 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context and Few-Shots Learning for Forecasting Time Series Data based on Large Language Models
Dec 08, 2025Existing data-driven approaches in modeling and predicting time series data include ARIMA (Autoregressive Integrated Moving Average), Transformer-based models, LSTM (Long Short-Term Memory) and TCN (Temporal Convolutional Network). These approaches, and in particular deep learning-based models such as LSTM and TCN, have shown great results in predicting time series data. With the advancement of leveraging pre-trained foundation models such as Large Language Models (LLMs) and more notably Google's recent foundation model for time series data, {\it TimesFM} (Time Series Foundation Model), it is of interest to investigate whether these foundation models have the capability of outperforming existing modeling approaches in analyzing and predicting time series data. This paper investigates the performance of using LLM models for time series data prediction. We investigate the in-context learning methodology in the training of LLM models that are specific to the underlying application domain. More specifically, the paper explores training LLMs through in-context, zero-shot and few-shot learning and forecasting time series data with OpenAI {\tt o4-mini} and Gemini 2.5 Flash Lite, as well as the recent Google's Transformer-based TimesFM, a time series-specific foundation model, along with two deep learning models, namely TCN and LSTM networks. The findings indicate that TimesFM has the best overall performance with the lowest RMSE value (0.3023) and the competitive inference time (266 seconds). Furthermore, OpenAI's o4-mini also exhibits a good performance based on Zero Shot learning. These findings highlight pre-trained time series foundation models as a promising direction for real-time forecasting, enabling accurate and scalable deployment with minimal model adaptation.
The Performance of the LSTM-based Code Generated by Large Language Models (LLMs) in Forecasting Time Series Data
Nov 27, 2024



As an intriguing case is the goodness of the machine and deep learning models generated by these LLMs in conducting automated scientific data analysis, where a data analyst may not have enough expertise in manually coding and optimizing complex deep learning models and codes and thus may opt to leverage LLMs to generate the required models. This paper investigates and compares the performance of the mainstream LLMs, such as ChatGPT, PaLM, LLama, and Falcon, in generating deep learning models for analyzing time series data, an important and popular data type with its prevalent applications in many application domains including financial and stock market. This research conducts a set of controlled experiments where the prompts for generating deep learning-based models are controlled with respect to sensitivity levels of four criteria including 1) Clarify and Specificity, 2) Objective and Intent, 3) Contextual Information, and 4) Format and Style. While the results are relatively mix, we observe some distinct patterns. We notice that using LLMs, we are able to generate deep learning-based models with executable codes for each dataset seperatly whose performance are comparable with the manually crafted and optimized LSTM models for predicting the whole time series dataset. We also noticed that ChatGPT outperforms the other LLMs in generating more accurate models. Furthermore, we observed that the goodness of the generated models vary with respect to the ``temperature'' parameter used in configuring LLMS. The results can be beneficial for data analysts and practitioners who would like to leverage generative AIs to produce good prediction models with acceptable goodness.
A Comparative Study of Detecting Anomalies in Time Series Data Using LSTM and TCN Models
Dec 17, 2021
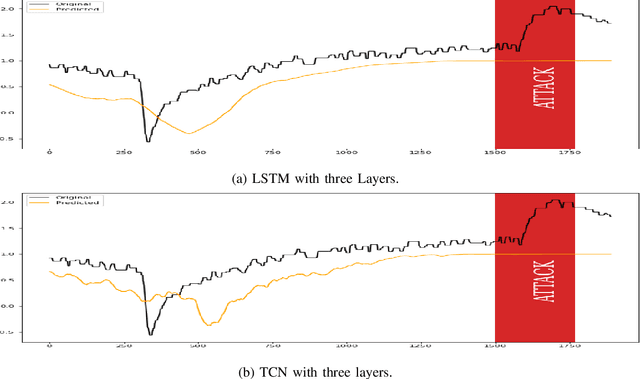
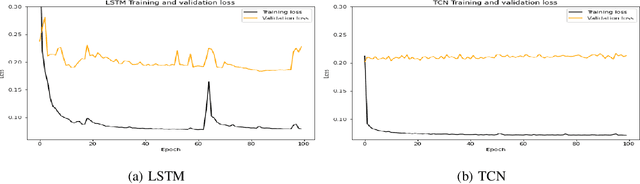
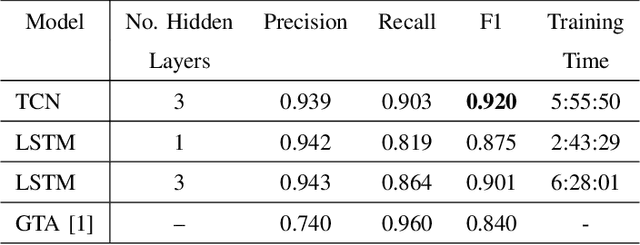
There exist several data-driven approaches that enable us model time series data including traditional regression-based modeling approaches (i.e., ARIMA). Recently, deep learning techniques have been introduced and explored in the context of time series analysis and prediction. A major research question to ask is the performance of these many variations of deep learning techniques in predicting time series data. This paper compares two prominent deep learning modeling techniques. The Recurrent Neural Network (RNN)-based Long Short-Term Memory (LSTM) and the convolutional Neural Network (CNN)-based Temporal Convolutional Networks (TCN) are compared and their performance and training time are reported. According to our experimental results, both modeling techniques perform comparably having TCN-based models outperform LSTM slightly. Moreover, the CNN-based TCN model builds a stable model faster than the RNN-based LSTM models.
Clustering Time Series Data through Autoencoder-based Deep Learning Models
Apr 11, 2020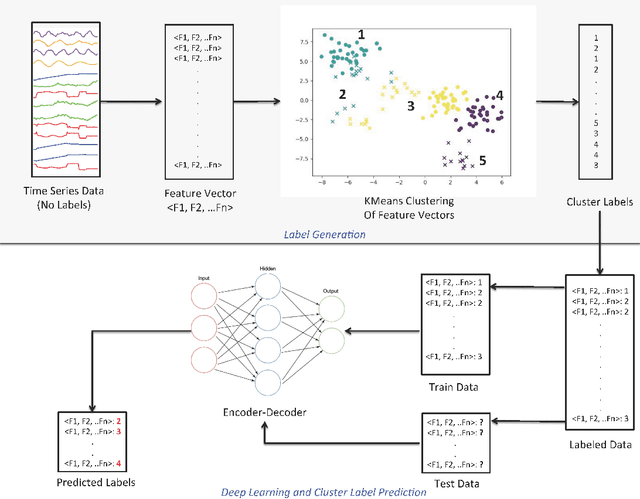
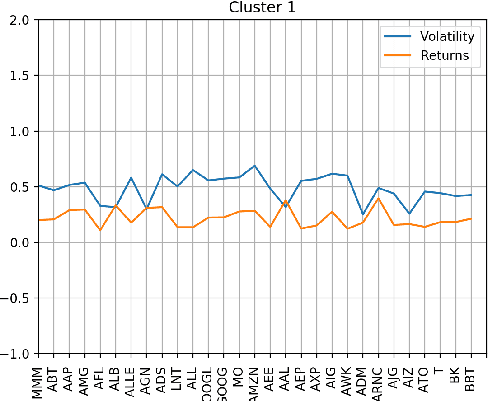
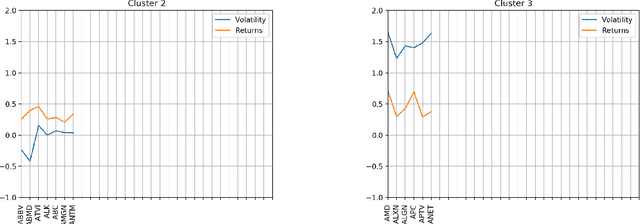
Machine learning and in particular deep learning algorithms are the emerging approaches to data analysis. These techniques have transformed traditional data mining-based analysis radically into a learning-based model in which existing data sets along with their cluster labels (i.e., train set) are learned to build a supervised learning model and predict the cluster labels of unseen data (i.e., test set). In particular, deep learning techniques are capable of capturing and learning hidden features in a given data sets and thus building a more accurate prediction model for clustering and labeling problem. However, the major problem is that time series data are often unlabeled and thus supervised learning-based deep learning algorithms cannot be directly adapted to solve the clustering problems for these special and complex types of data sets. To address this problem, this paper introduces a two-stage method for clustering time series data. First, a novel technique is introduced to utilize the characteristics (e.g., volatility) of given time series data in order to create labels and thus be able to transform the problem from unsupervised learning into supervised learning. Second, an autoencoder-based deep learning model is built to learn and model both known and hidden features of time series data along with their created labels to predict the labels of unseen time series data. The paper reports a case study in which financial and stock time series data of selected 70 stock indices are clustered into distinct groups using the introduced two-stage procedure. The results show that the proposed procedure is capable of achieving 87.5\% accuracy in clustering and predicting the labels for unseen time series data.
The Performance of Machine and Deep Learning Classifiers in Detecting Zero-Day Vulnerabilities
Nov 21, 2019


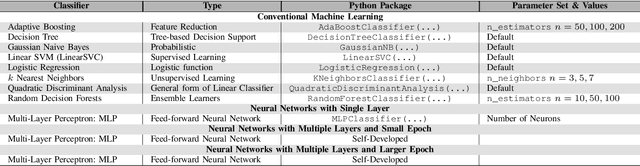
The detection of zero-day attacks and vulnerabilities is a challenging problem. It is of utmost importance for network administrators to identify them with high accuracy. The higher the accuracy is, the more robust the defense mechanism will be. In an ideal scenario (i.e., 100% accuracy) the system can detect zero-day malware without being concerned about mistakenly tagging benign files as malware or enabling disruptive malicious code running as none-malicious ones. This paper investigates different machine learning algorithms to find out how well they can detect zero-day malware. Through the examination of 34 machine/deep learning classifiers, we found that the random forest classifier offered the best accuracy. The paper poses several research questions regarding the performance of machine and deep learning algorithms when detecting zero-day malware with zero rates for false positive and false negative.
A Comparative Analysis of Forecasting Financial Time Series Using ARIMA, LSTM, and BiLSTM
Nov 21, 2019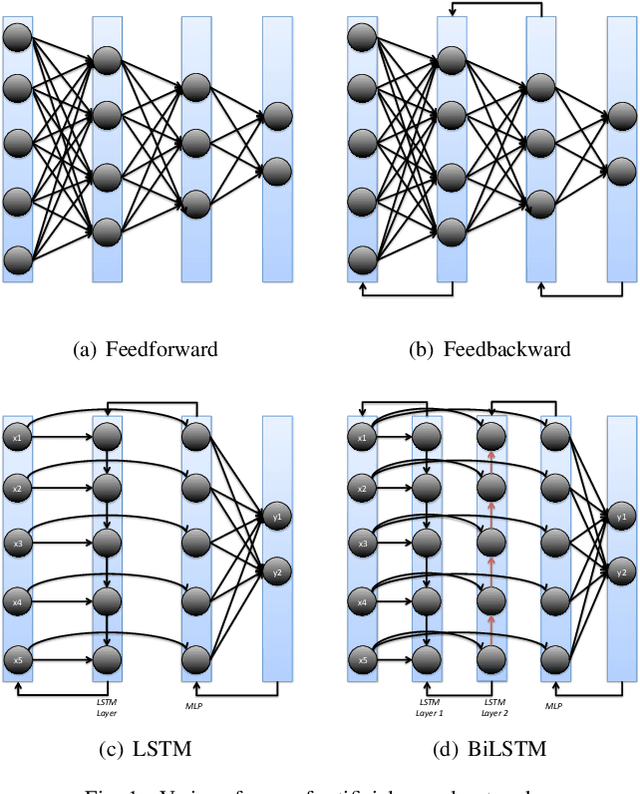
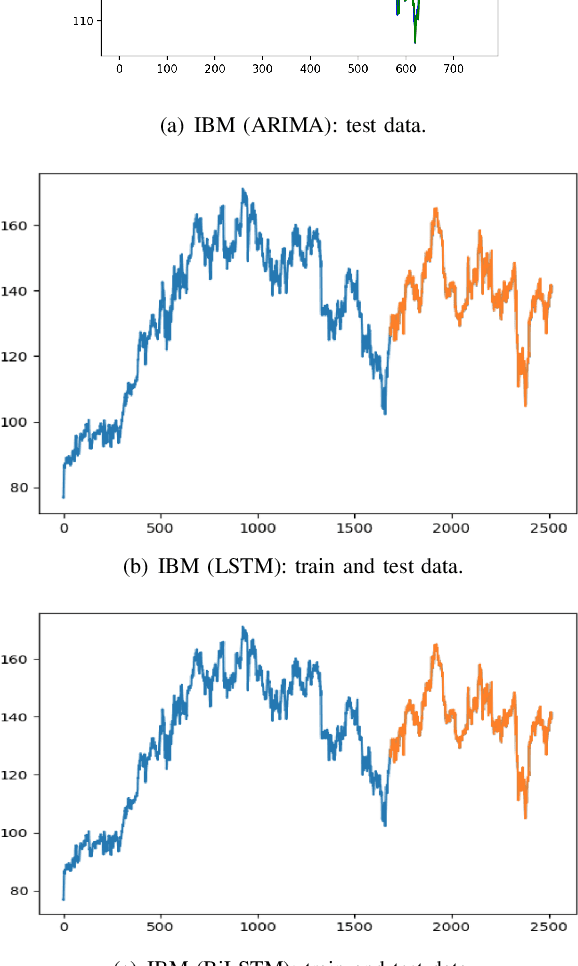
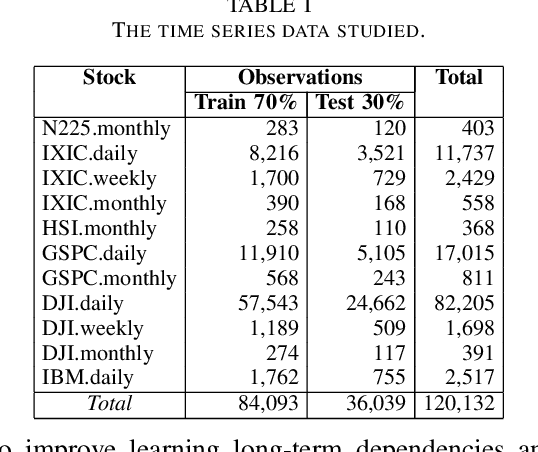
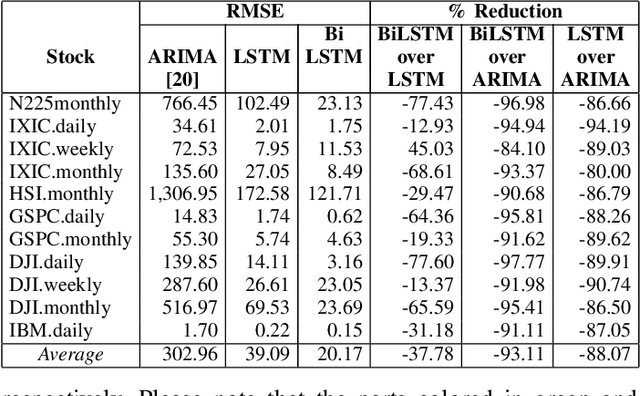
Machine and deep learning-based algorithms are the emerging approaches in addressing prediction problems in time series. These techniques have been shown to produce more accurate results than conventional regression-based modeling. It has been reported that artificial Recurrent Neural Networks (RNN) with memory, such as Long Short-Term Memory (LSTM), are superior compared to Autoregressive Integrated Moving Average (ARIMA) with a large margin. The LSTM-based models incorporate additional "gates" for the purpose of memorizing longer sequences of input data. The major question is that whether the gates incorporated in the LSTM architecture already offers a good prediction and whether additional training of data would be necessary to further improve the prediction. Bidirectional LSTMs (BiLSTMs) enable additional training by traversing the input data twice (i.e., 1) left-to-right, and 2) right-to-left). The research question of interest is then whether BiLSTM, with additional training capability, outperforms regular unidirectional LSTM. This paper reports a behavioral analysis and comparison of BiLSTM and LSTM models. The objective is to explore to what extend additional layers of training of data would be beneficial to tune the involved parameters. The results show that additional training of data and thus BiLSTM-based modeling offers better predictions than regular LSTM-based models. More specifically, it was observed that BiLSTM models provide better predictions compared to ARIMA and LSTM models. It was also observed that BiLSTM models reach the equilibrium much slower than LSTM-based models.
Forecasting Economics and Financial Time Series: ARIMA vs. LSTM
Mar 16, 2018
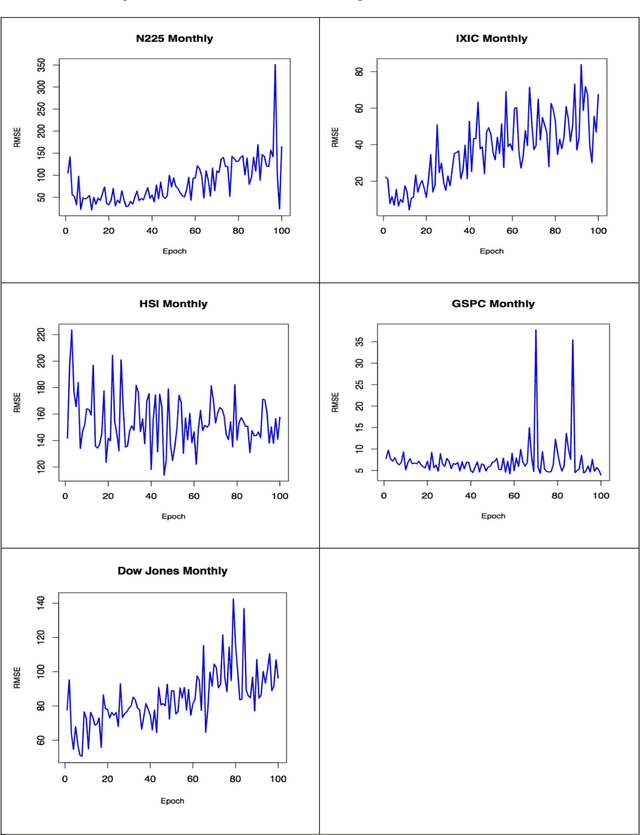

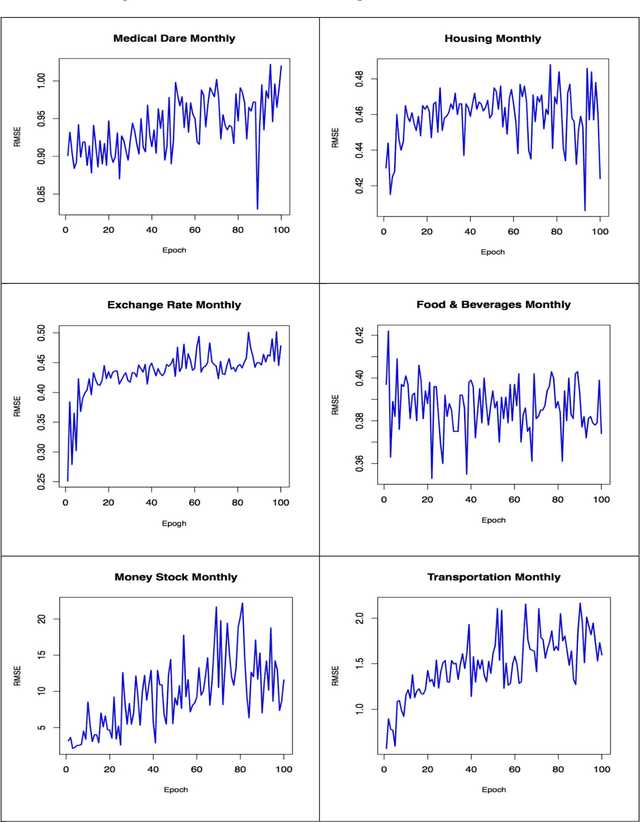
Forecasting time series data is an important subject in economics, business, and finance. Traditionally, there are several techniques to effectively forecast the next lag of time series data such as univariate Autoregressive (AR), univariate Moving Average (MA), Simple Exponential Smoothing (SES), and more notably Autoregressive Integrated Moving Average (ARIMA) with its many variations. In particular, ARIMA model has demonstrated its outperformance in precision and accuracy of predicting the next lags of time series. With the recent advancement in computational power of computers and more importantly developing more advanced machine learning algorithms and approaches such as deep learning, new algorithms are developed to forecast time series data. The research question investigated in this article is that whether and how the newly developed deep learning-based algorithms for forecasting time series data, such as "Long Short-Term Memory (LSTM)", are superior to the traditional algorithms. The empirical studies conducted and reported in this article show that deep learning-based algorithms such as LSTM outperform traditional-based algorithms such as ARIMA model. More specifically, the average reduction in error rates obtained by LSTM is between 84 - 87 percent when compared to ARIMA indicating the superiority of LSTM to ARIMA. Furthermore, it was noticed that the number of training times, known as "epoch" in deep learning, has no effect on the performance of the trained forecast model and it exhibits a truly random behavior.