 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRREDCoT: Segment-Level Reward Redistribution for Reasoning Models
Jun 04, 2026Recent advancements in reasoning language models have been driven by Reinforcement Learning (RL) fine-tuning. Most often, these rely on the Group Relative Policy Optimization (GRPO) algorithm or modifications thereof to steer the models to produce Chain-of-Thought (CoT) traces. The final answer can only be verified, and the reward assigned, after the CoT trace is complete, making it a delayed reward problem. GRPO and its modifications correspond to Monte Carlo methods in standard RL, which are known to suffer from high variance. A possible solution to this problem is the redistribution of rewards through credit assignment, where segments of the CoT trace that are important for arriving at the desirable solution are emphasized by assigning a higher reward. While Monte Carlo sampling can be used to provide an unbiased estimate of intermediate state values, its computational overhead makes it unsuitable for train-time credit assignment in long contexts at high granularity. We introduce RREDCoT (Reward REDistribution for Chain of Thoughts), which utilizes the model itself to approximate the optimal reward redistribution without additional generation. We investigate the advantages of our method compared to MC sampling and several attribution methods. We further analyze several aspects relevant to the construction of the redistribution such as segmentation of CoT traces and state value estimation.
Overcoming Forgetting in LLM Fine-Tuning with Evolution Strategies
May 28, 2026Evolution Strategies (ES) has recently emerged as a competitive alternative to reinforcement learning (RL) for large language model (LLM) fine-tuning, offering advantages through simplicity, scalability, and inference-only training. However, recent work suggests that ES fine-tuning on new tasks may induce forgetting of prior tasks. First, this paper shows that prior task forgetting (1) is better characterized as performance drift rather than irreversible forgetting, with prior-task performance often recovering during ES training; and (2) is not a specific failure mode of ES, but can also arise for fine-tuning with RL methods. Second, it analyzes when and why such drift arises, highlighting its dependence on ES training dynamics, particularly random walk behavior in weakly constrained directions of the weight space. Third, based on these insights, it introduces Anchored Weight Decay (AWD) as a parameter-space regularization technique that constrains optimization toward the initial model parameters. AWD effectively stabilizes prior-task performance while preserving target-task performance, achieving benefits comparable to large ES population sizes at much lower computational cost. Thus, contrary to previous beliefs, the paper shows that prior-task forgetting under ES is largely avoidable, positioning ES as a promising approach for continual learning in LLMs.
Efficient Pre-Training of LLMs through Truncated SVD Layers
May 27, 2026The massive scaling of Large Language Models (LLMs) has made pretraining increasingly cost-prohibitive. While low-rank representation and orthonormal weight matrices could in principle reduce parameter counts and computational overhead, most existing methods rely on static rank selection and do not enforce weight orthonormality due to high computational cost. This paper introduces TSVD, a framework that maintains low rank and strict orthonormality throughout the training process. It utilizes a spectral energy-based heuristic for adaptive rank selection, and a caching mechanisms to maintain orthonormality. Theoretical analysis justifies the advantage of the approach in pretraining dynamics and experiments across various model scales demonstrate that it is effective empirically. TSVD matches or exceeds the performance of full-parameter baselines while significantly reducing compute requirements. The approach thus offers a well-founded, practical, and scalable path toward efficient high-performance LLM pretraining.
Addressing Pitfalls in the Evaluation of Uncertainty Estimation Methods for Natural Language Generation
Oct 02, 2025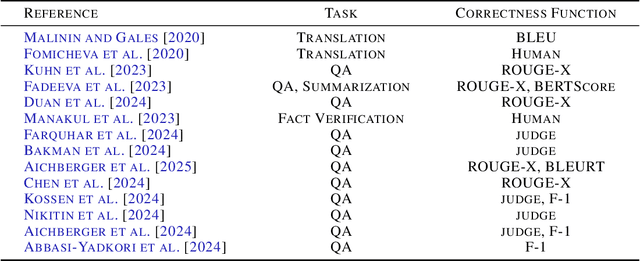
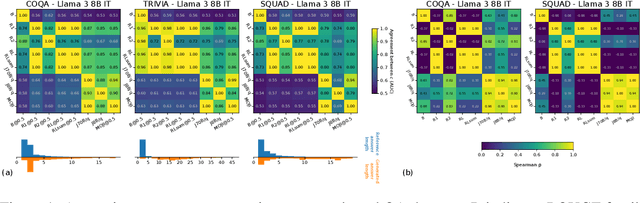
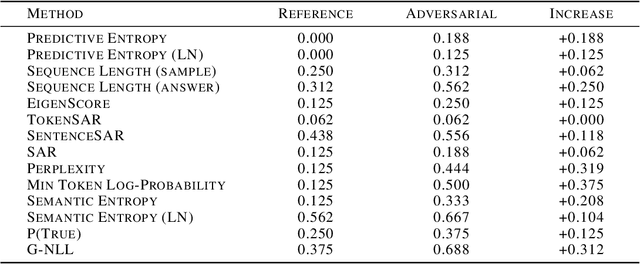
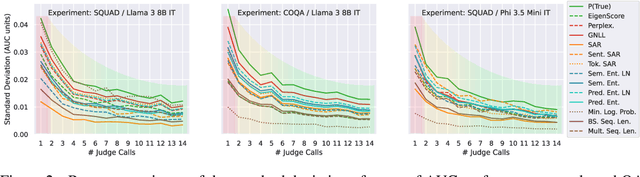
Hallucinations are a common issue that undermine the reliability of large language models (LLMs). Recent studies have identified a specific subset of hallucinations, known as confabulations, which arise due to predictive uncertainty of LLMs. To detect confabulations, various methods for estimating predictive uncertainty in natural language generation (NLG) have been developed. These methods are typically evaluated by correlating uncertainty estimates with the correctness of generated text, with question-answering (QA) datasets serving as the standard benchmark. However, commonly used approximate correctness functions have substantial disagreement between each other and, consequently, in the ranking of the uncertainty estimation methods. This allows one to inflate the apparent performance of uncertainty estimation methods. We propose using several alternative risk indicators for risk correlation experiments that improve robustness of empirical assessment of UE algorithms for NLG. For QA tasks, we show that marginalizing over multiple LLM-as-a-judge variants leads to reducing the evaluation biases. Furthermore, we explore structured tasks as well as out of distribution and perturbation detection tasks which provide robust and controllable risk indicators. Finally, we propose to use an Elo rating of uncertainty estimation methods to give an objective summarization over extensive evaluation settings.
xLSTM Scaling Laws: Competitive Performance with Linear Time-Complexity
Oct 02, 2025Scaling laws play a central role in the success of Large Language Models (LLMs), enabling the prediction of model performance relative to compute budgets prior to training. While Transformers have been the dominant architecture, recent alternatives such as xLSTM offer linear complexity with respect to context length while remaining competitive in the billion-parameter regime. We conduct a comparative investigation on the scaling behavior of Transformers and xLSTM along the following lines, providing insights to guide future model design and deployment. First, we study the scaling behavior for xLSTM in compute-optimal and over-training regimes using both IsoFLOP and parametric fit approaches on a wide range of model sizes (80M-7B) and number of training tokens (2B-2T). Second, we examine the dependence of optimal model sizes on context length, a pivotal aspect that was largely ignored in previous work. Finally, we analyze inference-time scaling characteristics. Our findings reveal that in typical LLM training and inference scenarios, xLSTM scales favorably compared to Transformers. Importantly, xLSTM's advantage widens as training and inference contexts grow.
Uncertainty Quantification for Regression using Proper Scoring Rules
Sep 30, 2025
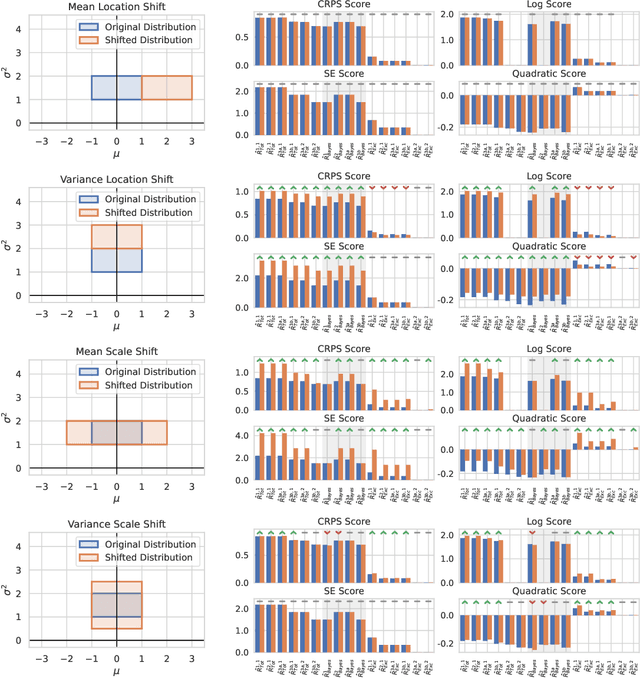


Quantifying uncertainty of machine learning model predictions is essential for reliable decision-making, especially in safety-critical applications. Recently, uncertainty quantification (UQ) theory has advanced significantly, building on a firm basis of learning with proper scoring rules. However, these advances were focused on classification, while extending these ideas to regression remains challenging. In this work, we introduce a unified UQ framework for regression based on proper scoring rules, such as CRPS, logarithmic, squared error, and quadratic scores. We derive closed-form expressions for the resulting uncertainty measures under practical parametric assumptions and show how to estimate them using ensembles of models. In particular, the derived uncertainty measures naturally decompose into aleatoric and epistemic components. The framework recovers popular regression UQ measures based on predictive variance and differential entropy. Our broad evaluation on synthetic and real-world regression datasets provides guidance for selecting reliable UQ measures.
ImageSet2Text: Describing Sets of Images through Text
Mar 25, 2025



We introduce ImageSet2Text, a novel approach that leverages vision-language foundation models to automatically create natural language descriptions of image sets. Inspired by concept bottleneck models (CBMs) and based on visual-question answering (VQA) chains, ImageSet2Text iteratively extracts key concepts from image subsets, encodes them into a structured graph, and refines insights using an external knowledge graph and CLIP-based validation. This iterative process enhances interpretability and enables accurate and detailed set-level summarization. Through extensive experiments, we evaluate ImageSet2Text's descriptions on accuracy, completeness, readability and overall quality, benchmarking it against existing vision-language models and introducing new datasets for large-scale group image captioning.
Rethinking Uncertainty Estimation in Natural Language Generation
Dec 19, 2024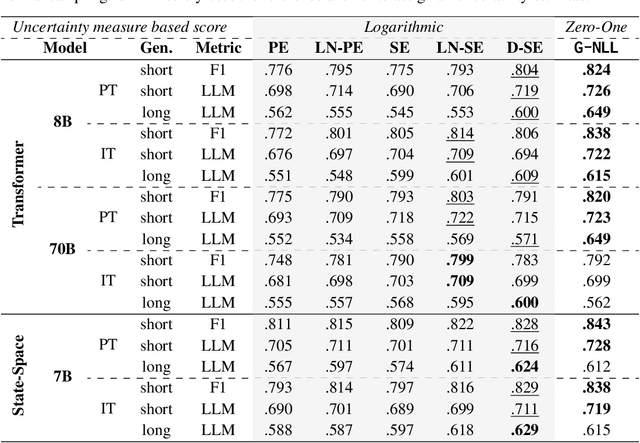
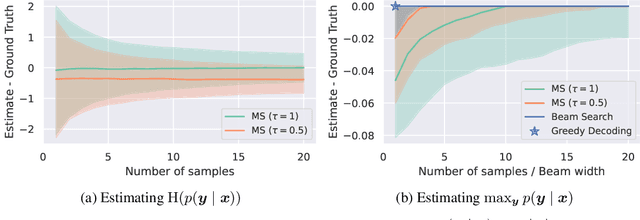
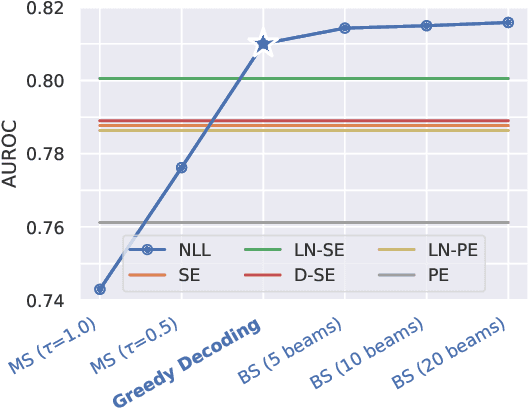
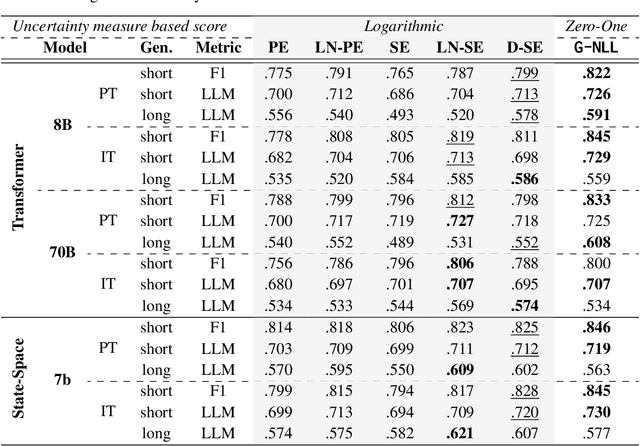
Large Language Models (LLMs) are increasingly employed in real-world applications, driving the need to evaluate the trustworthiness of their generated text. To this end, reliable uncertainty estimation is essential. Since current LLMs generate text autoregressively through a stochastic process, the same prompt can lead to varying outputs. Consequently, leading uncertainty estimation methods generate and analyze multiple output sequences to determine the LLM's uncertainty. However, generating output sequences is computationally expensive, making these methods impractical at scale. In this work, we inspect the theoretical foundations of the leading methods and explore new directions to enhance their computational efficiency. Building on the framework of proper scoring rules, we find that the negative log-likelihood of the most likely output sequence constitutes a theoretically grounded uncertainty measure. To approximate this alternative measure, we propose G-NLL, which has the advantage of being obtained using only a single output sequence generated by greedy decoding. This makes uncertainty estimation more efficient and straightforward, while preserving theoretical rigor. Empirical results demonstrate that G-NLL achieves state-of-the-art performance across various LLMs and tasks. Our work lays the foundation for efficient and reliable uncertainty estimation in natural language generation, challenging the necessity of more computationally involved methods currently leading the field.
The Disparate Benefits of Deep Ensembles
Oct 17, 2024



Ensembles of Deep Neural Networks, Deep Ensembles, are widely used as a simple way to boost predictive performance. However, their impact on algorithmic fairness is not well understood yet. Algorithmic fairness investigates how a model's performance varies across different groups, typically defined by protected attributes such as age, gender, or race. In this work, we investigate the interplay between the performance gains from Deep Ensembles and fairness. Our analysis reveals that they unevenly favor different groups in what we refer to as a disparate benefits effect. We empirically investigate this effect with Deep Ensembles applied to popular facial analysis and medical imaging datasets, where protected group attributes are given and find that it occurs for multiple established group fairness metrics, including statistical parity and equal opportunity. Furthermore, we identify the per-group difference in predictive diversity of ensemble members as the potential cause of the disparate benefits effect. Finally, we evaluate different approaches to reduce unfairness due to the disparate benefits effect. Our findings show that post-processing is an effective method to mitigate this unfairness while preserving the improved performance of Deep Ensembles.
On Information-Theoretic Measures of Predictive Uncertainty
Oct 14, 2024Reliable estimation of predictive uncertainty is crucial for machine learning applications, particularly in high-stakes scenarios where hedging against risks is essential. Despite its significance, a consensus on the correct measurement of predictive uncertainty remains elusive. In this work, we return to first principles to develop a fundamental framework of information-theoretic predictive uncertainty measures. Our proposed framework categorizes predictive uncertainty measures according to two factors: (I) The predicting model (II) The approximation of the true predictive distribution. Examining all possible combinations of these two factors, we derive a set of predictive uncertainty measures that includes both known and newly introduced ones. We empirically evaluate these measures in typical uncertainty estimation settings, such as misclassification detection, selective prediction, and out-of-distribution detection. The results show that no single measure is universal, but the effectiveness depends on the specific setting. Thus, our work provides clarity about the suitability of predictive uncertainty measures by clarifying their implicit assumptions and relationships.