 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMA-EgoQA: Question Answering over Egocentric Videos from Multiple Embodied Agents
Mar 11, 2026As embodied models become powerful, humans will collaborate with multiple embodied AI agents at their workplace or home in the future. To ensure better communication between human users and the multi-agent system, it is crucial to interpret incoming information from agents in parallel and refer to the appropriate context for each query. Existing challenges include effectively compressing and communicating high volumes of individual sensory inputs in the form of video and correctly aggregating multiple egocentric videos to construct system-level memory. In this work, we first formally define a novel problem of understanding multiple long-horizon egocentric videos simultaneously collected from embodied agents. To facilitate research in this direction, we introduce MultiAgent-EgoQA (MA-EgoQA), a benchmark designed to systemically evaluate existing models in our scenario. MA-EgoQA provides 1.7k questions unique to multiple egocentric streams, spanning five categories: social interaction, task coordination, theory-of-mind, temporal reasoning, and environmental interaction. We further propose a simple baseline model for MA-EgoQA named EgoMAS, which leverages shared memory across embodied agents and agent-wise dynamic retrieval. Through comprehensive evaluation across diverse baselines and EgoMAS on MA-EgoQA, we find that current approaches are unable to effectively handle multiple egocentric streams, highlighting the need for future advances in system-level understanding across the agents. The code and benchmark are available at https://ma-egoqa.github.io.
Memory Storyboard: Leveraging Temporal Segmentation for Streaming Self-Supervised Learning from Egocentric Videos
Jan 21, 2025



Self-supervised learning holds the promise to learn good representations from real-world continuous uncurated data streams. However, most existing works in visual self-supervised learning focus on static images or artificial data streams. Towards exploring a more realistic learning substrate, we investigate streaming self-supervised learning from long-form real-world egocentric video streams. Inspired by the event segmentation mechanism in human perception and memory, we propose "Memory Storyboard" that groups recent past frames into temporal segments for more effective summarization of the past visual streams for memory replay. To accommodate efficient temporal segmentation, we propose a two-tier memory hierarchy: the recent past is stored in a short-term memory, and the storyboard temporal segments are then transferred to a long-term memory. Experiments on real-world egocentric video datasets including SAYCam and KrishnaCam show that contrastive learning objectives on top of storyboard frames result in semantically meaningful representations which outperform those produced by state-of-the-art unsupervised continual learning methods.
Reawakening knowledge: Anticipatory recovery from catastrophic interference via structured training
Mar 14, 2024



We explore the training dynamics of neural networks in a structured non-IID setting where documents are presented cyclically in a fixed, repeated sequence. Typically, networks suffer from catastrophic interference when training on a sequence of documents; however, we discover a curious and remarkable property of LLMs fine-tuned sequentially in this setting: they exhibit anticipatory behavior, recovering from the forgetting on documents before encountering them again. The behavior emerges and becomes more robust as the architecture scales up its number of parameters. Through comprehensive experiments and visualizations, we uncover new insights into training over-parameterized networks in structured environments.
LifelongMemory: Leveraging LLMs for Answering Queries in Egocentric Videos
Dec 07, 2023



The egocentric video natural language query (NLQ) task involves localizing a temporal window in an egocentric video that provides an answer to a posed query, which has wide applications in building personalized AI assistants. Prior methods for this task have focused on improvements of network architecture and leveraging pre-training for enhanced image and video features, but have struggled with capturing long-range temporal dependencies in lengthy videos, and cumbersome end-to-end training. Motivated by recent advancements in Large Language Models (LLMs) and vision language models, we introduce LifelongMemory, a novel framework that utilizes multiple pre-trained models to answer queries from extensive egocentric video content. We address the unique challenge by employing a pre-trained captioning model to create detailed narratives of the videos. These narratives are then used to prompt a frozen LLM to generate coarse-grained temporal window predictions, which are subsequently refined using a pre-trained NLQ model. Empirical results demonstrate that our method achieves competitive performance against existing supervised end-to-end learning methods, underlining the potential of integrating multiple pre-trained multimodal large language models in complex vision-language tasks. We provide a comprehensive analysis of key design decisions and hyperparameters in our pipeline, offering insights and practical guidelines.
Pre-Training for Robots: Offline RL Enables Learning New Tasks from a Handful of Trials
Oct 11, 2022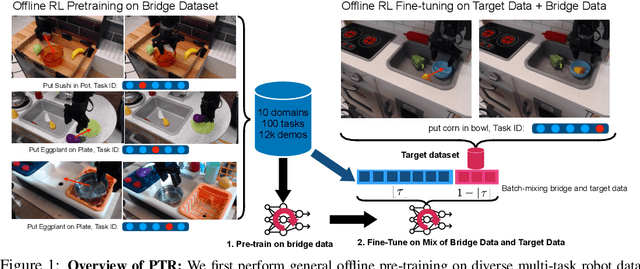

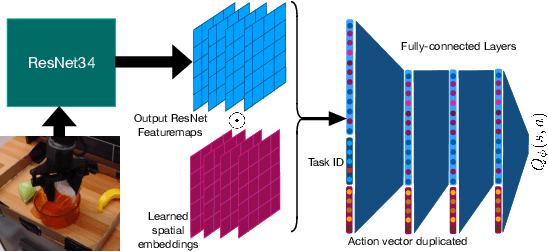

Recent progress in deep learning highlights the tremendous potential of utilizing diverse datasets for achieving effective generalization and makes it enticing to consider leveraging broad datasets for attaining more robust generalization in robotic learning as well. However, in practice we likely will want to learn a new skill in a new environment that is unlikely to be contained in the prior data. Therefore we ask: how can we leverage existing diverse offline datasets in combination with small amounts of task-specific data to solve new tasks, while still enjoying the generalization benefits of training on large amounts of data? In this paper, we demonstrate that end-to-end offline RL can be an effective approach for doing this, without the need for any representation learning or vision-based pre-training. We present pre-training for robots (PTR), a framework based on offline RL that attempts to effectively learn new tasks by combining pre-training on existing robotic datasets with rapid fine-tuning on a new task, with as a few as 10 demonstrations. At its core, PTR applies an existing offline RL method such as conservative Q-learning (CQL), but extends it to include several crucial design decisions that enable PTR to actually work and outperform a variety of prior methods. To the best of our knowledge, PTR is the first offline RL method that succeeds at learning new tasks in a new domain on a real WidowX robot with as few as 10 task demonstrations, by effectively leveraging an existing dataset of diverse multi-task robot data collected in a variety of toy kitchens. Our implementation can be found at: https://github.com/Asap7772/PTR.
Bridge Data: Boosting Generalization of Robotic Skills with Cross-Domain Datasets
Sep 27, 2021
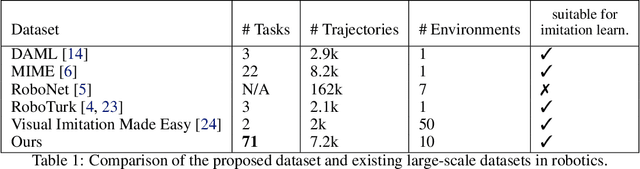

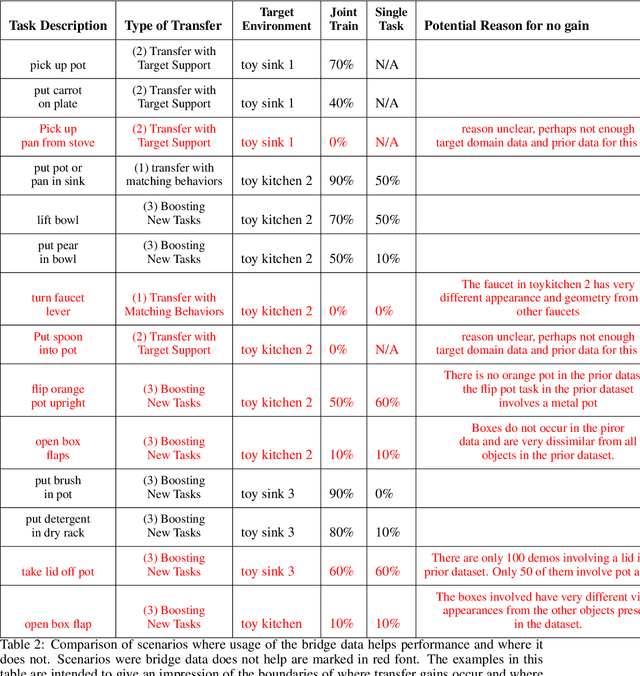
Robot learning holds the promise of learning policies that generalize broadly. However, such generalization requires sufficiently diverse datasets of the task of interest, which can be prohibitively expensive to collect. In other fields, such as computer vision, it is common to utilize shared, reusable datasets, such as ImageNet, to overcome this challenge, but this has proven difficult in robotics. In this paper, we ask: what would it take to enable practical data reuse in robotics for end-to-end skill learning? We hypothesize that the key is to use datasets with multiple tasks and multiple domains, such that a new user that wants to train their robot to perform a new task in a new domain can include this dataset in their training process and benefit from cross-task and cross-domain generalization. To evaluate this hypothesis, we collect a large multi-domain and multi-task dataset, with 7,200 demonstrations constituting 71 tasks across 10 environments, and empirically study how this data can improve the learning of new tasks in new environments. We find that jointly training with the proposed dataset and 50 demonstrations of a never-before-seen task in a new domain on average leads to a 2x improvement in success rate compared to using target domain data alone. We also find that data for only a few tasks in a new domain can bridge the domain gap and make it possible for a robot to perform a variety of prior tasks that were only seen in other domains. These results suggest that reusing diverse multi-task and multi-domain datasets, including our open-source dataset, may pave the way for broader robot generalization, eliminating the need to re-collect data for each new robot learning project.
Garbage In, Garbage Out? Do Machine Learning Application Papers in Social Computing Report Where Human-Labeled Training Data Comes From?
Dec 17, 2019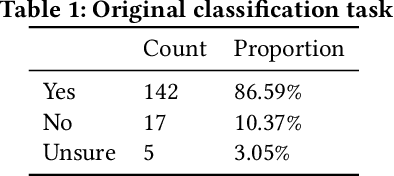
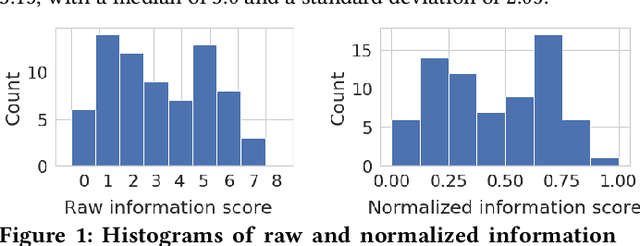
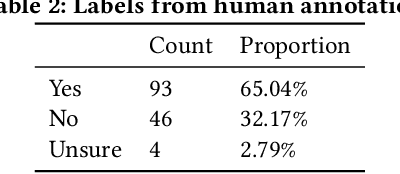
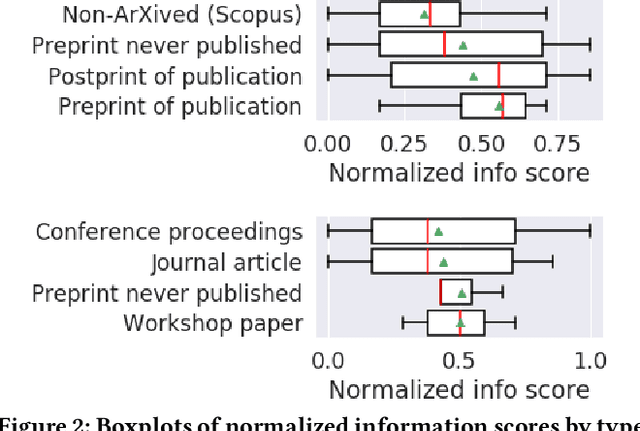
Many machine learning projects for new application areas involve teams of humans who label data for a particular purpose, from hiring crowdworkers to the paper's authors labeling the data themselves. Such a task is quite similar to (or a form of) structured content analysis, which is a longstanding methodology in the social sciences and humanities, with many established best practices. In this paper, we investigate to what extent a sample of machine learning application papers in social computing --- specifically papers from ArXiv and traditional publications performing an ML classification task on Twitter data --- give specific details about whether such best practices were followed. Our team conducted multiple rounds of structured content analysis of each paper, making determinations such as: Does the paper report who the labelers were, what their qualifications were, whether they independently labeled the same items, whether inter-rater reliability metrics were disclosed, what level of training and/or instructions were given to labelers, whether compensation for crowdworkers is disclosed, and if the training data is publicly available. We find a wide divergence in whether such practices were followed and documented. Much of machine learning research and education focuses on what is done once a "gold standard" of training data is available, but we discuss issues around the equally-important aspect of whether such data is reliable in the first place.
* 18 pages, includes appendix