 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy Efficient Protein Language Models: Leveraging Small Language Models with LoRA for Controllable Protein Generation
Nov 08, 2024


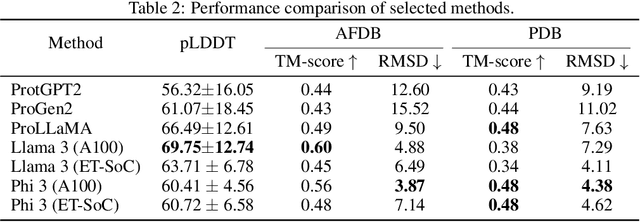
Large language models (LLMs) have demonstrated significant success in natural language processing (NLP) tasks and have shown promising results in other domains such as protein sequence generation. However, there remain salient differences between LLMs used for NLP, which effectively handle multiple tasks and are available in small sizes, and protein language models that are often specialized for specific tasks and only exist in larger sizes. In this work, we introduce two small protein language models, based on Llama-3-8B and Phi-3-mini, that are capable of both uncontrollable and controllable protein generation. For the uncontrollable generation task, our best model achieves an average pLDDT score of 69.75, demonstrating robust performance in generating viable protein structures. For the controllable generation task, in which the model generates proteins according to properties specified in the prompt, we achieve a remarkable average TM-Score of 0.84, indicating high structural similarity to target proteins. We chose 10 properties, including six classes of enzymes, to extend the capabilities of prior protein language models. Our approach utilizes the Low-Rank Adaptor (LoRA) technique, reducing trainable parameters to just 4% of the original model size, lowering computational requirements. By using a subset of the UniRef50 dataset and small models, we reduced the overall training time by 70% without compromising performance. Notably, Phi-3-mini reduced trainable parameters by 60%, decreasing training cost by 30% compared to Llama 3. Consequently, Phi-3 achieved a comparable TM-Score of 0.81, demonstrating that smaller models can match the performance of larger ones, like Llama 3. We also demonstrate the deployment of our models on the energy efficient ET-SoC-1 chip, significantly improving the TPS/W by a factor of 3.
Peptide-GPT: Generative Design of Peptides using Generative Pre-trained Transformers and Bio-informatic Supervision
Oct 25, 2024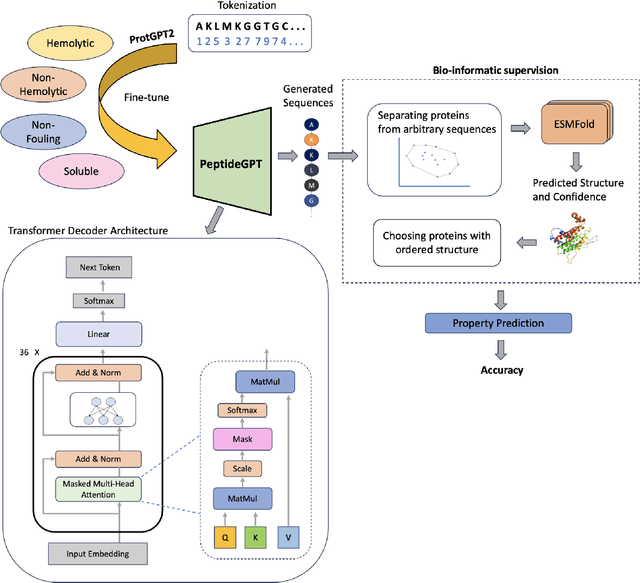


In recent years, natural language processing (NLP) models have demonstrated remarkable capabilities in various domains beyond traditional text generation. In this work, we introduce PeptideGPT, a protein language model tailored to generate protein sequences with distinct properties: hemolytic activity, solubility, and non-fouling characteristics. To facilitate a rigorous evaluation of these generated sequences, we established a comprehensive evaluation pipeline consisting of ideas from bioinformatics to retain valid proteins with ordered structures. First, we rank the generated sequences based on their perplexity scores, then we filter out those lying outside the permissible convex hull of proteins. Finally, we predict the structure using ESMFold and select the proteins with pLDDT values greater than 70 to ensure ordered structure. The properties of generated sequences are evaluated using task-specific classifiers - PeptideBERT and HAPPENN. We achieved an accuracy of 76.26% in hemolytic, 72.46% in non-hemolytic, 78.84% in non-fouling, and 68.06% in solubility protein generation. Our experimental results demonstrate the effectiveness of PeptideGPT in de novo protein design and underscore the potential of leveraging NLP-based approaches for paving the way for future innovations and breakthroughs in synthetic biology and bioinformatics. Codes, models, and data used in this study are freely available at: https://github.com/aayush-shah14/PeptideGPT.
Optimizing Multi-Domain Performance with Active Learning-based Improvement Strategies
Apr 13, 2023Improving performance in multiple domains is a challenging task, and often requires significant amounts of data to train and test models. Active learning techniques provide a promising solution by enabling models to select the most informative samples for labeling, thus reducing the amount of labeled data required to achieve high performance. In this paper, we present an active learning-based framework for improving performance across multiple domains. Our approach consists of two stages: first, we use an initial set of labeled data to train a base model, and then we iteratively select the most informative samples for labeling to refine the model. We evaluate our approach on several multi-domain datasets, including image classification, sentiment analysis, and object recognition. Our experiments demonstrate that our approach consistently outperforms baseline methods and achieves state-of-the-art performance on several datasets. We also show that our method is highly efficient, requiring significantly fewer labeled samples than other active learning-based methods. Overall, our approach provides a practical and effective solution for improving performance across multiple domains using active learning techniques.
Identifying Trades Using Technical Analysis and ML/DL Models
Apr 12, 2023The importance of predicting stock market prices cannot be overstated. It is a pivotal task for investors and financial institutions as it enables them to make informed investment decisions, manage risks, and ensure the stability of the financial system. Accurate stock market predictions can help investors maximize their returns and minimize their losses, while financial institutions can use this information to develop effective risk management policies. However, stock market prediction is a challenging task due to the complex nature of the stock market and the multitude of factors that can affect stock prices. As a result, advanced technologies such as deep learning are being increasingly utilized to analyze vast amounts of data and provide valuable insights into the behavior of the stock market. While deep learning has shown promise in accurately predicting stock prices, there is still much research to be done in this area.
* 14 pages, 9 figures, 5 tables
"Garbage In, Garbage Out" Revisited: What Do Machine Learning Application Papers Report About Human-Labeled Training Data?
Jul 05, 2021
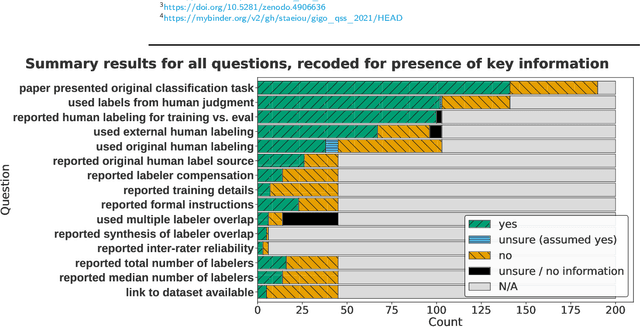
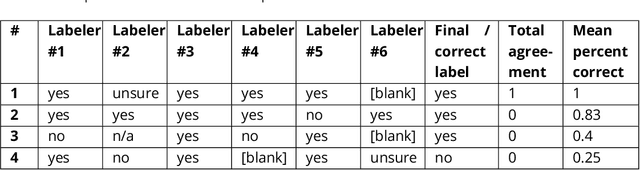
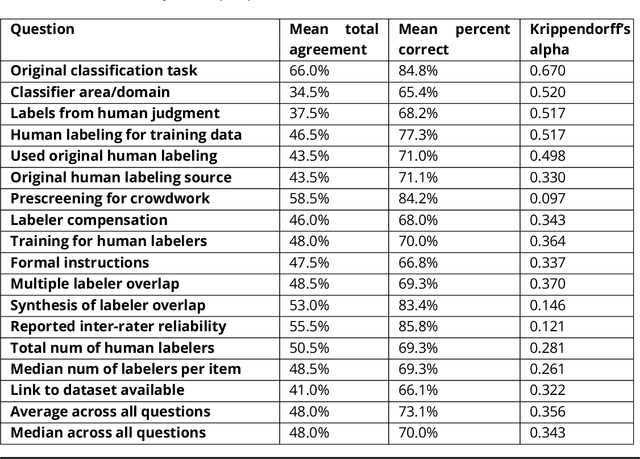
Supervised machine learning, in which models are automatically derived from labeled training data, is only as good as the quality of that data. This study builds on prior work that investigated to what extent 'best practices' around labeling training data were followed in applied ML publications within a single domain (social media platforms). In this paper, we expand by studying publications that apply supervised ML in a far broader spectrum of disciplines, focusing on human-labeled data. We report to what extent a random sample of ML application papers across disciplines give specific details about whether best practices were followed, while acknowledging that a greater range of application fields necessarily produces greater diversity of labeling and annotation methods. Because much of machine learning research and education only focuses on what is done once a "ground truth" or "gold standard" of training data is available, it is especially relevant to discuss issues around the equally-important aspect of whether such data is reliable in the first place. This determination becomes increasingly complex when applied to a variety of specialized fields, as labeling can range from a task requiring little-to-no background knowledge to one that must be performed by someone with career expertise.
Applied Machine Learning for Games: A Graduate School Course
Jan 01, 2021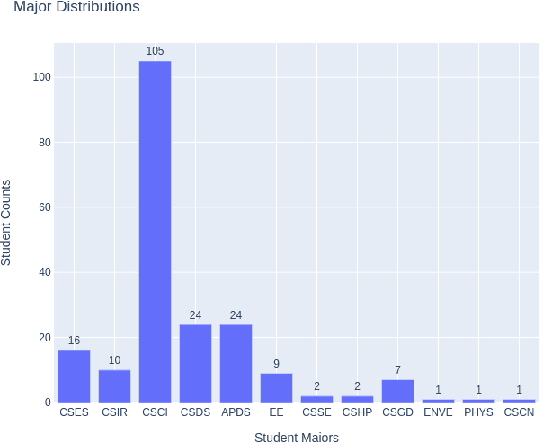

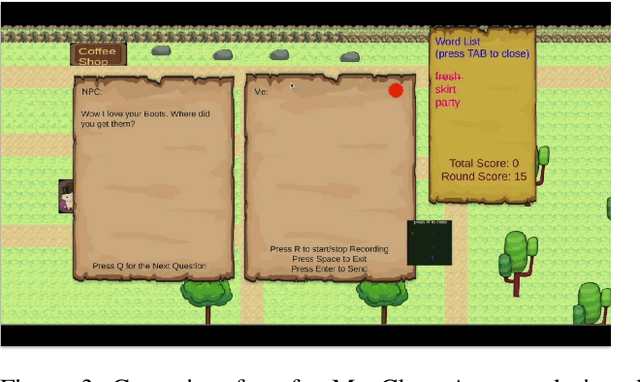
The game industry is moving into an era where old-style game engines are being replaced by re-engineered systems with embedded machine learning technologies for the operation, analysis and understanding of game play. In this paper, we describe our machine learning course designed for graduate students interested in applying recent advances of deep learning and reinforcement learning towards gaming. This course serves as a bridge to foster interdisciplinary collaboration among graduate schools and does not require prior experience designing or building games. Graduate students enrolled in this course apply different fields of machine learning techniques such as computer vision, natural language processing, computer graphics, human computer interaction, robotics and data analysis to solve open challenges in gaming. Student projects cover use-cases such as training AI-bots in gaming benchmark environments and competitions, understanding human decision patterns in gaming, and creating intelligent non-playable characters or environments to foster engaging gameplay. Projects demos can help students open doors for an industry career, aim for publications, or lay the foundations of a future product. Our students gained hands-on experience in applying state of the art machine learning techniques to solve real-life problems in gaming.