Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention as a Perspective for Learning Tempo-invariant Audio Queries
Paper and Code
Sep 15, 2018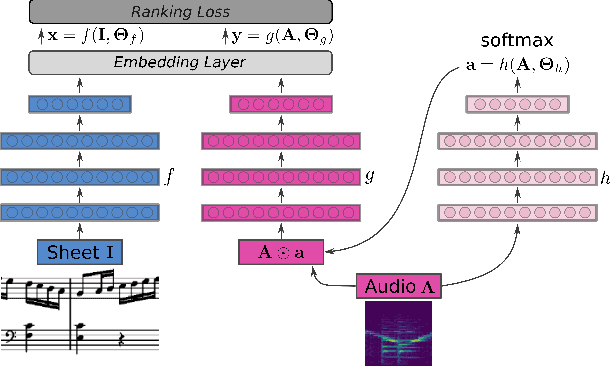


Current models for audio--sheet music retrieval via multimodal embedding space learning use convolutional neural networks with a fixed-size window for the input audio. Depending on the tempo of a query performance, this window captures more or less musical content, while notehead density in the score is largely tempo-independent. In this work we address this disparity with a soft attention mechanism, which allows the model to encode only those parts of an audio excerpt that are most relevant with respect to efficient query codes. Empirical results on classical piano music indicate that attention is beneficial for retrieval performance, and exhibits intuitively appealing behavior.
* The 2018 Joint Workshop on Machine Learning for Music
View paper on