 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGarbage In, Garbage Out? Do Machine Learning Application Papers in Social Computing Report Where Human-Labeled Training Data Comes From?
Dec 17, 2019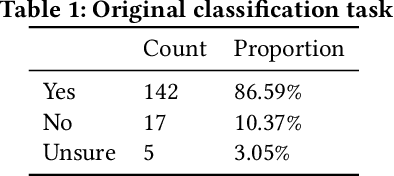
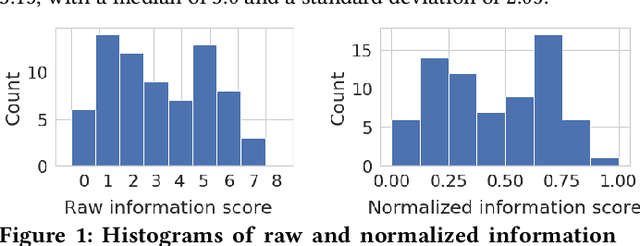
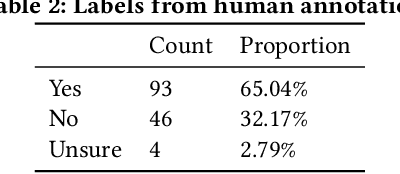
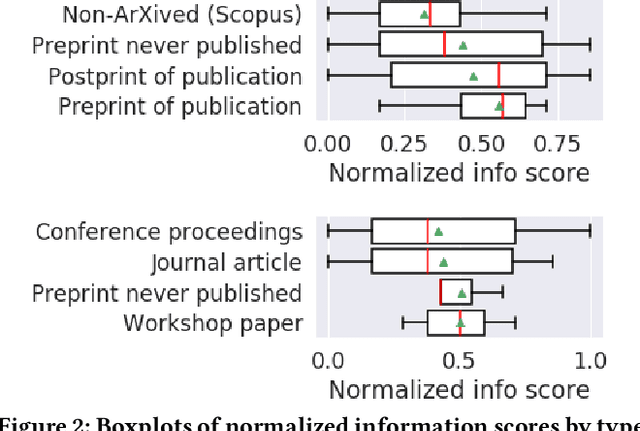
Many machine learning projects for new application areas involve teams of humans who label data for a particular purpose, from hiring crowdworkers to the paper's authors labeling the data themselves. Such a task is quite similar to (or a form of) structured content analysis, which is a longstanding methodology in the social sciences and humanities, with many established best practices. In this paper, we investigate to what extent a sample of machine learning application papers in social computing --- specifically papers from ArXiv and traditional publications performing an ML classification task on Twitter data --- give specific details about whether such best practices were followed. Our team conducted multiple rounds of structured content analysis of each paper, making determinations such as: Does the paper report who the labelers were, what their qualifications were, whether they independently labeled the same items, whether inter-rater reliability metrics were disclosed, what level of training and/or instructions were given to labelers, whether compensation for crowdworkers is disclosed, and if the training data is publicly available. We find a wide divergence in whether such practices were followed and documented. Much of machine learning research and education focuses on what is done once a "gold standard" of training data is available, but we discuss issues around the equally-important aspect of whether such data is reliable in the first place.
* 18 pages, includes appendix
Pose-Normalized Image Generation for Person Re-identification
Apr 25, 2018



Person Re-identification (re-id) faces two major challenges: the lack of cross-view paired training data and learning discriminative identity-sensitive and view-invariant features in the presence of large pose variations. In this work, we address both problems by proposing a novel deep person image generation model for synthesizing realistic person images conditional on the pose. The model is based on a generative adversarial network (GAN) designed specifically for pose normalization in re-id, thus termed pose-normalization GAN (PN-GAN). With the synthesized images, we can learn a new type of deep re-id feature free of the influence of pose variations. We show that this feature is strong on its own and complementary to features learned with the original images. Importantly, under the transfer learning setting, we show that our model generalizes well to any new re-id dataset without the need for collecting any training data for model fine-tuning. The model thus has the potential to make re-id model truly scalable.