 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplied Machine Learning for Games: A Graduate School Course
Jan 01, 2021

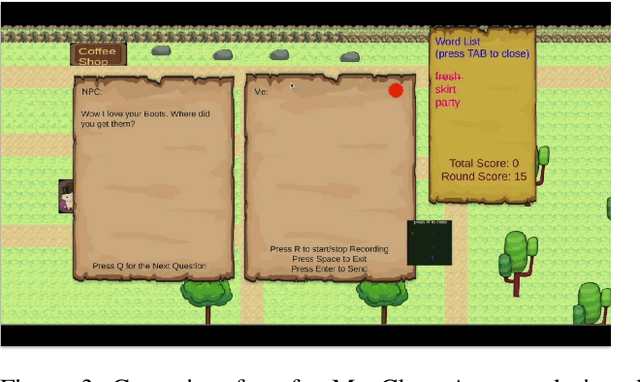
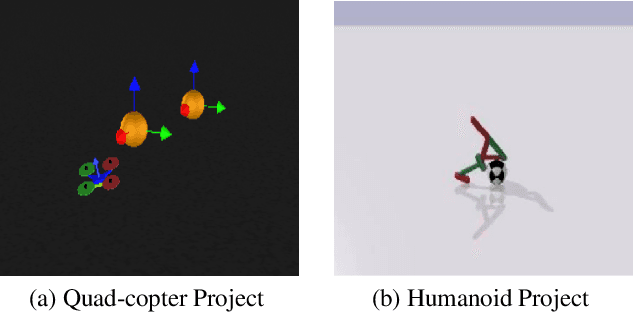
The game industry is moving into an era where old-style game engines are being replaced by re-engineered systems with embedded machine learning technologies for the operation, analysis and understanding of game play. In this paper, we describe our machine learning course designed for graduate students interested in applying recent advances of deep learning and reinforcement learning towards gaming. This course serves as a bridge to foster interdisciplinary collaboration among graduate schools and does not require prior experience designing or building games. Graduate students enrolled in this course apply different fields of machine learning techniques such as computer vision, natural language processing, computer graphics, human computer interaction, robotics and data analysis to solve open challenges in gaming. Student projects cover use-cases such as training AI-bots in gaming benchmark environments and competitions, understanding human decision patterns in gaming, and creating intelligent non-playable characters or environments to foster engaging gameplay. Projects demos can help students open doors for an industry career, aim for publications, or lay the foundations of a future product. Our students gained hands-on experience in applying state of the art machine learning techniques to solve real-life problems in gaming.
Learning to Reason in Round-based Games: Multi-task Sequence Generation for Purchasing Decision Making in First-person Shooters
Aug 12, 2020
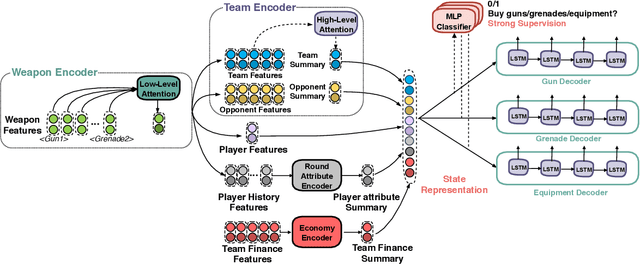

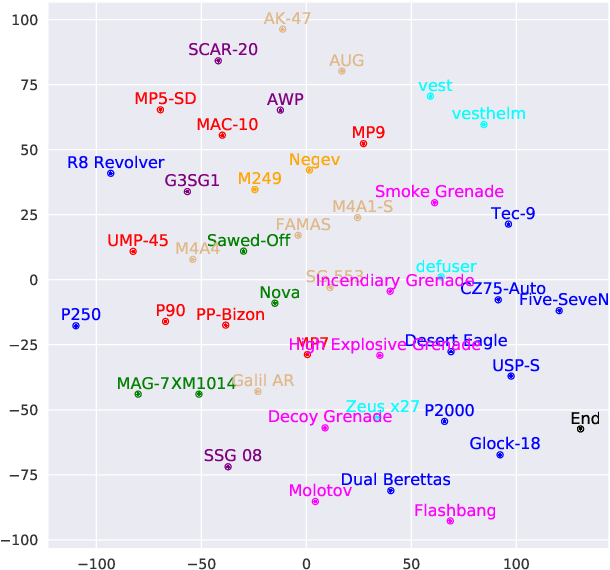
Sequential reasoning is a complex human ability, with extensive previous research focusing on gaming AI in a single continuous game, round-based decision makings extending to a sequence of games remain less explored. Counter-Strike: Global Offensive (CS:GO), as a round-based game with abundant expert demonstrations, provides an excellent environment for multi-player round-based sequential reasoning. In this work, we propose a Sequence Reasoner with Round Attribute Encoder and Multi-Task Decoder to interpret the strategies behind the round-based purchasing decisions. We adopt few-shot learning to sample multiple rounds in a match, and modified model agnostic meta-learning algorithm Reptile for the meta-learning loop. We formulate each round as a multi-task sequence generation problem. Our state representations combine action encoder, team encoder, player features, round attribute encoder, and economy encoders to help our agent learn to reason under this specific multi-player round-based scenario. A complete ablation study and comparison with the greedy approach certify the effectiveness of our model. Our research will open doors for interpretable AI for understanding episodic and long-term purchasing strategies beyond the gaming community.