 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Reason in Round-based Games: Multi-task Sequence Generation for Purchasing Decision Making in First-person Shooters
Aug 12, 2020
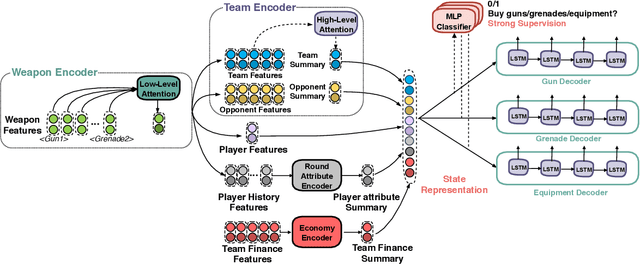

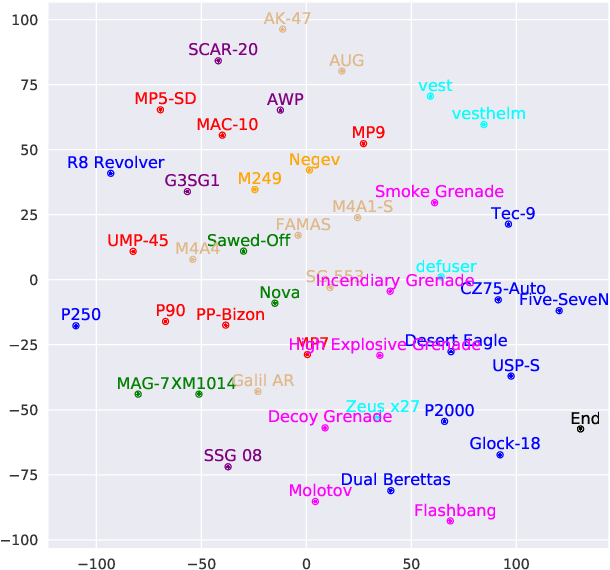
Sequential reasoning is a complex human ability, with extensive previous research focusing on gaming AI in a single continuous game, round-based decision makings extending to a sequence of games remain less explored. Counter-Strike: Global Offensive (CS:GO), as a round-based game with abundant expert demonstrations, provides an excellent environment for multi-player round-based sequential reasoning. In this work, we propose a Sequence Reasoner with Round Attribute Encoder and Multi-Task Decoder to interpret the strategies behind the round-based purchasing decisions. We adopt few-shot learning to sample multiple rounds in a match, and modified model agnostic meta-learning algorithm Reptile for the meta-learning loop. We formulate each round as a multi-task sequence generation problem. Our state representations combine action encoder, team encoder, player features, round attribute encoder, and economy encoders to help our agent learn to reason under this specific multi-player round-based scenario. A complete ablation study and comparison with the greedy approach certify the effectiveness of our model. Our research will open doors for interpretable AI for understanding episodic and long-term purchasing strategies beyond the gaming community.
Learning Collaborative Agents with Rule Guidance for Knowledge Graph Reasoning
May 01, 2020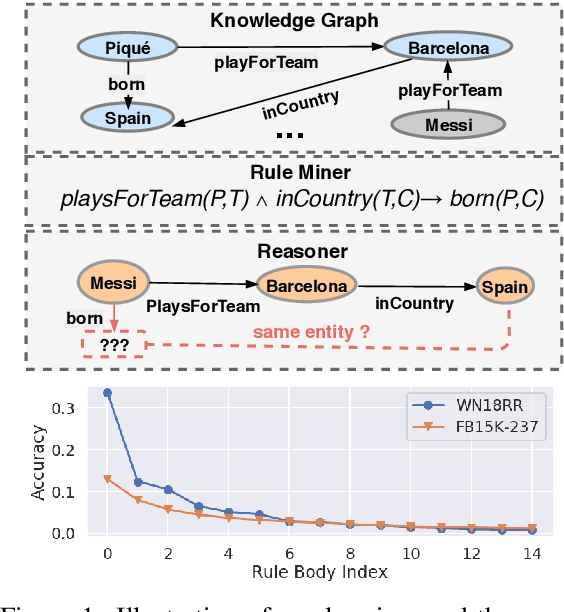
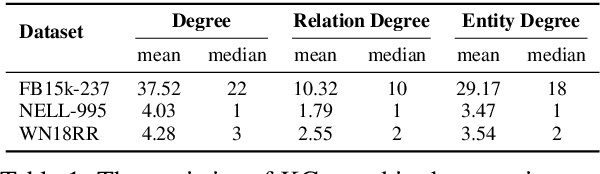
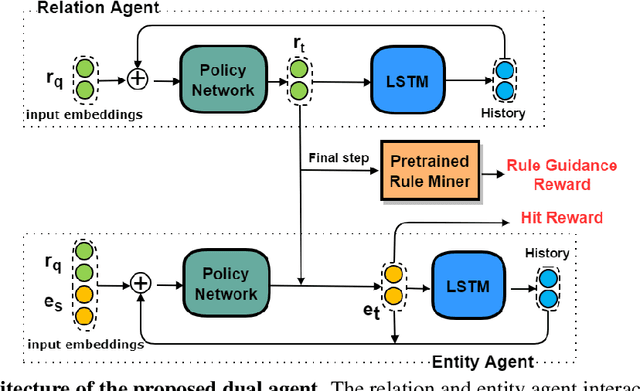
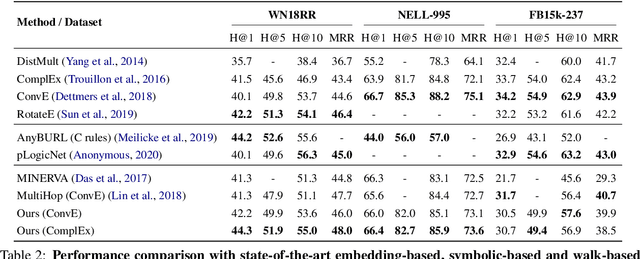
Walk-based models have shown their unique advantages in knowledge graph (KG) reasoning by achieving state-of-the-art performance while allowing for explicit visualization of the decision sequence. However, the sparse reward signals offered by the KG during a traversal are often insufficient to guide a sophisticated reinforcement learning (RL) model. An alternate approach to KG reasoning is using traditional symbolic methods (e.g., rule induction), which achieve high precision without learning but are hard to generalize due to the limitation of symbolic representation. In this paper, we propose to fuse these two paradigms to get the best of both worlds. Our method leverages high-quality rules generated by symbolic-based methods to provide reward supervision for walk-based agents. Due to the structure of symbolic rules with their entity variables, we can separate our walk-based agent into two sub-agents thus allowing for additional efficiency. Experiments on public datasets demonstrate that walk-based models can benefit from rule guidance significantly.