 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistically Reliable LLM-Based Ranking Evaluation via Prediction-Powered Inference
Jun 03, 2026With PRECISE, we extended Prediction-Powered Inference to produce bias-corrected estimates of ranking evaluation metrics by combining a small human-labeled set with a large LLM-judged set. PPI is provably unbiased regardless of the LLM judge's error profile. We make it applicable to hierarchical metrics like Precision@K, where annotations are per-document but the metric is per-query, by reducing the output-space computation from O(2^|C|) to O(2^K). On the ESCI benchmark, augmenting 30 human annotations with Claude 3 Sonnet judgments reduces the standard error of Precision@4 estimates from 4.45 to 3.50 (a 21% relative reduction). In a production system, our framework correctly identified the best of three system variants from 100 human labels and 2 hours of domain-expert annotation; A/B testing confirmed this ranking with +407 bps in daily sales.
VESTA: Visual Exploration with Statistical Tool Agents
May 29, 2026Fitting quantitative models to data is a central step in scientific workflows, yet it remains one of the least automated. Recent agent-based systems leverage language and vision-language models (VLMs) to iteratively propose and refine statistical models, but these systems struggle on more challenging modeling tasks. To address these limitations, we introduce VESTA: Visual Exploration with Statistical Tool Agents, a framework that equips VLMs with a dynamically growing exploration toolkit to guide model refinement through data transformations, hypothesis-driven visualizations, and robust statistical tests. Unlike prior systems that rely on iterative critique alone, VESTA actively explores data before and during refinement by selecting or creating diagnostic tools, which accumulate in the model's context and can be reused later. We evaluate VESTA against established baselines in three toolkit configurations: no tools, static expert-written tools, and dynamic model-written tools. To support this evaluation, we introduce DAWN (Dataset for Automated Workflows and Numerical Modeling), a benchmark targeting distribution fitting and time series modeling with varying difficulty tiers, and culminating in real-world astronomy tasks including modeling initial mass functions and gravitational-wave chirp signals. We find that VESTA's dynamic tool creation outperforms prior agentic pipelines, with the largest gains on complex and domain-specific tasks. We further show that dynamically generated tools are substantially more sophisticated than those produced by existing visual tool-creation systems, covering more diagnostic categories per function and strongly preferring visual outputs that the VLM critic can reason over directly.
When Gradients Collide: Failure Modes of Multi-Objective Prompt Optimization for LLM Judges
May 25, 2026Customizing an LLM judge to a specific task or domain often involves optimizing its prompt across multiple evaluation criteria simultaneously. Textual gradient methods automate this for a single judge criterion, however they produce natural-language critiques, not numerical vectors. Thus, the conflict-resolution toolkit of multi-task learning (PCGrad, MGDA) doesn't apply to the multi-objective textual gradient setting. We test five decomposition modes of textual gradient optimizers by varying how much cross-task information the loss, gradient and optimizer LLMs share. In 6 of 10 configurations, we observe that optimization never improves over the initial prompt. Gradient specificity drops by 59% (from 9.0 to 3.7) when the gradient LLM processes multiple criteria jointly. Separately, we observe that naively combining per-task instructions into a single prompt degrades Spearman's rho by -5.3%. These results identify two separable failure modes: optimization-time gradient dilution and inference-time instruction interference, which together constrain the design space for multi-objective judge customization using textual feedback.
PRECISE: Reducing the Bias of LLM Evaluations Using Prediction-Powered Ranking Estimation
Jan 26, 2026Evaluating the quality of search, ranking and RAG systems traditionally requires a significant number of human relevance annotations. In recent times, several deployed systems have explored the usage of Large Language Models (LLMs) as automated judges for this task while their inherent biases prevent direct use for metric estimation. We present a statistical framework extending Prediction-Powered Inference (PPI) that combines minimal human annotations with LLM judgments to produce reliable estimates of metrics which require sub-instance annotations. Our method requires as few as 100 human-annotated queries and 10,000 unlabeled examples, reducing annotation requirements significantly compared to traditional approaches. We formulate our proposed framework (PRECISE) for inference of relevance uplift for an LLM-based query reformulation application, extending PPI to sub-instance annotations at the query-document level. By reformulating the metric-integration space, we reduced the computational complexity from O(2^|C|) to O(2^K), where |C| represents corpus size (in order of millions). Detailed experiments across prominent retrieval datasets demonstrate that our method reduces the variance of estimates for the business-critical Precision@K metric, while effectively correcting for LLM bias in low-resource settings.
CorrSynth -- A Correlated Sampling Method for Diverse Dataset Generation from LLMs
Nov 13, 2024



Large language models (LLMs) have demonstrated remarkable performance in diverse tasks using zero-shot and few-shot prompting. Even though their capabilities of data synthesis have been studied well in recent years, the generated data suffers from a lack of diversity, less adherence to the prompt, and potential biases that creep into the data from the generator model. In this work, we tackle the challenge of generating datasets with high diversity, upon which a student model is trained for downstream tasks. Taking the route of decoding-time guidance-based approaches, we propose CorrSynth, which generates data that is more diverse and faithful to the input prompt using a correlated sampling strategy. Further, our method overcomes the complexity drawbacks of some other guidance-based techniques like classifier-based guidance. With extensive experiments, we show the effectiveness of our approach and substantiate our claims. In particular, we perform intrinsic evaluation to show the improvements in diversity. Our experiments show that CorrSynth improves both student metrics and intrinsic metrics upon competitive baselines across four datasets, showing the innate advantage of our method.
SynthesizRR: Generating Diverse Datasets with Retrieval Augmentation
May 16, 2024



Large language models (LLMs) are versatile and can address many tasks, but for computational efficiency, it is often desirable to distill their capabilities into smaller student models. One way to do this for classification tasks is via dataset synthesis, which can be accomplished by generating examples of each label from the LLM. Prior approaches to synthesis use few-shot prompting, which relies on the LLM's parametric knowledge to generate usable examples. However, this leads to issues of repetition, bias towards popular entities, and stylistic differences from human text. In this work, we propose Synthesize by Retrieval and Refinement (SynthesizRR), which uses retrieval augmentation to introduce variety into the dataset synthesis process: as retrieved passages vary, the LLM is "seeded" with different content to generate its examples. We empirically study the synthesis of six datasets, covering topic classification, sentiment analysis, tone detection, and humor, requiring complex synthesis strategies. We find SynthesizRR greatly improves lexical and semantic diversity, similarity to human-written text, and distillation performance, when compared to standard 32-shot prompting and six baseline approaches.
Benchmarking datasets for Anomaly-based Network Intrusion Detection: KDD CUP 99 alternatives
Nov 13, 2018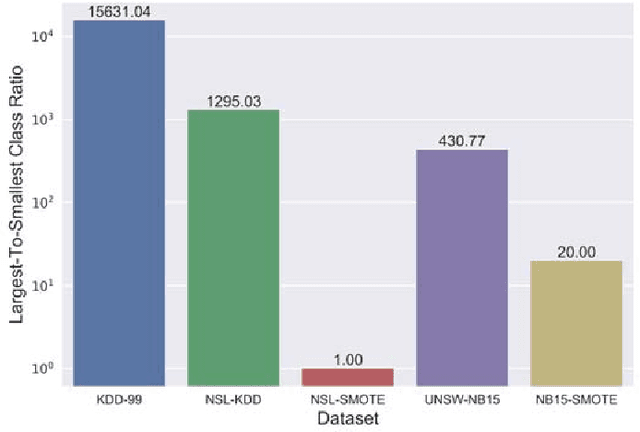
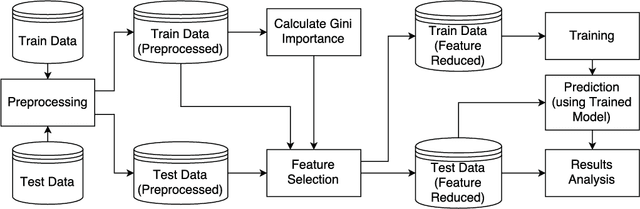
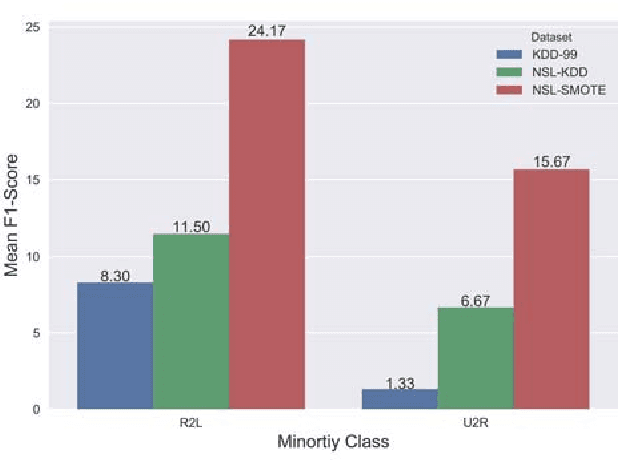
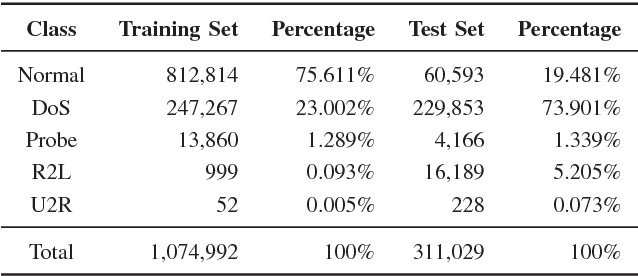
Machine Learning has been steadily gaining traction for its use in Anomaly-based Network Intrusion Detection Systems (A-NIDS). Research into this domain is frequently performed using the KDD~CUP~99 dataset as a benchmark. Several studies question its usability while constructing a contemporary NIDS, due to the skewed response distribution, non-stationarity, and failure to incorporate modern attacks. In this paper, we compare the performance for KDD-99 alternatives when trained using classification models commonly found in literature: Neural Network, Support Vector Machine, Decision Tree, Random Forest, Naive Bayes and K-Means. Applying the SMOTE oversampling technique and random undersampling, we create a balanced version of NSL-KDD and prove that skewed target classes in KDD-99 and NSL-KDD hamper the efficacy of classifiers on minority classes (U2R and R2L), leading to possible security risks. We explore UNSW-NB15, a modern substitute to KDD-99 with greater uniformity of pattern distribution. We benchmark this dataset before and after SMOTE oversampling to observe the effect on minority performance. Our results indicate that classifiers trained on UNSW-NB15 match or better the Weighted F1-Score of those trained on NSL-KDD and KDD-99 in the binary case, thus advocating UNSW-NB15 as a modern substitute to these datasets.