 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Garbage In, Garbage Out" Revisited: What Do Machine Learning Application Papers Report About Human-Labeled Training Data?
Jul 05, 2021
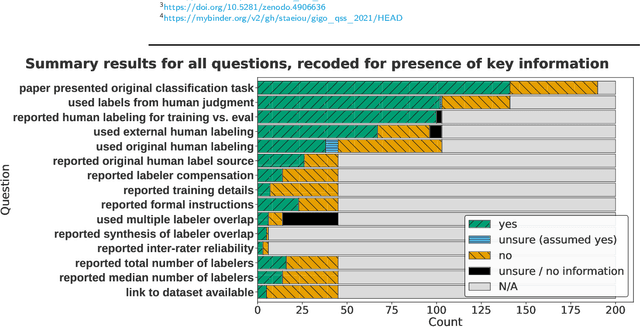
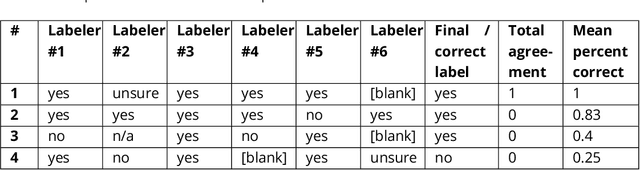
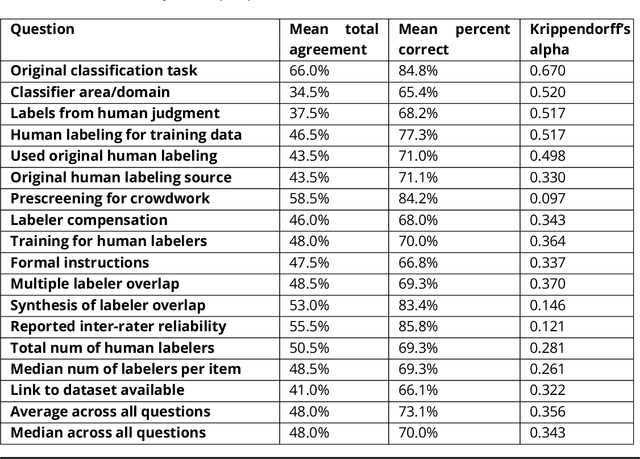
Supervised machine learning, in which models are automatically derived from labeled training data, is only as good as the quality of that data. This study builds on prior work that investigated to what extent 'best practices' around labeling training data were followed in applied ML publications within a single domain (social media platforms). In this paper, we expand by studying publications that apply supervised ML in a far broader spectrum of disciplines, focusing on human-labeled data. We report to what extent a random sample of ML application papers across disciplines give specific details about whether best practices were followed, while acknowledging that a greater range of application fields necessarily produces greater diversity of labeling and annotation methods. Because much of machine learning research and education only focuses on what is done once a "ground truth" or "gold standard" of training data is available, it is especially relevant to discuss issues around the equally-important aspect of whether such data is reliable in the first place. This determination becomes increasingly complex when applied to a variety of specialized fields, as labeling can range from a task requiring little-to-no background knowledge to one that must be performed by someone with career expertise.
Garbage In, Garbage Out? Do Machine Learning Application Papers in Social Computing Report Where Human-Labeled Training Data Comes From?
Dec 17, 2019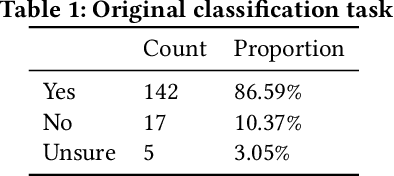
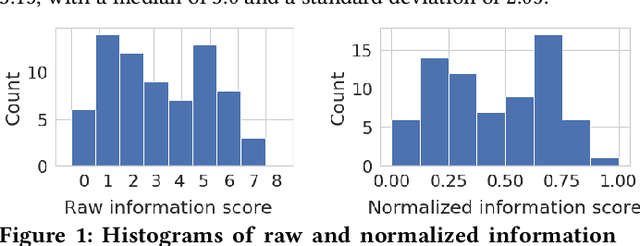
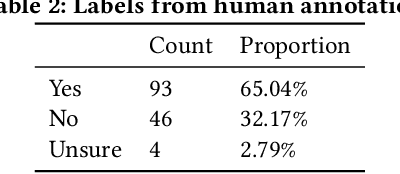
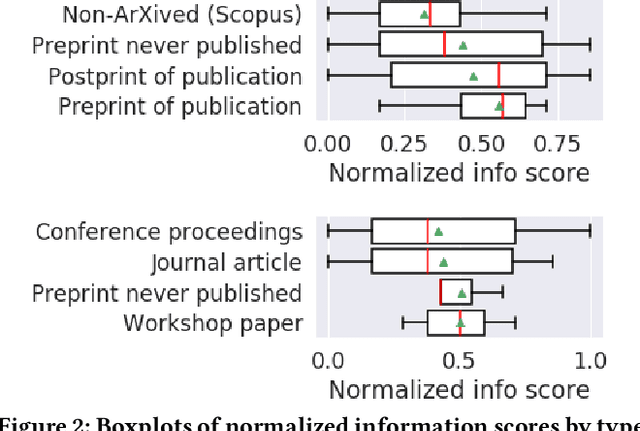
Many machine learning projects for new application areas involve teams of humans who label data for a particular purpose, from hiring crowdworkers to the paper's authors labeling the data themselves. Such a task is quite similar to (or a form of) structured content analysis, which is a longstanding methodology in the social sciences and humanities, with many established best practices. In this paper, we investigate to what extent a sample of machine learning application papers in social computing --- specifically papers from ArXiv and traditional publications performing an ML classification task on Twitter data --- give specific details about whether such best practices were followed. Our team conducted multiple rounds of structured content analysis of each paper, making determinations such as: Does the paper report who the labelers were, what their qualifications were, whether they independently labeled the same items, whether inter-rater reliability metrics were disclosed, what level of training and/or instructions were given to labelers, whether compensation for crowdworkers is disclosed, and if the training data is publicly available. We find a wide divergence in whether such practices were followed and documented. Much of machine learning research and education focuses on what is done once a "gold standard" of training data is available, but we discuss issues around the equally-important aspect of whether such data is reliable in the first place.
* 18 pages, includes appendix
ORES: Lowering Barriers with Participatory Machine Learning in Wikipedia
Sep 13, 2019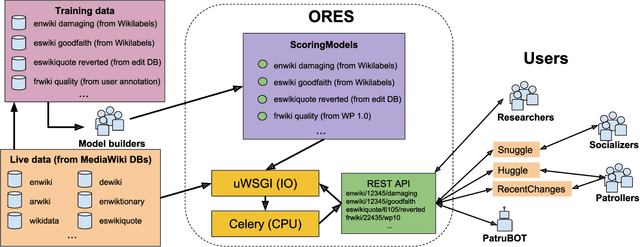
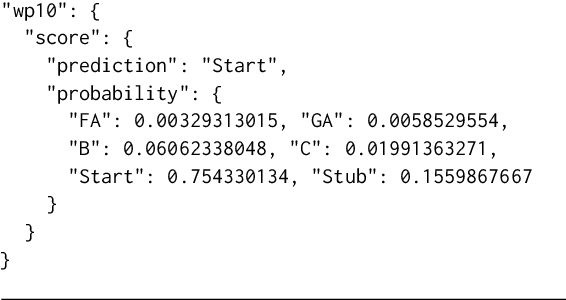


Algorithmic systems -- from rule-based bots to machine learning classifiers -- have a long history of supporting the essential work of content moderation and other curation work in peer production projects. From counter-vandalism to task routing, basic machine prediction has allowed open knowledge projects like Wikipedia to scale to the largest encyclopedia in the world, while maintaining quality and consistency. However, conversations about how quality control should work and what role algorithms should play have generally been led by the expert engineers who have the skills and resources to develop and modify these complex algorithmic systems. In this paper, we describe ORES: an algorithmic scoring service that supports real-time scoring of wiki edits using multiple independent classifiers trained on different datasets. ORES decouples several activities that have typically all been performed by engineers: choosing or curating training data, building models to serve predictions, auditing predictions, and developing interfaces or automated agents that act on those predictions. This meta-algorithmic system was designed to open up socio-technical conversations about algorithmic systems in Wikipedia to a broader set of participants. In this paper, we discuss the theoretical mechanisms of social change ORES enables and detail case studies in participatory machine learning around ORES from the 4 years since its deployment.
The Lives of Bots
Oct 22, 2018Automated software agents --- or bots --- have long been an important part of how Wikipedia's volunteer community of editors write, edit, update, monitor, and moderate content. In this paper, I discuss the complex social and technical environment in which Wikipedia's bots operate. This paper focuses on the establishment and role of English Wikipedia's bot policies and the Bot Approvals Group, a volunteer committee that reviews applications for new bots and helps resolve conflicts between Wikipedians about automation. In particular, I examine an early bot controversy over the first bot in Wikipedia to automatically enforce a social norm about how Wikipedian editors ought to interact in discussion spaces. As I show, bots enforce many rules in Wikipedia, but humans produce these bots and negotiate rules around their operation. Because of the openness of Wikipedia's processes around automation, we can vividly observe the often-invisible human work involved in such algorithmic systems --- in stark contrast to most other user-generated content platforms.
* Originally published in 2011
Beyond opening up the black box: Investigating the role of algorithmic systems in Wikipedian organizational culture
Oct 01, 2017Scholars and practitioners across domains are increasingly concerned with algorithmic transparency and opacity, interrogating the values and assumptions embedded in automated, black-boxed systems, particularly in user-generated content platforms. I report from an ethnography of infrastructure in Wikipedia to discuss an often understudied aspect of this topic: the local, contextual, learned expertise involved in participating in a highly automated social-technical environment. Today, the organizational culture of Wikipedia is deeply intertwined with various data-driven algorithmic systems, which Wikipedians rely on to help manage and govern the "anyone can edit" encyclopedia at a massive scale. These bots, scripts, tools, plugins, and dashboards make Wikipedia more efficient for those who know how to work with them, but like all organizational culture, newcomers must learn them if they want to fully participate. I illustrate how cultural and organizational expertise is enacted around algorithmic agents by discussing two autoethnographic vignettes, which relate my personal experience as a veteran in Wikipedia. I present thick descriptions of how governance and gatekeeping practices are articulated through and in alignment with these automated infrastructures. Over the past 15 years, Wikipedian veterans and administrators have made specific decisions to support administrative and editorial workflows with automation in particular ways and not others. I use these cases of Wikipedia's bot-supported bureaucracy to discuss several issues in the fields of critical algorithms studies, critical data studies, and fairness, accountability, and transparency in machine learning -- most principally arguing that scholarship and practice must go beyond trying to "open up the black box" of such systems and also examine sociocultural processes like newcomer socialization.
* 14 pages, typo fixed in v2