 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Garbage In, Garbage Out" Revisited: What Do Machine Learning Application Papers Report About Human-Labeled Training Data?
Jul 05, 2021
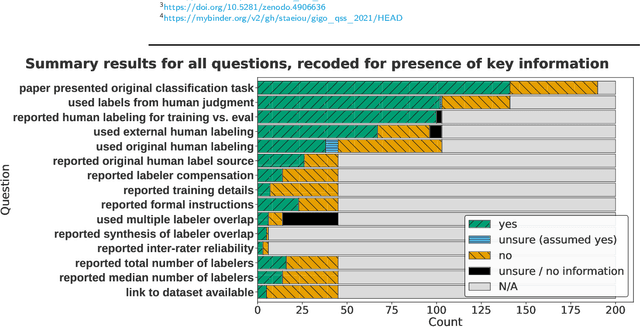
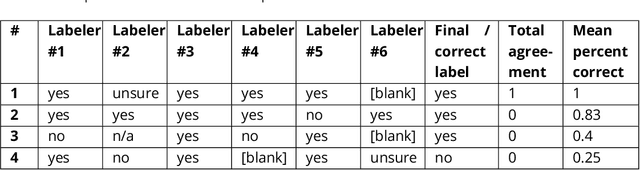
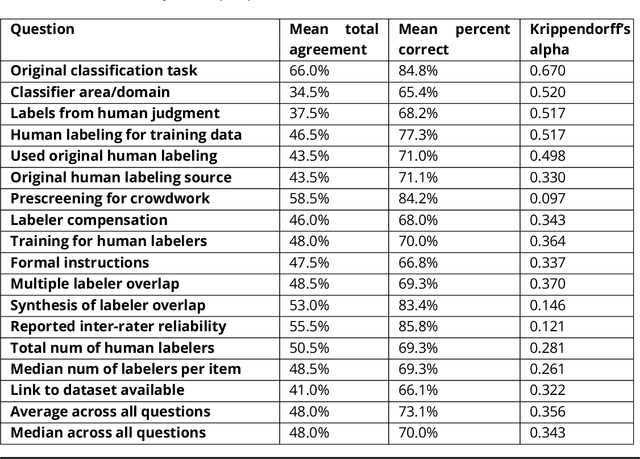
Supervised machine learning, in which models are automatically derived from labeled training data, is only as good as the quality of that data. This study builds on prior work that investigated to what extent 'best practices' around labeling training data were followed in applied ML publications within a single domain (social media platforms). In this paper, we expand by studying publications that apply supervised ML in a far broader spectrum of disciplines, focusing on human-labeled data. We report to what extent a random sample of ML application papers across disciplines give specific details about whether best practices were followed, while acknowledging that a greater range of application fields necessarily produces greater diversity of labeling and annotation methods. Because much of machine learning research and education only focuses on what is done once a "ground truth" or "gold standard" of training data is available, it is especially relevant to discuss issues around the equally-important aspect of whether such data is reliable in the first place. This determination becomes increasingly complex when applied to a variety of specialized fields, as labeling can range from a task requiring little-to-no background knowledge to one that must be performed by someone with career expertise.