 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Trades Using Technical Analysis and ML/DL Models
Apr 12, 2023The importance of predicting stock market prices cannot be overstated. It is a pivotal task for investors and financial institutions as it enables them to make informed investment decisions, manage risks, and ensure the stability of the financial system. Accurate stock market predictions can help investors maximize their returns and minimize their losses, while financial institutions can use this information to develop effective risk management policies. However, stock market prediction is a challenging task due to the complex nature of the stock market and the multitude of factors that can affect stock prices. As a result, advanced technologies such as deep learning are being increasingly utilized to analyze vast amounts of data and provide valuable insights into the behavior of the stock market. While deep learning has shown promise in accurately predicting stock prices, there is still much research to be done in this area.
* 14 pages, 9 figures, 5 tables
Benchmarking datasets for Anomaly-based Network Intrusion Detection: KDD CUP 99 alternatives
Nov 13, 2018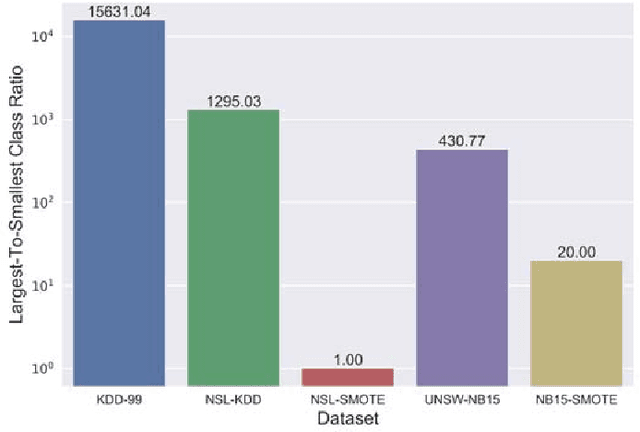
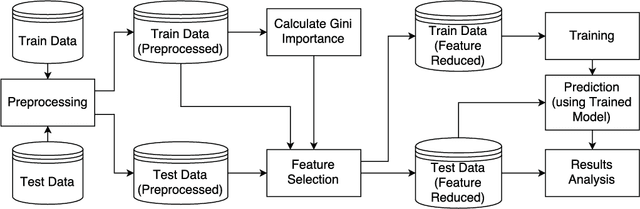
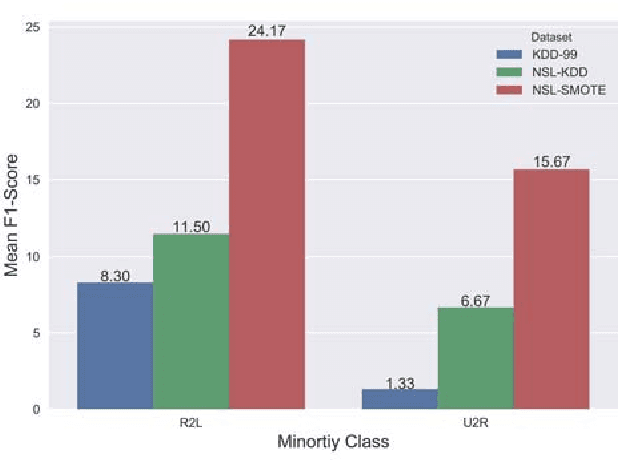
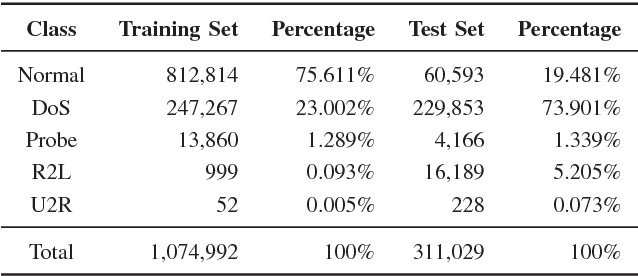
Machine Learning has been steadily gaining traction for its use in Anomaly-based Network Intrusion Detection Systems (A-NIDS). Research into this domain is frequently performed using the KDD~CUP~99 dataset as a benchmark. Several studies question its usability while constructing a contemporary NIDS, due to the skewed response distribution, non-stationarity, and failure to incorporate modern attacks. In this paper, we compare the performance for KDD-99 alternatives when trained using classification models commonly found in literature: Neural Network, Support Vector Machine, Decision Tree, Random Forest, Naive Bayes and K-Means. Applying the SMOTE oversampling technique and random undersampling, we create a balanced version of NSL-KDD and prove that skewed target classes in KDD-99 and NSL-KDD hamper the efficacy of classifiers on minority classes (U2R and R2L), leading to possible security risks. We explore UNSW-NB15, a modern substitute to KDD-99 with greater uniformity of pattern distribution. We benchmark this dataset before and after SMOTE oversampling to observe the effect on minority performance. Our results indicate that classifiers trained on UNSW-NB15 match or better the Weighted F1-Score of those trained on NSL-KDD and KDD-99 in the binary case, thus advocating UNSW-NB15 as a modern substitute to these datasets.