 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGarbage In, Garbage Out? Do Machine Learning Application Papers in Social Computing Report Where Human-Labeled Training Data Comes From?
Paper and Code
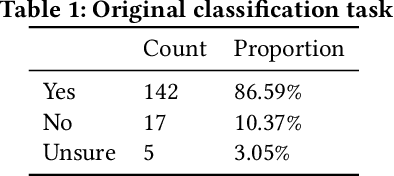
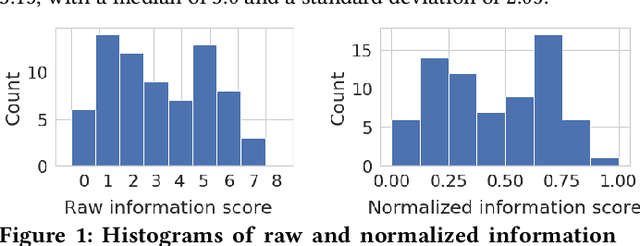
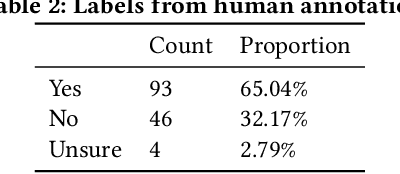
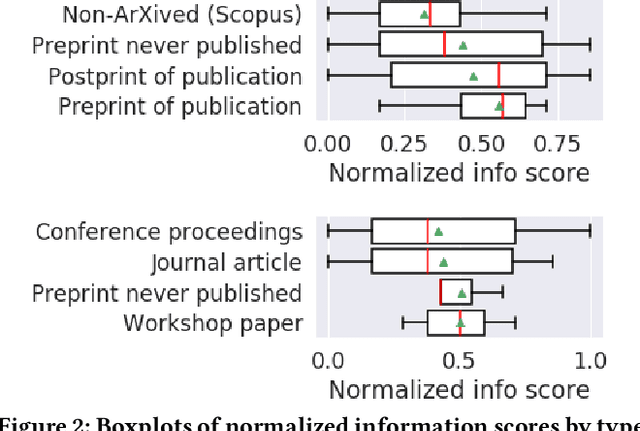
Many machine learning projects for new application areas involve teams of humans who label data for a particular purpose, from hiring crowdworkers to the paper's authors labeling the data themselves. Such a task is quite similar to (or a form of) structured content analysis, which is a longstanding methodology in the social sciences and humanities, with many established best practices. In this paper, we investigate to what extent a sample of machine learning application papers in social computing --- specifically papers from ArXiv and traditional publications performing an ML classification task on Twitter data --- give specific details about whether such best practices were followed. Our team conducted multiple rounds of structured content analysis of each paper, making determinations such as: Does the paper report who the labelers were, what their qualifications were, whether they independently labeled the same items, whether inter-rater reliability metrics were disclosed, what level of training and/or instructions were given to labelers, whether compensation for crowdworkers is disclosed, and if the training data is publicly available. We find a wide divergence in whether such practices were followed and documented. Much of machine learning research and education focuses on what is done once a "gold standard" of training data is available, but we discuss issues around the equally-important aspect of whether such data is reliable in the first place.