 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImageSet2Text: Describing Sets of Images through Text
Mar 25, 2025



We introduce ImageSet2Text, a novel approach that leverages vision-language foundation models to automatically create natural language descriptions of image sets. Inspired by concept bottleneck models (CBMs) and based on visual-question answering (VQA) chains, ImageSet2Text iteratively extracts key concepts from image subsets, encodes them into a structured graph, and refines insights using an external knowledge graph and CLIP-based validation. This iterative process enhances interpretability and enables accurate and detailed set-level summarization. Through extensive experiments, we evaluate ImageSet2Text's descriptions on accuracy, completeness, readability and overall quality, benchmarking it against existing vision-language models and introducing new datasets for large-scale group image captioning.
Racial Bias in the Beautyverse
Sep 28, 2022
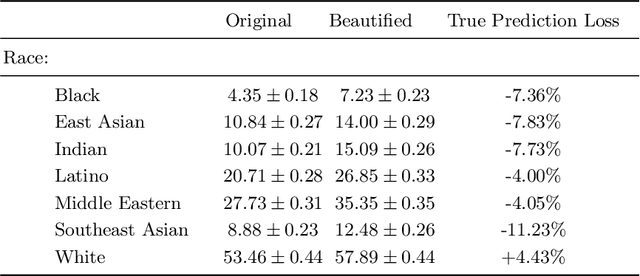


This short paper proposes a preliminary and yet insightful investigation of racial biases in beauty filters techniques currently used on social media. The obtained results are a call to action for researchers in Computer Vision: such biases risk being replicated and exaggerated in the Metaverse and, as a consequence, they deserve more attention from the community.
AI-based artistic representation of emotions from EEG signals: a discussion on fairness, inclusion, and aesthetics
Feb 07, 2022


While Artificial Intelligence (AI) technologies are being progressively developed, artists and researchers are investigating their role in artistic practices. In this work, we present an AI-based Brain-Computer Interface (BCI) in which humans and machines interact to express feelings artistically. This system and its production of images give opportunities to reflect on the complexities and range of human emotions and their expressions. In this discussion, we seek to understand the dynamics of this interaction to reach better co-existence in fairness, inclusion, and aesthetics.