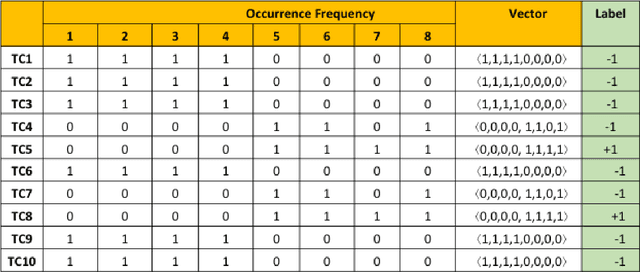
The performance of coverage-based fault localization greatly depends on the quality of test cases being executed. These test cases execute some lines of the given program and determine whether the underlying tests are passed or failed. In particular, some test cases may be well-behaved (i.e., passed) while executing faulty statements. These test cases, also known as coincidentally correct test cases, may negatively influence the performance of the spectra-based fault localization and thus be less helpful as a tool for the purpose of automated debugging. In other words, the involvement of these coincidentally correct test cases may introduce noises to the fault localization computation and thus cause in divergence of effectively localizing the location of possible bugs in the given code. In this paper, we propose a hybrid approach of ensemble learning combined with a supervised learning algorithm namely, Random Forests (RF) for the purpose of correctly identifying test cases that are mislabeled to be the passing test cases. A cost-effective analysis of flipping the test status or trimming (i.e., eliminating from the computation) the coincidental correct test cases is also reported.