 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeptide-GPT: Generative Design of Peptides using Generative Pre-trained Transformers and Bio-informatic Supervision
Paper and Code
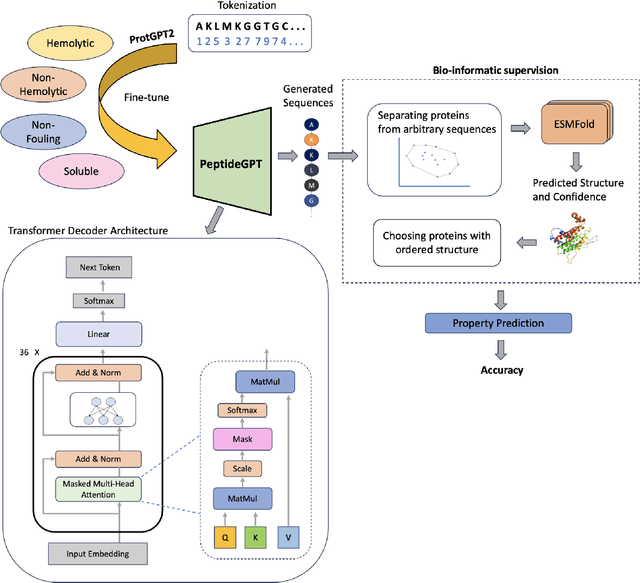

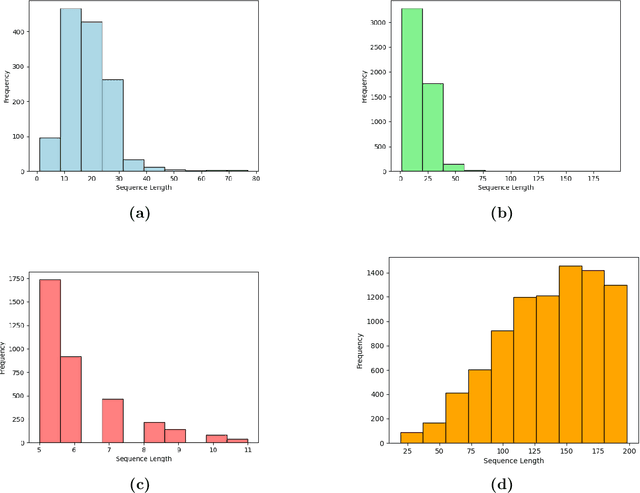

In recent years, natural language processing (NLP) models have demonstrated remarkable capabilities in various domains beyond traditional text generation. In this work, we introduce PeptideGPT, a protein language model tailored to generate protein sequences with distinct properties: hemolytic activity, solubility, and non-fouling characteristics. To facilitate a rigorous evaluation of these generated sequences, we established a comprehensive evaluation pipeline consisting of ideas from bioinformatics to retain valid proteins with ordered structures. First, we rank the generated sequences based on their perplexity scores, then we filter out those lying outside the permissible convex hull of proteins. Finally, we predict the structure using ESMFold and select the proteins with pLDDT values greater than 70 to ensure ordered structure. The properties of generated sequences are evaluated using task-specific classifiers - PeptideBERT and HAPPENN. We achieved an accuracy of 76.26% in hemolytic, 72.46% in non-hemolytic, 78.84% in non-fouling, and 68.06% in solubility protein generation. Our experimental results demonstrate the effectiveness of PeptideGPT in de novo protein design and underscore the potential of leveraging NLP-based approaches for paving the way for future innovations and breakthroughs in synthetic biology and bioinformatics. Codes, models, and data used in this study are freely available at: https://github.com/aayush-shah14/PeptideGPT.